Semi-Supervised Cross-Domain Imitation Learning
作者: Li-Min Chu, Kai-Siang Ma, Ming-Hong Chen, Ping-Chun Hsieh
分类: cs.LG, cs.RO
发布日期: 2026-02-11
备注: Published in Transactions on Machine Learning Research (TMLR)
🔗 代码/项目: GITHUB
💡 一句话要点
提出半监督跨域模仿学习算法,解决专家数据稀缺问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 跨域模仿学习 半监督学习 强化学习 机器人控制 域适应
📋 核心要点
- 现有跨域模仿学习方法依赖大量标注或易出现训练不稳定,限制了其在专家数据稀缺场景的应用。
- 提出半监督跨域模仿学习框架,利用少量目标域专家数据和大量未标注轨迹,提升学习效率和稳定性。
- 实验结果表明,该方法在MuJoCo和Robosuite环境中优于现有基线,实现了数据高效的策略学习。
📝 摘要(中文)
本文提出半监督跨域模仿学习(SS-CDIL)设定,旨在通过跨域迁移专家知识加速策略学习,解决专家数据收集成本高昂的问题。现有方法要么是有监督的,依赖代理任务和显式对齐,要么是无监督的,在没有配对数据的情况下对齐分布,但通常不稳定。我们提出了首个针对SS-CDIL的算法,并提供了理论证明。该方法仅使用离线数据,包括少量目标领域专家演示和一些未标记的不完美轨迹。为了处理域差异,我们提出了一种新颖的跨域损失函数,用于学习域间状态-动作映射,并设计了一种自适应权重函数来平衡源域和目标域的知识。在MuJoCo和Robosuite上的实验表明,该方法相对于基线方法具有持续的优势,证明了我们的方法能够以最小的监督实现稳定和数据高效的策略学习。代码已开源。
🔬 方法详解
问题定义:论文旨在解决跨域模仿学习中,目标域专家数据稀缺的问题。现有的跨域模仿学习方法要么需要大量的配对数据进行监督学习,要么依赖复杂的无监督对齐方法,这些方法通常训练不稳定,且对超参数敏感。因此,如何在少量目标域专家数据和大量未标注数据的情况下,有效地进行跨域知识迁移是一个挑战。
核心思路:论文的核心思路是利用半监督学习的思想,结合少量目标域专家数据和大量未标注的轨迹数据,学习一个跨域的状态-动作映射。通过这种方式,可以有效地利用源域的知识,同时避免了完全依赖目标域专家数据带来的数据稀缺问题。此外,通过自适应权重函数平衡源域和目标域的知识,进一步提升了学习的稳定性和效率。
技术框架:该方法主要包含以下几个模块:1) 跨域状态-动作映射学习模块:利用跨域损失函数学习源域和目标域之间的状态-动作映射关系。2) 自适应权重函数模块:根据源域和目标域数据的质量,动态调整源域和目标域知识的权重。3) 策略学习模块:利用学习到的状态-动作映射和自适应权重,训练目标域的策略。整体流程是,首先利用跨域损失函数和自适应权重函数学习状态-动作映射,然后利用学习到的映射和权重,训练目标域的策略。
关键创新:论文的关键创新在于提出了半监督跨域模仿学习的设定,并设计了相应的算法。具体来说,提出了一个新颖的跨域损失函数,用于学习域间状态-动作映射,并设计了一个自适应权重函数来平衡源域和目标域的知识。与现有方法相比,该方法能够有效地利用少量目标域专家数据和大量未标注数据,实现稳定和数据高效的策略学习。
关键设计:跨域损失函数的设计是关键,它需要能够有效地衡量源域和目标域之间的状态-动作差异。自适应权重函数的设计也至关重要,它需要能够根据源域和目标域数据的质量,动态调整源域和目标域知识的权重。具体的损失函数和权重函数的形式在论文中进行了详细的描述。网络结构方面,可以使用常见的神经网络结构,如多层感知机或循环神经网络。
🖼️ 关键图片

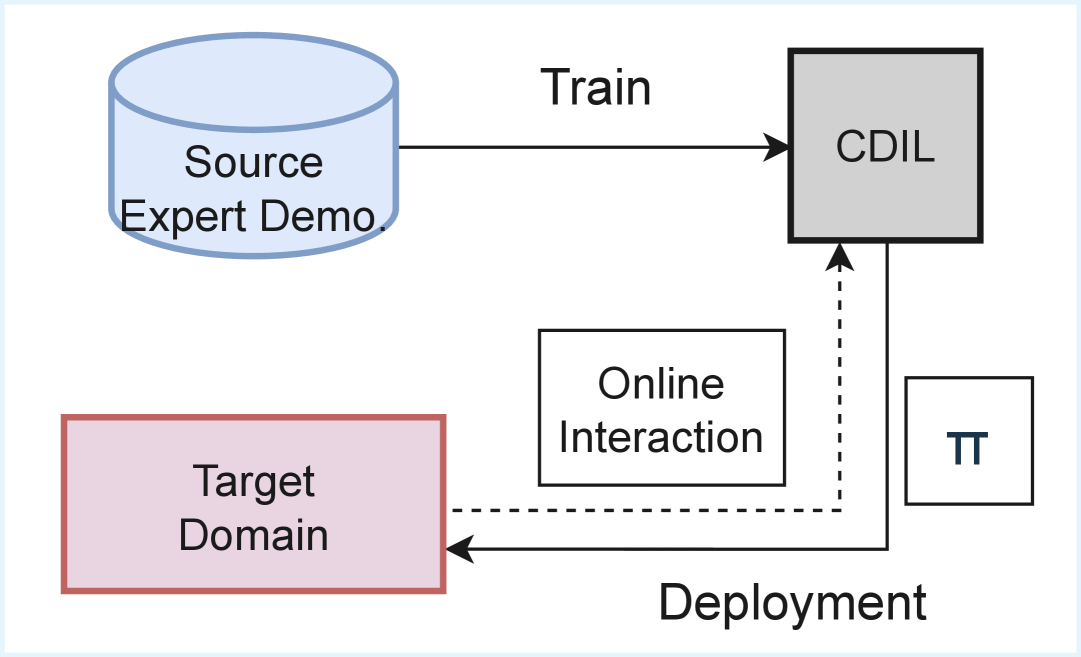
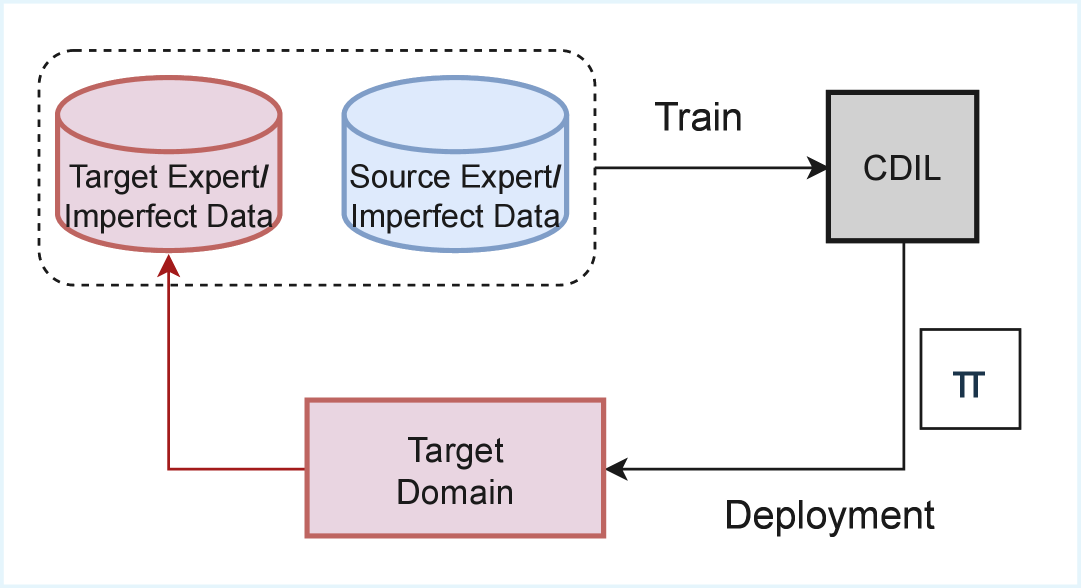
📊 实验亮点
实验结果表明,该方法在MuJoCo和Robosuite环境中,相对于基线方法具有显著的性能提升。具体来说,在多个任务中,该方法能够以更少的目标域专家数据,达到与现有方法相当甚至更好的性能。此外,该方法还表现出更好的稳定性和鲁棒性,能够有效地处理域差异带来的挑战。这些结果表明,该方法是一种有效且实用的半监督跨域模仿学习方法。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶等领域。在这些领域中,获取目标环境的专家数据往往成本高昂或难以实现。通过利用该方法,可以利用其他环境或模拟环境中的数据,结合少量目标环境的专家数据,快速训练出高性能的控制策略,降低开发成本,加速产品落地。未来,该方法还可以扩展到更复杂的跨域场景,例如从游戏数据迁移到真实世界。
📄 摘要(原文)
Cross-domain imitation learning (CDIL) accelerates policy learning by transferring expert knowledge across domains, which is valuable in applications where the collection of expert data is costly. Existing methods are either supervised, relying on proxy tasks and explicit alignment, or unsupervised, aligning distributions without paired data, but often unstable. We introduce the Semi-Supervised CDIL (SS-CDIL) setting and propose the first algorithm for SS-CDIL with theoretical justification. Our method uses only offline data, including a small number of target expert demonstrations and some unlabeled imperfect trajectories. To handle domain discrepancy, we propose a novel cross-domain loss function for learning inter-domain state-action mappings and design an adaptive weight function to balance the source and target knowledge. Experiments on MuJoCo and Robosuite show consistent gains over the baselines, demonstrating that our approach achieves stable and data-efficient policy learning with minimal supervision. Our code is available at~ https://github.com/NYCU-RL-Bandits-Lab/CDIL.