Kalman Linear Attention: Parallel Bayesian Filtering For Efficient Language Modelling and State Tracking
作者: Vaisakh Shaj, Cameron Barker, Aidan Scannell, Andras Szecsenyi, Elliot J. Crowley, Amos Storkey
分类: cs.LG
发布日期: 2026-02-11
备注: Preprint. A version of this work was accepted and presented at the 1st Workshop on Epistemic Intelligence in Machine Learning (EIML) at EurIPS 2025
💡 一句话要点
提出Kalman线性注意力(KLA),通过并行贝叶斯滤波实现高效语言建模和状态跟踪。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 卡尔曼滤波 线性注意力 状态空间模型 序列建模 并行计算 贝叶斯滤波 语言建模 概率推理
📋 核心要点
- 现有状态空间模型和门控线性注意力模型在复杂推理中缺乏足够的表达性和鲁棒的状态跟踪能力。
- 论文核心思想是将序列建模问题转化为概率推理问题,并利用信息形式的卡尔曼滤波器实现并行更新。
- 实验结果表明,提出的KLA层在语言建模任务中,性能与现有先进的状态空间模型和门控线性注意力模型相当甚至更优。
📝 摘要(中文)
本文针对现有状态空间语言模型(如Mamba和门控线性注意力GLA)在复杂推理中缺乏表达性和鲁棒状态跟踪的问题,提出了一种新的序列建模方法。该方法将序列建模重新定义为概率问题,并使用贝叶斯滤波器作为核心原语。虽然传统的卡尔曼滤波器提供了可靠的状态估计和不确定性跟踪,但它们通常被认为是顺序的。本文证明,通过信息形式重新参数化卡尔曼滤波器,可以利用结合律扫描并行计算更新,从而实现高效的并行训练。基于此,本文引入了卡尔曼线性注意力(KLA)层,这是一种神经序列建模原语,可在保持显式置信状态不确定性的同时执行时间并行的概率推理。KLA提供了比GLA变体更具表现力的非线性更新和门控,同时保留了它们的计算优势。在语言建模任务中,KLA在代表性的离散token操作和状态跟踪基准测试中与现代SSM和GLA相匹配或优于它们。
🔬 方法详解
问题定义:现有状态空间模型(SSM)和门控线性注意力(GLA)模型虽然具有线性复杂度和并行训练的优点,但在处理需要复杂推理的任务时,其表达能力和状态跟踪的鲁棒性不足。这些模型难以准确地维护和更新状态信息,导致在长序列或复杂依赖关系中性能下降。
核心思路:论文的核心思路是将序列建模问题视为一个概率推理问题,并利用贝叶斯滤波框架,特别是卡尔曼滤波器,来进行状态估计和更新。通过将卡尔曼滤波器重新参数化为信息形式,使其更新可以通过结合律扫描并行计算,从而克服了传统卡尔曼滤波器的顺序计算瓶颈。这种方法允许模型在并行训练的同时,显式地跟踪状态的不确定性。
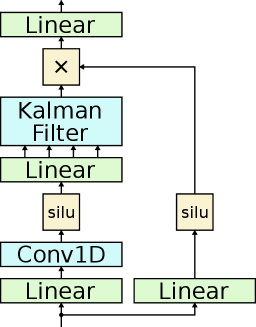
技术框架:KLA层的整体框架基于卡尔曼滤波器的信息形式。输入序列首先经过线性变换,然后输入到KLA层进行处理。KLA层内部执行以下步骤:1) 将输入转换为卡尔曼滤波器的参数(例如,观测矩阵、状态转移矩阵等);2) 使用信息形式的卡尔曼滤波器进行状态更新,该更新通过并行扫描操作实现;3) 从更新后的状态中提取信息,并将其传递到下一层。整个过程可以看作是一个时间并行的概率推理过程。
关键创新:最重要的技术创新点在于将卡尔曼滤波器重新参数化为信息形式,并利用结合律扫描实现并行更新。这使得KLA层能够在保持卡尔曼滤波器状态估计和不确定性跟踪优势的同时,实现高效的并行训练。与现有的GLA模型相比,KLA提供了更具表达能力的非线性更新和门控机制。
关键设计:KLA层的关键设计包括:1) 使用信息形式的卡尔曼滤波器,这允许通过结合律扫描进行并行更新;2) 使用神经网络学习卡尔曼滤波器的参数,例如观测矩阵、状态转移矩阵等;3) 引入门控机制,以控制状态更新的强度和方向;4) 损失函数的设计需要考虑状态估计的准确性和不确定性的合理性。具体参数设置和网络结构的选择取决于具体的应用场景和数据集。
🖼️ 关键图片

📊 实验亮点
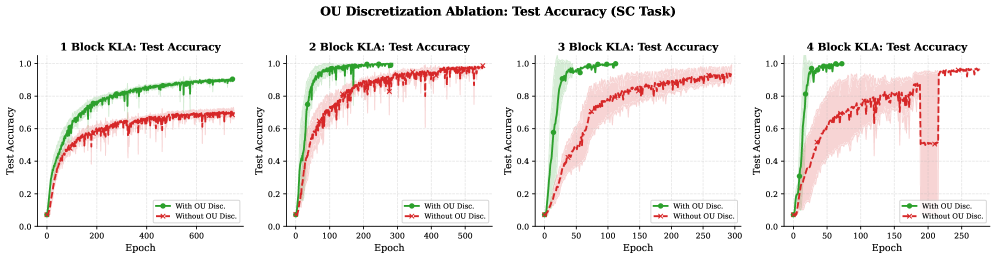
实验结果表明,KLA在语言建模任务中与现代SSM和GLA模型相匹配或优于它们。在离散token操作和状态跟踪基准测试中,KLA展现了强大的性能。例如,在某些任务上,KLA的困惑度(perplexity)比基线模型降低了显著的百分比,表明其能够更准确地预测序列中的下一个token。
🎯 应用场景
KLA具有广泛的应用前景,包括自然语言处理、语音识别、时间序列预测和机器人控制等领域。其高效的并行训练能力和鲁棒的状态跟踪能力使其特别适用于处理长序列和复杂依赖关系的任务。例如,在对话系统中,KLA可以用于跟踪对话状态,从而提高对话的流畅性和准确性。在机器人控制中,KLA可以用于估计机器人的状态和环境,从而实现更精确的控制。
📄 摘要(原文)
State-space language models such as Mamba and gated linear attention (GLA) offer efficient alternatives to transformers due to their linear complexity and parallel training, but often lack the expressivity and robust state-tracking needed for complex reasoning. We address these limitations by reframing sequence modelling through a probabilistic lens, using Bayesian filters as a core primitive. While classical filters such as Kalman filters provide principled state estimation and uncertainty tracking, they are typically viewed as inherently sequential. We show that reparameterising the Kalman filter in information form enables its updates to be computed via an associative scan, allowing efficient parallel training. Building on this insight, we introduce the Kalman Linear Attention (KLA) layer, a neural sequence-modelling primitive that performs time-parallel probabilistic inference while maintaining explicit belief-state uncertainty. KLA offers strictly more expressive nonlinear updates and gating than GLA variants while retaining their computational advantages. On language modelling tasks, KLA matches or outperforms modern SSMs and GLAs across representative discrete token-manipulation and state-tracking benchmarks.