VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
作者: Guobin Shen, Chenxiao Zhao, Xiang Cheng, Lei Huang, Xing Yu
分类: cs.LG, cs.AI
发布日期: 2026-02-11
🔗 代码/项目: GITHUB
💡 一句话要点
VESPO:变分序列级软策略优化,用于稳定的大语言模型离线训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 离线训练 重要性采样 变分推断
📋 核心要点
- 现有大语言模型强化学习训练方法受策略陈旧、异步训练等因素影响,训练过程不稳定,容易崩溃。
- VESPO通过变分推断,导出一个闭式重塑核,直接作用于序列级别的重要性权重,减少方差。
- 实验表明,VESPO在策略陈旧和异步执行情况下保持训练稳定,并在数学推理任务上取得了显著提升。
📝 摘要(中文)
大语言模型(LLM)强化学习(RL)训练的稳定性仍然是一个核心挑战。策略陈旧、异步训练以及训练和推理引擎之间的不匹配都会导致行为策略偏离当前策略,从而导致训练崩溃。重要性采样为这种分布偏移提供了一种原则性的校正方法,但存在高方差问题;现有的补救措施,如token级别裁剪和序列级别归一化,缺乏统一的理论基础。我们提出了变分序列级软策略优化(VESPO)。通过将方差减少纳入提案分布的变分公式中,VESPO推导出直接作用于序列级别重要性权重的闭式重塑核,而无需长度归一化。在数学推理基准上的实验表明,VESPO在高达64倍的陈旧率和完全异步执行下保持稳定的训练,并在密集模型和混合专家模型中提供一致的增益。
🔬 方法详解
问题定义:论文旨在解决大语言模型离线强化学习训练中,由于策略陈旧、异步训练等因素导致的训练不稳定问题。现有方法,如token级别裁剪和序列级别归一化,缺乏统一的理论基础,且难以有效降低重要性采样带来的高方差。
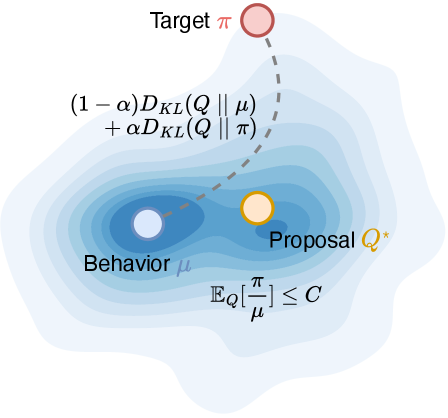
核心思路:VESPO的核心思路是将方差减少纳入提案分布的变分公式中。通过变分推断,寻找一个最优的提案分布,从而降低重要性采样的方差,提高训练的稳定性。这种方法避免了直接对重要性权重进行裁剪或归一化,而是通过优化提案分布来间接控制权重。
技术框架:VESPO的整体框架包括以下几个步骤:1)收集离线数据,包括状态、动作、奖励等;2)使用行为策略生成提案分布;3)使用变分推断优化提案分布,得到重塑核;4)使用重塑核调整重要性权重;5)使用调整后的重要性权重更新策略。
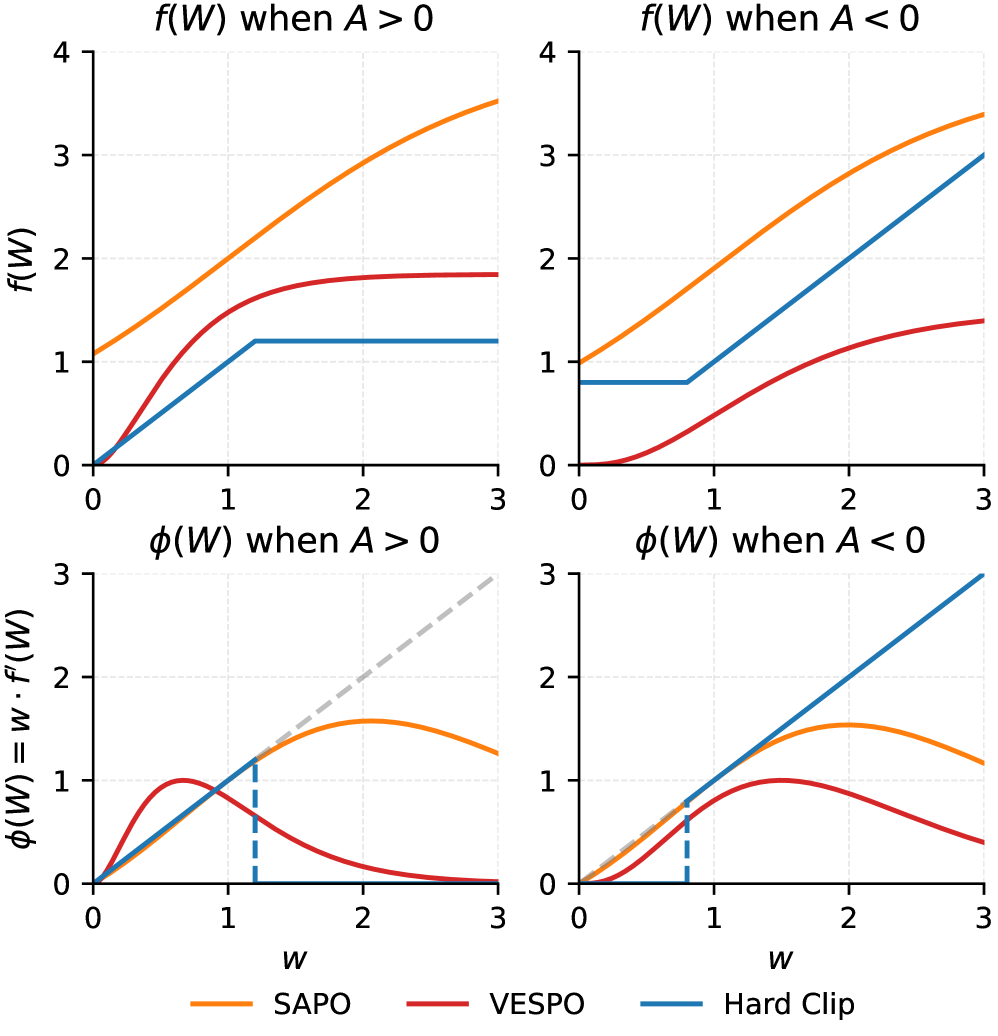
关键创新:VESPO最重要的技术创新在于提出了一个闭式解的重塑核,可以直接作用于序列级别的重要性权重。这个重塑核是通过变分推断得到的,可以有效地降低重要性采样的方差,从而提高训练的稳定性。与现有方法相比,VESPO具有更强的理论基础和更好的性能。
关键设计:VESPO的关键设计包括:1)使用变分推断来优化提案分布;2)导出一个闭式解的重塑核;3)在序列级别上调整重要性权重。论文中没有明确提及具体的网络结构或损失函数,但可以推断其使用了标准的强化学习训练流程,并在此基础上集成了VESPO方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VESPO在数学推理基准上表现出色,即使在高达64倍的策略陈旧率和完全异步执行的情况下,也能保持稳定的训练。此外,VESPO在密集模型和混合专家模型中都取得了显著的性能提升,证明了其通用性和有效性。
🎯 应用场景
VESPO可以应用于各种需要离线强化学习训练的大语言模型场景,例如对话生成、文本摘要、代码生成等。该方法可以提高训练的稳定性和效率,降低训练成本,并提升模型的性能。未来,VESPO可以进一步扩展到其他类型的序列生成任务中。
📄 摘要(原文)
Training stability remains a central challenge in reinforcement learning (RL) for large language models (LLMs). Policy staleness, asynchronous training, and mismatches between training and inference engines all cause the behavior policy to diverge from the current policy, risking training collapse. Importance sampling provides a principled correction for this distribution shift but suffers from high variance; existing remedies such as token-level clipping and sequence-level normalization lack a unified theoretical foundation. We propose Variational sEquence-level Soft Policy Optimization (VESPO). By incorporating variance reduction into a variational formulation over proposal distributions, VESPO derives a closed-form reshaping kernel that operates directly on sequence-level importance weights without length normalization. Experiments on mathematical reasoning benchmarks show that VESPO maintains stable training under staleness ratios up to 64x and fully asynchronous execution, and delivers consistent gains across both dense and Mixture-of-Experts models. Code is available at https://github.com/FloyedShen/VESPO