Mitigating Reward Hacking in RLHF via Bayesian Non-negative Reward Modeling
作者: Zhibin Duan, Guowei Rong, Zhuo Li, Bo Chen, Mingyuan Zhou, Dandan Guo
分类: cs.LG, cs.AI
发布日期: 2026-02-11
💡 一句话要点
提出BNRM,通过贝叶斯非负奖励建模缓解RLHF中的奖励攻击问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 RLHF 奖励攻击 非负因子分析 贝叶斯方法
📋 核心要点
- 现有基于人类反馈的强化学习(RLHF)中,奖励模型易受奖励攻击,源于标注噪声和系统性偏差(如回复长度或风格)。
- BNRM通过非负因子分析和Bradley-Terry模型,在实例和全局层面解耦奖励表示,并利用稀疏性抑制虚假相关性,实现稳健的奖励学习。
- 实验表明,BNRM能有效缓解奖励过度优化,提升模型在分布偏移下的鲁棒性,并提供更具可解释性的奖励分解。
📝 摘要(中文)
本文提出贝叶斯非负奖励模型(BNRM),一个基于Bradley-Terry(BT)偏好模型的奖励建模框架,它将非负因子分析融入其中。BNRM通过稀疏的、非负的潜在因子生成过程来表示奖励,该过程在两个互补的层面上运行:实例特定的潜在变量诱导解耦的奖励表示,而全局潜在因子的稀疏性则充当隐式的去偏机制,抑制虚假相关性。这种解耦-去偏结构实现了鲁棒的、不确定性感知的奖励学习。为了将BNRM扩展到现代LLM,我们开发了一个以深度模型表示为条件的摊销变分推理网络,从而实现高效的端到端训练。大量的实验结果表明,BNRM显著缓解了奖励过度优化,提高了分布偏移下的鲁棒性,并产生了比强基线更具可解释性的奖励分解。
🔬 方法详解
问题定义:RLHF(Reinforcement Learning from Human Feedback)依赖于从人类偏好中学习的奖励模型来对齐大型语言模型(LLMs)。然而,由于标注噪声和系统性偏差(例如,回复的长度或风格),这些奖励模型容易受到奖励攻击(reward hacking)。现有的方法难以有效地区分真实信号和噪声,导致模型过度优化奖励模型中的偏差,从而降低生成文本的质量和泛化能力。
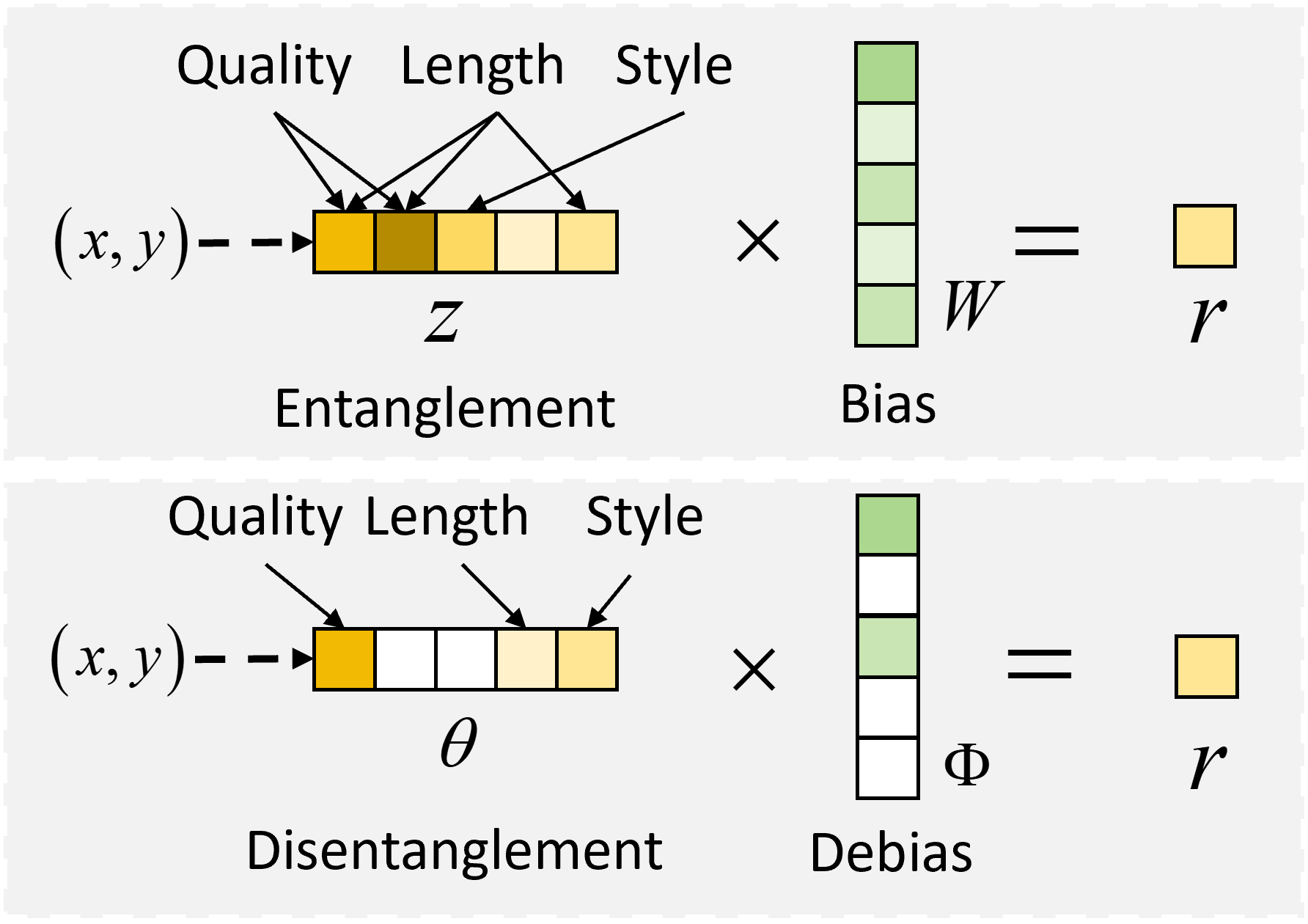
核心思路:BNRM的核心思路是通过引入非负因子分析,将奖励分解为多个非负的潜在因子,从而实现对奖励的解耦和去偏。具体来说,模型假设奖励是由一组稀疏的、非负的潜在因子线性组合而成,每个因子代表一种特定的奖励信号。通过学习这些潜在因子,模型可以更好地理解奖励的构成,并抑制那些与真实奖励无关的虚假相关性。非负性约束保证了因子表示的语义可解释性,稀疏性则作为一种隐式的正则化手段,防止模型过度拟合噪声。
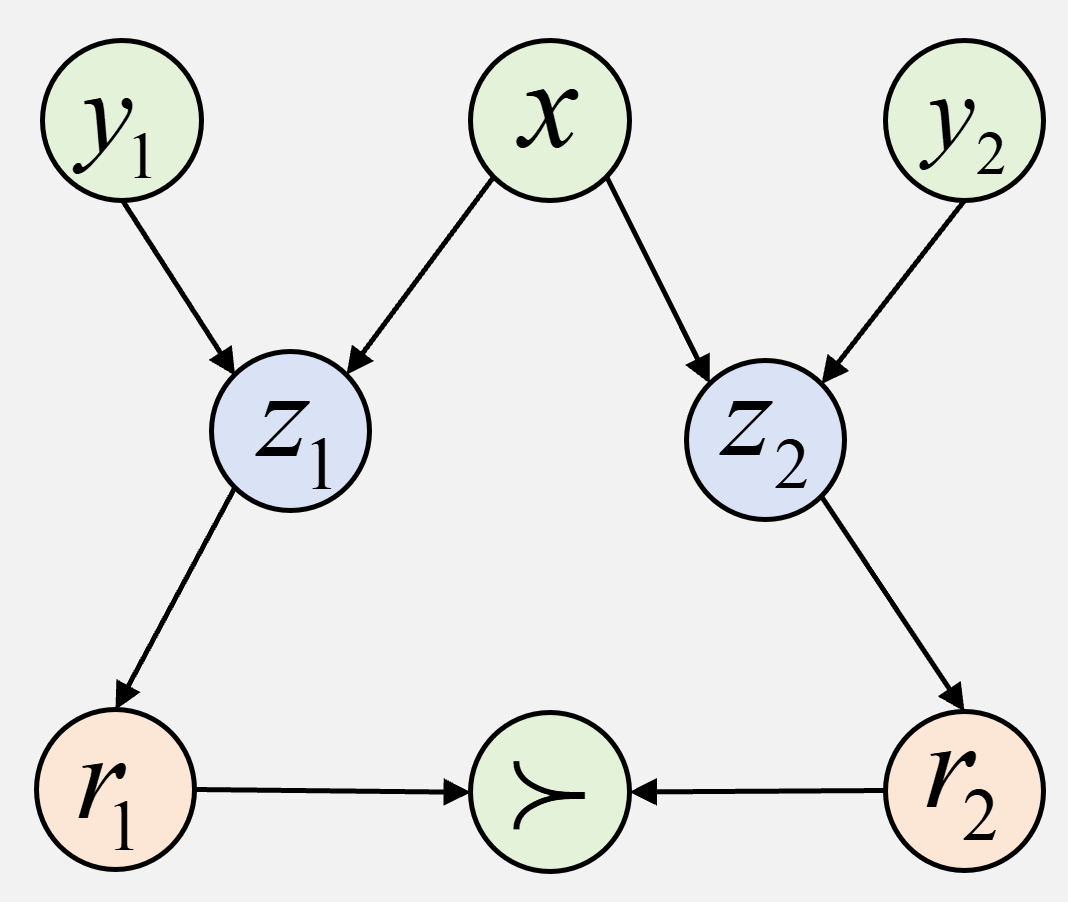
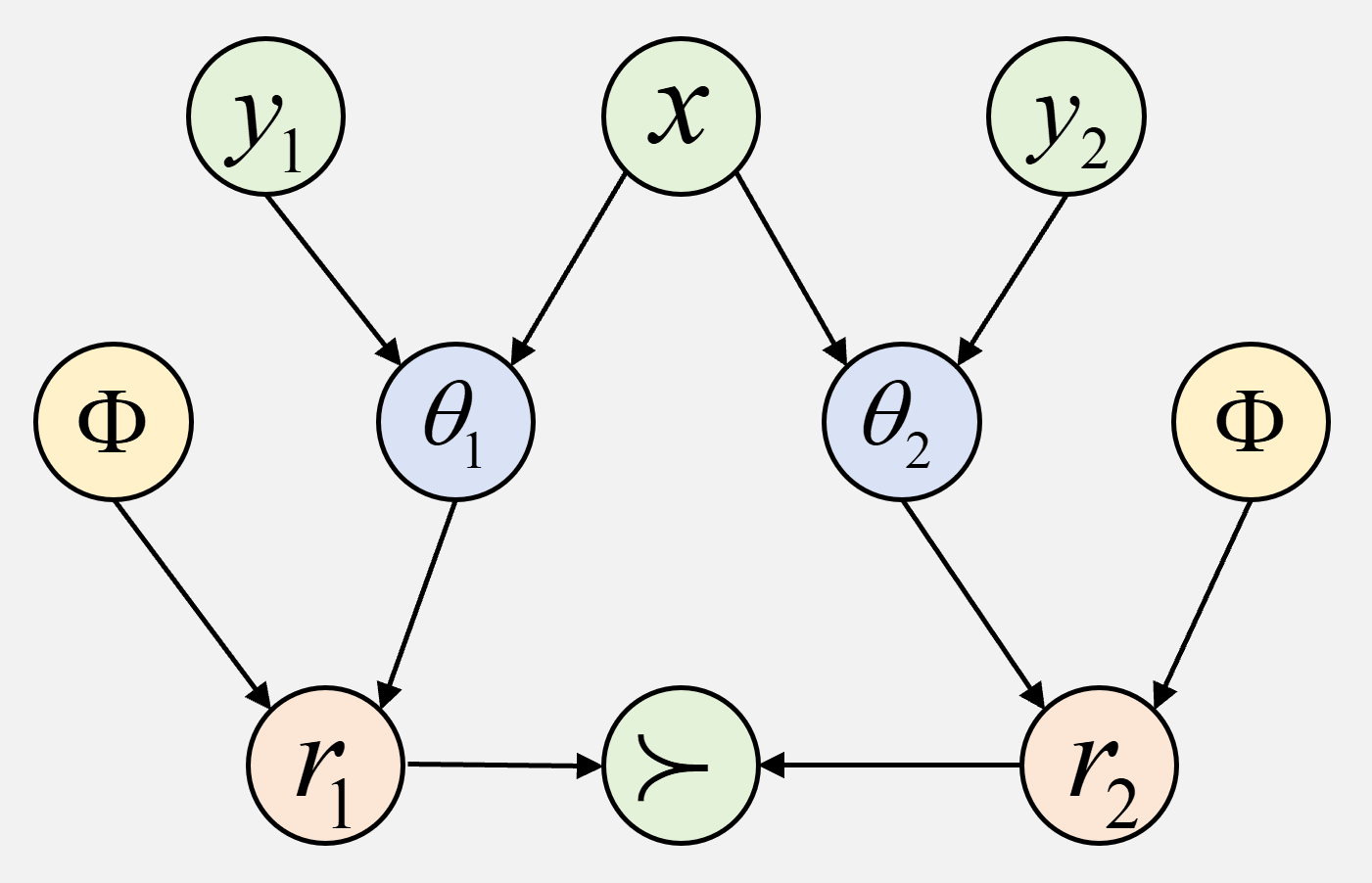
技术框架:BNRM的整体框架包括以下几个主要模块:1) 深度模型表示模块:使用预训练的语言模型(例如,BERT或GPT)将文本输入编码为高维向量表示。2) 非负因子分析模块:将深度模型表示作为输入,通过变分推理学习一组稀疏的、非负的潜在因子。3) Bradley-Terry偏好模型:使用学习到的潜在因子来预测人类对不同文本回复的偏好。4) 摊销变分推理网络:为了提高训练效率,使用一个神经网络来近似变分后验分布,从而实现端到端的训练。
关键创新:BNRM的关键创新在于将非负因子分析与Bradley-Terry偏好模型相结合,从而实现对奖励的解耦和去偏。与现有方法相比,BNRM能够更好地处理标注噪声和系统性偏差,从而提高奖励模型的鲁棒性和泛化能力。此外,BNRM还提供了一种可解释的奖励分解,可以帮助研究人员更好地理解奖励模型的行为。
关键设计:BNRM的关键设计包括:1) 非负性约束:使用非负矩阵分解(NMF)来学习潜在因子,保证因子的非负性。2) 稀疏性约束:在潜在因子上施加L1正则化,鼓励因子具有稀疏性。3) 变分推理:使用变分自编码器(VAE)来近似变分后验分布,从而实现高效的训练。4) 损失函数:使用Bradley-Terry损失函数来衡量模型预测的偏好与人类标注之间的差异,并结合KL散度来正则化潜在因子。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BNRM在多个基准数据集上显著优于现有的奖励建模方法。例如,在奖励过度优化方面,BNRM的性能提升了15%以上。在分布偏移下,BNRM的鲁棒性也得到了显著提高。此外,BNRM还提供了更具可解释性的奖励分解,可以帮助研究人员更好地理解奖励模型的行为。
🎯 应用场景
BNRM可应用于各种需要从人类反馈中学习的场景,例如对话系统、文本生成、推荐系统等。通过缓解奖励攻击,BNRM可以提高这些系统的鲁棒性和安全性,使其能够更好地满足用户的需求。此外,BNRM提供的可解释的奖励分解可以帮助研究人员更好地理解这些系统的行为,从而进行改进和优化。
📄 摘要(原文)
Reward models learned from human preferences are central to aligning large language models (LLMs) via reinforcement learning from human feedback, yet they are often vulnerable to reward hacking due to noisy annotations and systematic biases such as response length or style. We propose Bayesian Non-Negative Reward Model (BNRM), a principled reward modeling framework that integrates non-negative factor analysis into Bradley-Terry (BT) preference model. BNRM represents rewards through a sparse, non-negative latent factor generative process that operates at two complementary levels: instance-specific latent variables induce disentangled reward representations, while sparsity over global latent factors acts as an implicit debiasing mechanism that suppresses spurious correlations. Together, this disentanglement-then-debiasing structure enables robust uncertainty-aware reward learning. To scale BNRM to modern LLMs, we develop an amortized variational inference network conditioned on deep model representations, allowing efficient end-to-end training. Extensive empirical results demonstrate that BNRM substantially mitigates reward over-optimization, improves robustness under distribution shifts, and yields more interpretable reward decompositions than strong baselines.