dnaHNet: A Scalable and Hierarchical Foundation Model for Genomic Sequence Learning
作者: Arnav Shah, Junzhe Li, Parsa Idehpour, Adibvafa Fallahpour, Brandon Wang, Sukjun Hwang, Bo Wang, Patrick D. Hsu, Hani Goodarzi, Albert Gu
分类: cs.LG
发布日期: 2026-02-11
💡 一句话要点
提出dnaHNet:一种可扩展的分层基因组序列学习基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 基因组序列学习 基础模型 自回归模型 动态分块 长序列建模
📋 核心要点
- 现有基因组模型在处理长序列时面临计算成本高昂的问题,且固定词汇分词器会破坏生物学意义。
- dnaHNet通过可微动态分块机制,自适应地将核苷酸压缩为潜在token,平衡压缩与预测精度。
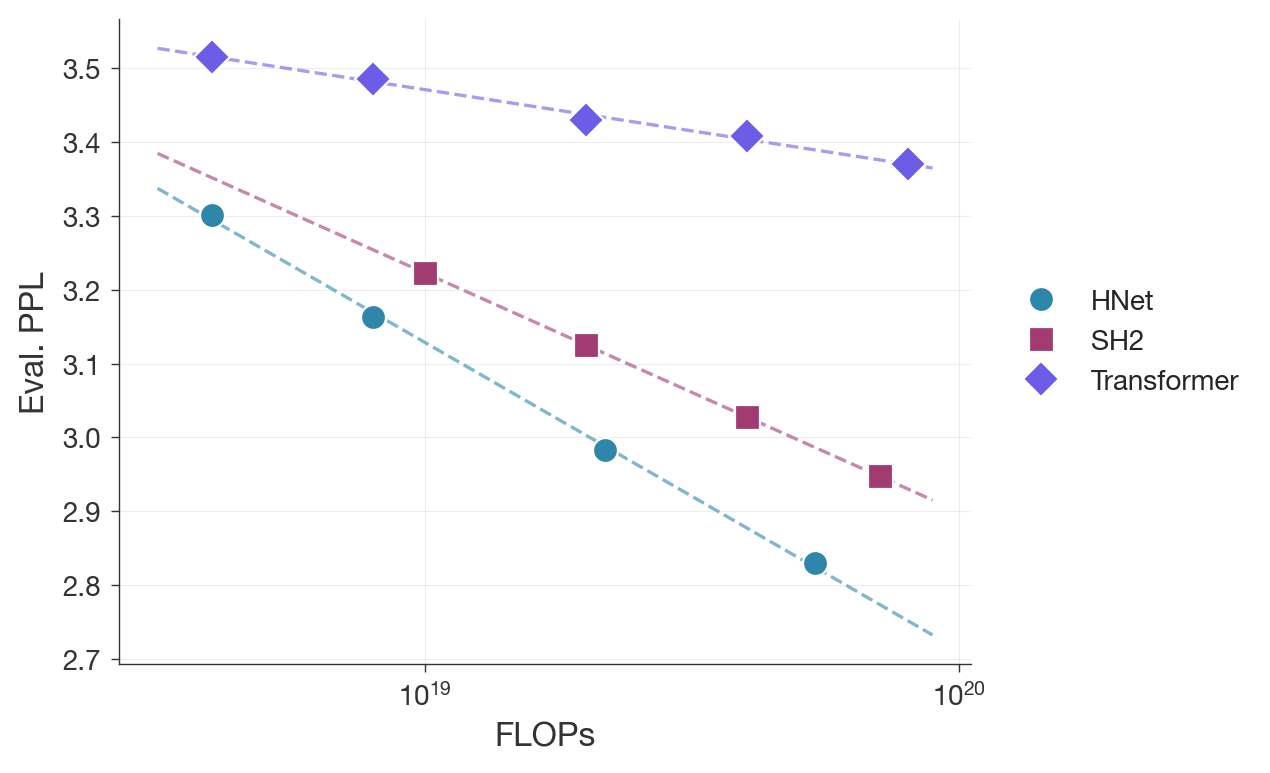
- 实验表明,dnaHNet在扩展性、效率和零样本任务上优于现有模型,并能自动发现分层生物结构。
📝 摘要(中文)
基因组基础模型有潜力解码DNA语法,但在输入表示方面面临根本性的权衡。标准的固定词汇分词器会分割生物学上有意义的motif,如密码子和调控元件,而核苷酸级别的模型虽然保留了生物学连贯性,但对于长上下文来说计算成本过高。我们引入了dnaHNet,一种最先进的无分词器自回归模型,可以端到端地分割和建模基因组序列。通过使用可微的动态分块机制,dnaHNet自适应地将原始核苷酸压缩为潜在的token,从而平衡了压缩和预测精度。在原核基因组上进行预训练后,dnaHNet在扩展性和效率方面优于包括StripedHyena2在内的领先架构。这种递归分块实现了二次FLOP减少,使得推理速度比Transformer快3倍以上。在零样本任务中,dnaHNet在预测蛋白质变异适应性和基因必需性方面取得了优异的性能,同时自动发现了分层的生物学结构,无需监督。这些结果表明dnaHNet是一个可扩展、可解释的下一代基因组建模框架。
🔬 方法详解
问题定义:基因组序列学习旨在理解DNA的语法和功能,但现有方法存在局限性。传统的固定词汇分词器会将生物学上重要的motif分割开,破坏了序列的生物学意义。而核苷酸级别的模型虽然能保留生物学连贯性,但对于长序列而言,计算复杂度过高,难以扩展到大规模基因组数据。因此,如何高效且准确地建模长基因组序列是一个关键问题。
核心思路:dnaHNet的核心思路是采用一种可微的动态分块机制,将原始核苷酸序列自适应地压缩成潜在的token。这种方法既保留了核苷酸级别的生物学信息,又通过压缩减少了序列长度,从而降低了计算复杂度。通过平衡压缩率和预测精度,dnaHNet能够在长序列上实现高效的建模。
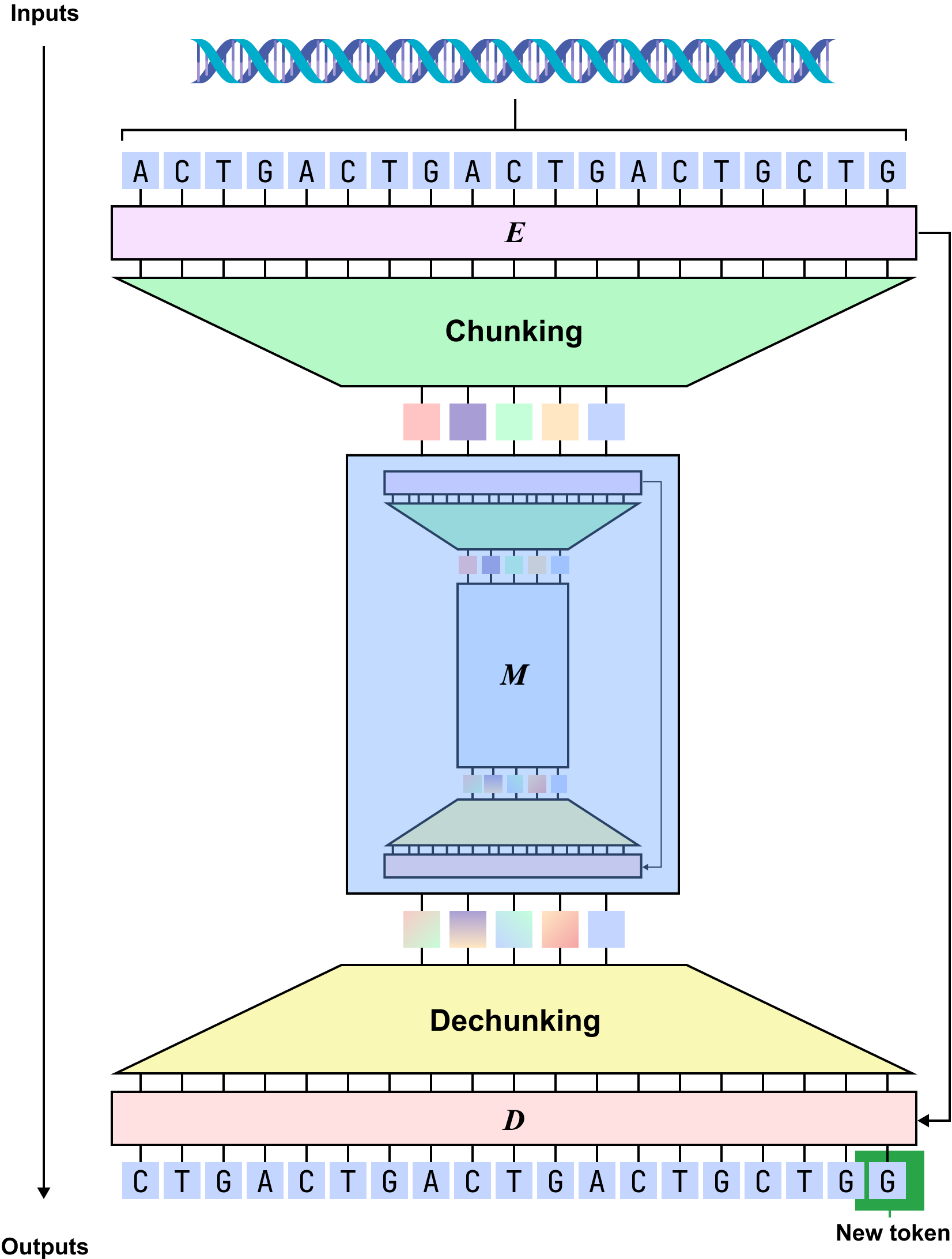
技术框架:dnaHNet是一个自回归模型,其整体架构包含以下几个主要阶段:1) 输入基因组序列;2) 使用可微动态分块机制将核苷酸序列分割成可变长度的chunk;3) 将这些chunk编码成潜在的token表示;4) 使用自回归模型对这些token进行建模,预测下一个token;5) 通过递归分块,实现对基因组序列的分层表示。
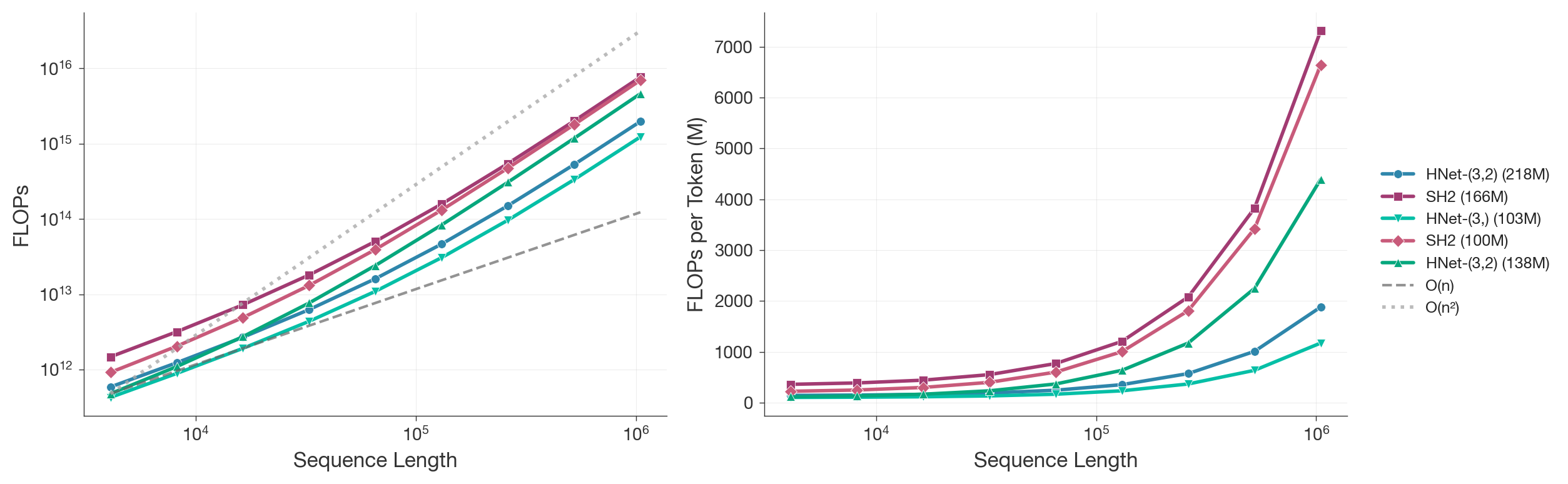
关键创新:dnaHNet最重要的技术创新点在于其可微动态分块机制。与传统的固定分块方法不同,dnaHNet能够根据序列的局部特征自适应地调整chunk的大小,从而更好地保留生物学信息。此外,该机制是可微的,可以通过梯度下降进行优化,使得模型能够学习到最优的分块策略。这种动态分块机制实现了二次FLOP减少,显著提高了模型的效率。
关键设计:dnaHNet的关键设计包括:1) 使用Gumbel-Softmax技巧实现可微的分块决策;2) 设计损失函数,平衡压缩率和预测精度;3) 采用递归分块策略,构建基因组序列的分层表示;4) 使用注意力机制进行token之间的交互,捕捉长距离依赖关系。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
dnaHNet在原核基因组上预训练后,在扩展性和效率方面优于StripedHyena2等领先架构,推理速度比Transformer快3倍以上。在零样本任务中,dnaHNet在预测蛋白质变异适应性和基因必需性方面取得了优异的性能,无需监督即可自动发现分层的生物学结构。
🎯 应用场景
dnaHNet在基因组学领域具有广泛的应用前景,例如蛋白质变异适应性预测、基因必需性预测、基因调控网络推断等。该模型能够帮助研究人员更好地理解基因组的结构和功能,加速药物研发和个性化医疗的进程。未来,dnaHNet有望成为基因组学研究的重要工具,推动生命科学的进步。
📄 摘要(原文)
Genomic foundation models have the potential to decode DNA syntax, yet face a fundamental tradeoff in their input representation. Standard fixed-vocabulary tokenizers fragment biologically meaningful motifs such as codons and regulatory elements, while nucleotide-level models preserve biological coherence but incur prohibitive computational costs for long contexts. We introduce dnaHNet, a state-of-the-art tokenizer-free autoregressive model that segments and models genomic sequences end-to-end. Using a differentiable dynamic chunking mechanism, dnaHNet compresses raw nucleotides into latent tokens adaptively, balancing compression with predictive accuracy. Pretrained on prokaryotic genomes, dnaHNet outperforms leading architectures including StripedHyena2 in scaling and efficiency. This recursive chunking yields quadratic FLOP reductions, enabling $>3 \times$ inference speedup over Transformers. On zero-shot tasks, dnaHNet achieves superior performance in predicting protein variant fitness and gene essentiality, while automatically discovering hierarchical biological structures without supervision. These results establish dnaHNet as a scalable, interpretable framework for next-generation genomic modeling.