LLM-Based Scientific Equation Discovery via Physics-Informed Token-Regularized Policy Optimization
作者: Boxiao Wang, Kai Li, Tianyi Liu, Chen Li, Junzhe Wang, Yifan Zhang, Jian Cheng
分类: cs.LG, cs.AI
发布日期: 2026-02-11
💡 一句话要点
提出PiT-PO框架,通过强化学习自适应调整LLM,用于发现科学方程。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 符号回归 大型语言模型 强化学习 物理信息 方程发现
📋 核心要点
- 现有方法将LLM视为静态生成器,无法根据搜索反馈更新模型内部表示,导致方程物理不一致或冗余。
- PiT-PO通过强化学习将LLM演变为自适应生成器,利用双重约束机制保证方程的物理有效性和结构简洁性。
- PiT-PO在标准基准测试中达到SOTA,并成功发现新的湍流模型,小规模模型性能超越闭源模型。
📝 摘要(中文)
符号回归旨在从观测数据中提炼数学方程。最近的方法成功地利用大型语言模型(LLM)生成方程假设,利用了其大量的预训练科学先验知识。然而,现有的框架主要将LLM视为静态生成器,依赖于提示级别的指导来引导探索。这种模式无法根据搜索反馈更新模型的内部表示,通常会产生物理上不一致或数学上冗余的表达式。本文提出了一种统一的框架PiT-PO(Physics-informed Token-regularized Policy Optimization),该框架通过强化学习将LLM演变为自适应生成器。PiT-PO的核心是一种双重约束机制,它严格执行分层物理有效性,同时应用细粒度的token级别惩罚来抑制冗余结构。因此,PiT-PO使LLM能够生成科学上一致且结构上简洁的方程。实验表明,PiT-PO在标准基准测试中取得了最先进的性能,并成功地为具有挑战性的流体动力学问题发现了新的湍流模型。我们还证明了PiT-PO使小规模模型能够超越闭源巨头,从而普及了高性能科学发现。
🔬 方法详解
问题定义:论文旨在解决符号回归问题,即从观测数据中自动发现数学方程。现有方法主要依赖于提示工程来引导LLM生成方程,但这种方式无法根据搜索反馈更新LLM的内部表示,导致生成的方程可能在物理上不一致或数学上冗余,限制了LLM在科学发现中的潜力。
核心思路:论文的核心思路是通过强化学习训练LLM,使其能够根据环境反馈自适应地生成更优的方程。具体来说,将LLM视为一个策略网络,通过奖励函数鼓励其生成物理上有效且结构简洁的方程。这种方法允许LLM在搜索过程中不断学习和改进,从而克服了传统方法的局限性。
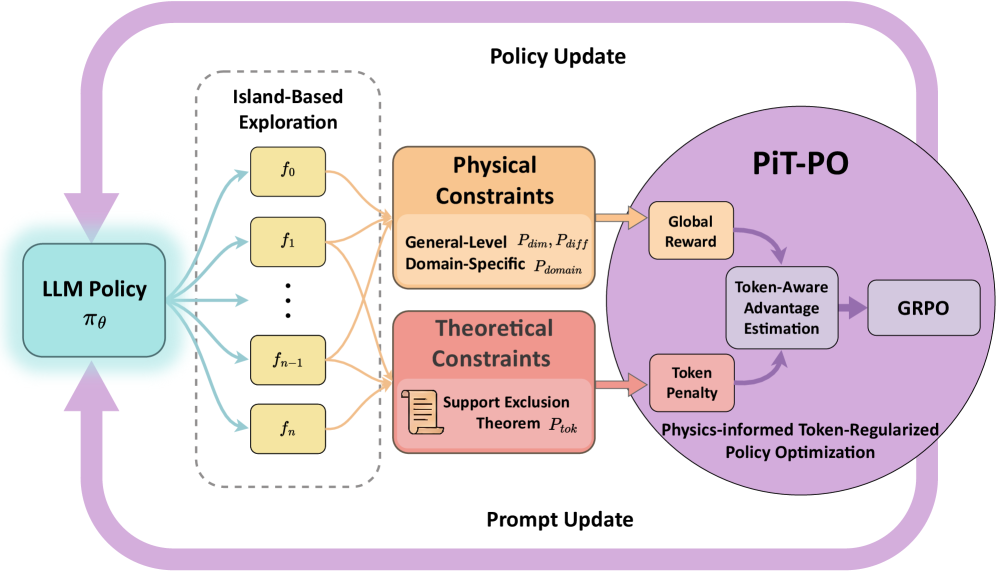
技术框架:PiT-PO框架包含以下主要模块:1) LLM作为策略网络,负责生成方程;2) 物理信息模块,用于评估方程的物理有效性;3) Token正则化模块,用于惩罚方程中的冗余结构;4) 强化学习算法(Policy Optimization),用于更新LLM的参数。整个流程如下:LLM生成方程 -> 物理信息模块和Token正则化模块计算奖励 -> 强化学习算法根据奖励更新LLM -> 重复上述过程,直到LLM能够生成高质量的方程。
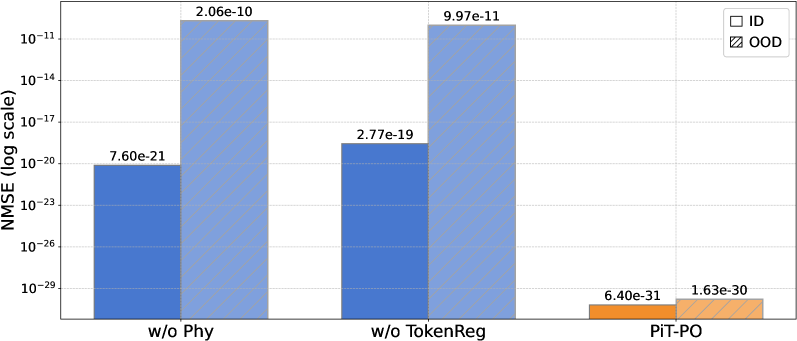
关键创新:PiT-PO的关键创新在于将强化学习引入到基于LLM的符号回归中,并设计了双重约束机制。传统的符号回归方法通常采用启发式搜索或遗传算法,而PiT-PO通过强化学习使LLM能够自适应地学习生成方程的策略。双重约束机制同时考虑了方程的物理有效性和结构简洁性,从而避免了生成不合理或冗余的方程。
关键设计:PiT-PO的关键设计包括:1) 物理信息模块:根据具体的物理问题设计相应的物理约束,例如守恒定律、对称性等。2) Token正则化模块:通过计算方程中各个token的频率,并对高频token进行惩罚,从而抑制冗余结构。3) 奖励函数:综合考虑方程的物理有效性和结构简洁性,例如可以使用物理误差的倒数作为奖励,并减去一个与方程长度相关的惩罚项。4) 强化学习算法:可以使用常见的Policy Gradient算法,例如PPO或TRPO。
🖼️ 关键图片
📊 实验亮点
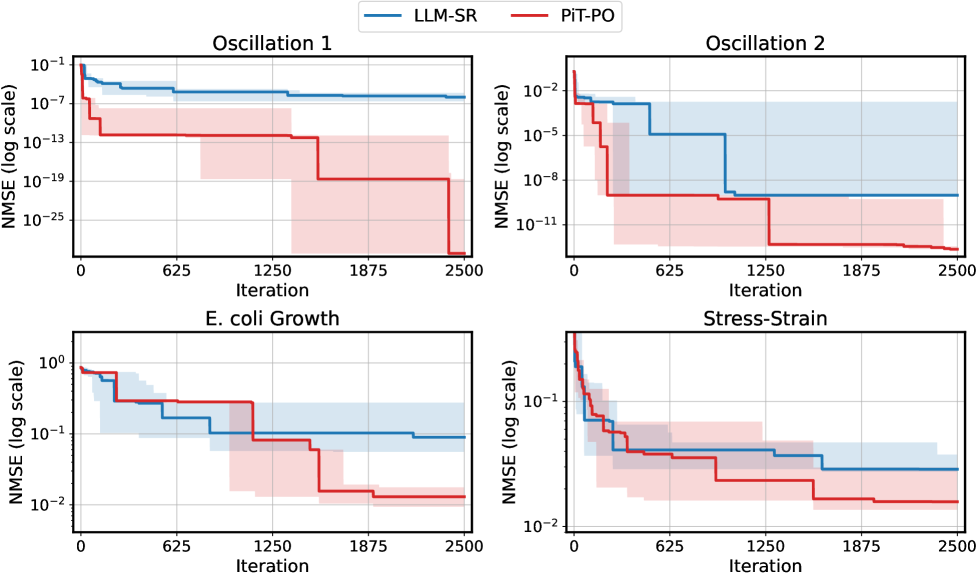
PiT-PO在标准符号回归基准测试中取得了SOTA性能,并在流体动力学问题中成功发现了新的湍流模型。实验结果表明,PiT-PO能够显著提高方程发现的准确性和效率。更重要的是,PiT-PO使小规模模型能够超越闭源巨头,这表明该方法具有很强的泛化能力和实用价值。
🎯 应用场景
PiT-PO具有广泛的应用前景,可用于发现各种科学领域的数学方程,例如物理学、化学、生物学、工程学等。该方法可以帮助科学家自动化地从实验数据中提取知识,加速科学发现的进程。尤其在复杂系统建模、新材料设计、控制系统优化等领域具有重要的应用价值,未来可能促进相关领域的技术革新。
📄 摘要(原文)
Symbolic regression aims to distill mathematical equations from observational data. Recent approaches have successfully leveraged Large Language Models (LLMs) to generate equation hypotheses, capitalizing on their vast pre-trained scientific priors. However, existing frameworks predominantly treat the LLM as a static generator, relying on prompt-level guidance to steer exploration. This paradigm fails to update the model's internal representations based on search feedback, often yielding physically inconsistent or mathematically redundant expressions. In this work, we propose PiT-PO (Physics-informed Token-regularized Policy Optimization), a unified framework that evolves the LLM into an adaptive generator via reinforcement learning. Central to PiT-PO is a dual-constraint mechanism that rigorously enforces hierarchical physical validity while simultaneously applying fine-grained, token-level penalties to suppress redundant structures. Consequently, PiT-PO aligns LLM to produce equations that are both scientifically consistent and structurally parsimonious. Empirically, PiT-PO achieves state-of-the-art performance on standard benchmarks and successfully discovers novel turbulence models for challenging fluid dynamics problems. We also demonstrate that PiT-PO empowers small-scale models to outperform closed-source giants, democratizing access to high-performance scientific discovery.