Gauss-Newton Unlearning for the LLM Era
作者: Lev McKinney, Anvith Thudi, Juhan Bae, Tara Rezaei, Nicolas Papernot, Sheila A. McIlraith, Roger Grosse
分类: cs.LG
发布日期: 2026-02-11
备注: 18 pages
💡 一句话要点
提出K-FADE:基于Gauss-Newton的LLM高效可维护的不可学习方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不可学习 Gauss-Newton K-FAC Hessian近似 模型修正 数据隐私
📋 核心要点
- 现有LLM不可学习方法在遗忘特定数据时,容易损害模型在其他数据分布上的性能。
- 论文提出K-FADE,利用Gauss-Newton步和K-FAC近似,高效计算LLM的不可学习更新。
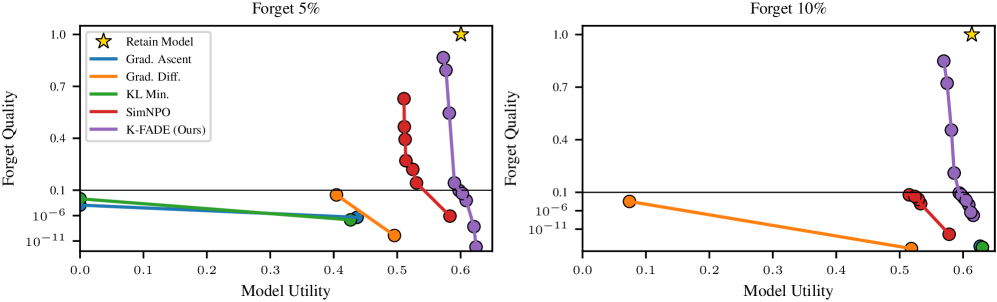
- 实验表明,K-FADE在抑制遗忘集输出的同时,对保留集的影响更小,且更新可维护。
📝 摘要(中文)
大型语言模型训练可能产生训练者认为不可接受的输出。可以使用LLM不可学习等方法来降低这些输出的概率。然而,不可学习某个数据集(称为遗忘集)可能会降低模型在其他分布上的性能,而训练者希望保留模型在这些分布上的行为。为了改善这种权衡,我们证明了使用遗忘集计算少量上坡Gauss-Newton步提供了一种概念简单、最先进的LLM不可学习方法。虽然Gauss-Newton步将牛顿法应用于非线性模型,但为LLM有效且准确地计算此类步并非易事。因此,我们的方法关键在于参数化Hessian近似,例如Kronecker-Factored Approximate Curvature (K-FAC)。我们将这种组合方法称为K-FADE(用于分布擦除的K-FAC)。我们在WMDP和ToFU基准上的评估表明,K-FADE抑制了遗忘集的输出,并在输出空间中近似了不使用遗忘集进行重新训练的结果。关键的是,我们的方法在保留集上改变输出的程度小于以前的方法。这是因为K-FADE将整个保留集上模型输出的约束转换为模型权重的约束,从而允许算法在每一步最小化模型在保留集上的行为变化。此外,如果模型接受进一步训练,K-FADE计算的不可学习更新可以稍后重新应用,从而可以低成本地维护不可学习。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的不可学习问题,即如何使模型忘记某些特定数据(遗忘集)的同时,尽可能保留其在其他数据(保留集)上的性能。现有方法的痛点在于,在遗忘集上进行调整时,往往会对保留集上的性能产生较大的负面影响,导致模型整体性能下降。
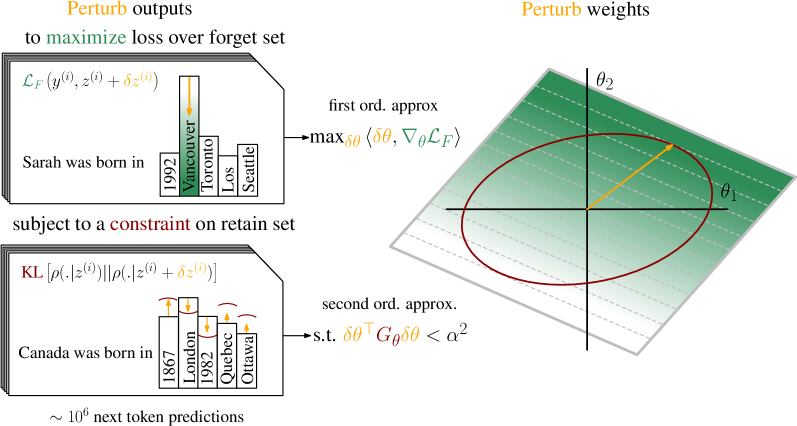
核心思路:论文的核心思路是利用Gauss-Newton方法,通过在参数空间中进行少量迭代更新,来最小化遗忘集上的损失,同时尽可能减少对保留集的影响。关键在于将对模型输出的约束(在保留集上保持原有行为)转化为对模型权重的约束,从而在每一步更新中最小化对保留集的影响。
技术框架:K-FADE方法主要包含以下几个阶段:1) 定义遗忘集和保留集;2) 使用遗忘集计算Gauss-Newton更新方向;3) 利用K-FAC等参数化Hessian近似方法,高效计算Gauss-Newton步长;4) 更新模型权重;5) (可选) 在后续训练中重新应用不可学习更新。
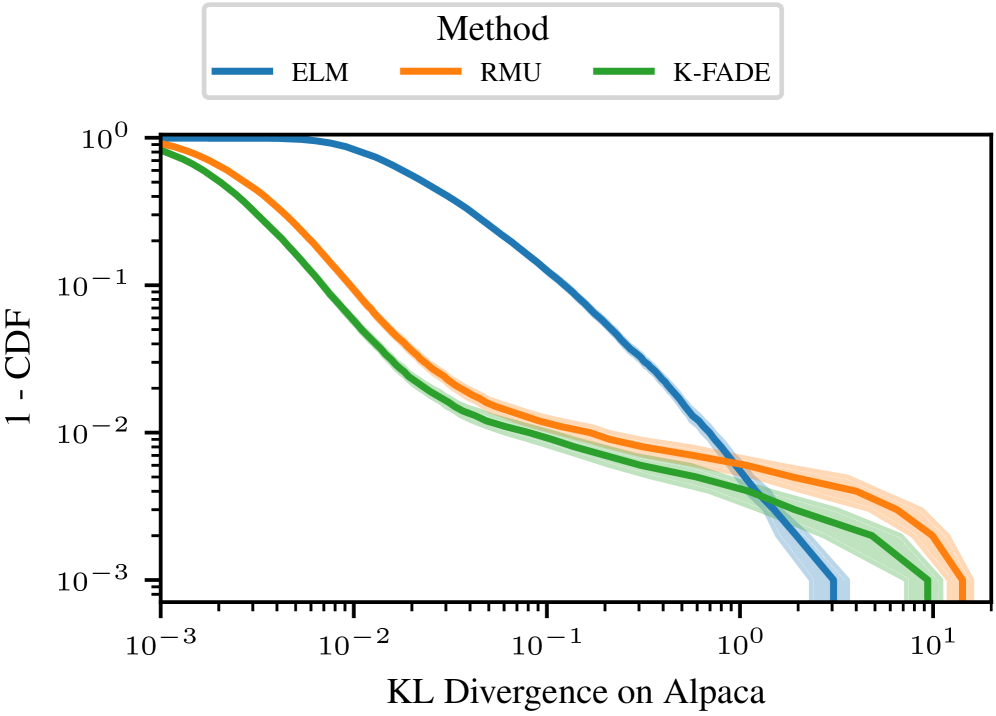
关键创新:最重要的技术创新在于将Gauss-Newton方法与K-FAC等Hessian近似方法相结合,实现了LLM的高效不可学习。与现有方法相比,K-FADE能够更精确地控制不可学习过程对保留集的影响,从而在遗忘特定数据的同时,更好地保留模型的整体性能。此外,K-FADE计算的更新可以被保存和重新应用,使得不可学习过程可以被维护。
关键设计:K-FADE的关键设计包括:1) 使用Gauss-Newton方法进行优化,目标是最小化遗忘集上的损失;2) 使用K-FAC近似Hessian矩阵,以降低计算复杂度;3) 将对保留集输出的约束转化为对模型权重的约束,从而在优化过程中最小化对保留集的影响;4) 设计可维护的更新方式,使得不可学习过程可以被保存和重新应用。
🖼️ 关键图片
📊 实验亮点
实验结果表明,K-FADE在WMDP和ToFU基准测试中,能够有效抑制遗忘集的输出,并在输出空间中近似于不使用遗忘集进行重新训练的结果。更重要的是,K-FADE对保留集的影响明显小于现有方法,能够在遗忘特定数据的同时,更好地保留模型的整体性能。此外,K-FADE计算的更新可以被保存和重新应用,使得不可学习过程可以被维护。
🎯 应用场景
该研究成果可应用于各种需要数据删除或模型修正的场景,例如:1) 移除LLM中的有害或不当内容;2) 应对数据隐私法规,删除包含个人敏感信息的模型记忆;3) 修正模型在特定领域的错误行为。该方法能够提高LLM的安全性、合规性和可靠性,具有重要的实际价值和应用前景。
📄 摘要(原文)
Standard large language model training can create models that produce outputs their trainer deems unacceptable in deployment. The probability of these outputs can be reduced using methods such as LLM unlearning. However, unlearning a set of data (called the forget set) can degrade model performance on other distributions where the trainer wants to retain the model's behavior. To improve this trade-off, we demonstrate that using the forget set to compute only a few uphill Gauss-Newton steps provides a conceptually simple, state-of-the-art unlearning approach for LLMs. While Gauss-Newton steps adapt Newton's method to non-linear models, it is non-trivial to efficiently and accurately compute such steps for LLMs. Hence, our approach crucially relies on parametric Hessian approximations such as Kronecker-Factored Approximate Curvature (K-FAC). We call this combined approach K-FADE (K-FAC for Distribution Erasure). Our evaluation on the WMDP and ToFU benchmarks demonstrates that K-FADE suppresses outputs from the forget set and approximates, in output space, the results of retraining without the forget set. Critically, our method does this while altering the outputs on the retain set less than previous methods. This is because K-FADE transforms a constraint on the model's outputs across the entire retain set into a constraint on the model's weights, allowing the algorithm to minimally change the model's behavior on the retain set at each step. Moreover, the unlearning updates computed by K-FADE can be reapplied later if the model undergoes further training, allowing unlearning to be cheaply maintained.