Contrastive Learning for Multi Label ECG Classification with Jaccard Score Based Sigmoid Loss
作者: Junichiro Takahashi, Masataka Sato, Satoshi Kodeta, Norihiko Takeda
分类: cs.LG, cs.AI
发布日期: 2026-02-11
💡 一句话要点
提出基于Jaccard系数Sigmoid损失的对比学习方法,用于多标签心电图分类
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心电图分类 多标签学习 对比学习 SigLIP Jaccard系数 Sigmoid损失 数据增强
📋 核心要点
- 现有医学AI模型在心电图任务上表现不足,部分模型甚至不支持心电图数据,限制了多模态医学AI的发展。
- 论文提出一种基于SigLIP的对比学习方法,并针对心电图多标签特性改进了损失函数,以构建鲁棒的心电图编码器。
- 实验结果表明,该方法通过融入医学知识和改进损失函数,显著提升了多标签心电图分类的性能。
📝 摘要(中文)
近年来,大型语言模型(LLMs)推动了多模态医疗AI的发展。尽管像MedGemini这样的模型在USMLE MM等VQA任务上表现出色,但在基于心电图的任务中性能仍然有限,而某些模型(如MedGemma)甚至不支持心电图数据。心电图的判读具有挑战性,诊断准确性因判读者经验而异。超声心动图虽然提供丰富的诊断信息,但需要专门的设备和人员,限制了其可用性。本研究侧重于构建一个鲁棒的心电图编码器,用于使用真实医院数据的多模态预训练。我们采用SigLIP,这是一种基于CLIP的模型,具有基于sigmoid的损失函数,可实现多标签预测,并引入了针对心电图数据多标签性质的改进损失函数。实验表明,在语言模型中加入医学知识并应用改进的损失函数可显著提高多标签心电图分类的性能。为了进一步提高性能,我们增加了嵌入维度并应用随机裁剪来缓解数据漂移。最后,按标签分析揭示了哪些心电图结果更容易或更难预测。我们的研究为开发利用心电图数据的医学模型提供了一个基础框架。
🔬 方法详解
问题定义:论文旨在解决多标签心电图(ECG)分类问题。现有方法在处理ECG数据时,尤其是在多标签场景下,准确率不高,且缺乏对真实世界医院数据的有效利用。现有方法的痛点在于无法充分利用ECG数据的多标签特性,以及对数据漂移的鲁棒性不足。
核心思路:论文的核心思路是利用对比学习框架SigLIP,并针对ECG数据的多标签特性,设计一种基于Jaccard系数的Sigmoid损失函数。通过对比学习,模型能够学习到ECG数据的有效表征,而改进的损失函数则能够更好地处理多标签分类问题。同时,通过数据增强(随机裁剪)来提高模型对数据漂移的鲁棒性。
技术框架:整体框架基于CLIP模型,使用SigLIP作为基础模型。主要流程包括:1) 数据预处理,包括数据增强(随机裁剪);2) 使用改进的Sigmoid损失函数进行对比学习训练;3) 对训练好的ECG编码器进行评估,分析各个标签的预测难度。框架的核心在于改进的损失函数和数据增强策略。
关键创新:论文的关键创新在于提出了基于Jaccard系数的Sigmoid损失函数,该损失函数更适合处理多标签ECG分类问题。与传统的Sigmoid损失函数相比,该损失函数考虑了标签之间的相关性,能够更准确地评估模型的预测结果。此外,使用随机裁剪来缓解数据漂移也是一个重要的创新点。
关键设计:关键设计包括:1) 损失函数:使用基于Jaccard系数的Sigmoid损失函数,具体形式未知(论文未给出具体公式);2) 数据增强:采用随机裁剪来缓解数据漂移;3) 模型结构:基于SigLIP,并增加了嵌入维度以提高模型容量;4) 医学知识融入:在语言模型中融入医学知识(具体方法未知)。
🖼️ 关键图片
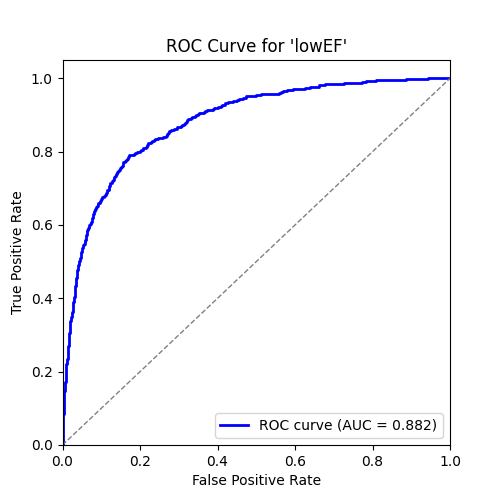
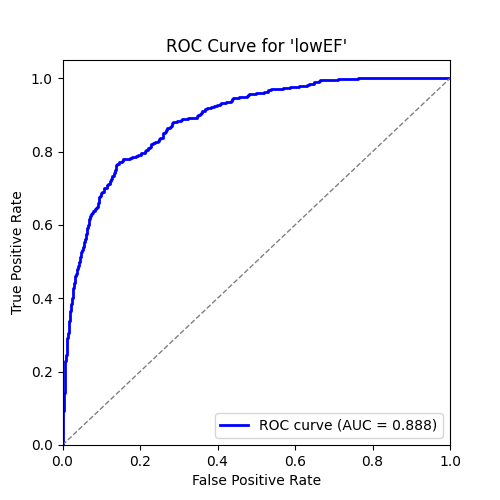
📊 实验亮点
实验结果表明,通过在语言模型中加入医学知识并应用改进的损失函数,多标签心电图分类的性能得到了显著提高。此外,增加嵌入维度和应用随机裁剪也进一步提升了模型的性能。论文还进行了按标签分析,揭示了不同心电图结果的预测难度,为后续研究提供了指导。
🎯 应用场景
该研究成果可应用于构建更准确、更鲁棒的心电图诊断系统,辅助医生进行疾病诊断和风险评估。通过结合心电图数据和其他模态数据(如影像、文本),可以开发更全面的多模态医疗AI系统,提升医疗服务的效率和质量。该方法也为其他多标签医学数据分析任务提供了借鉴。
📄 摘要(原文)
Recent advances in large language models (LLMs) have enabled the development of multimodal medical AI. While models such as MedGemini achieve high accuracy on VQA tasks like USMLE MM, their performance on ECG based tasks remains limited, and some models, such as MedGemma, do not support ECG data at all. Interpreting ECGs is inherently challenging, and diagnostic accuracy can vary depending on the interpreter's experience. Although echocardiography provides rich diagnostic information, it requires specialized equipment and personnel, limiting its availability. In this study, we focus on constructing a robust ECG encoder for multimodal pretraining using real world hospital data. We employ SigLIP, a CLIP based model with a sigmoid based loss function enabling multi label prediction, and introduce a modified loss function tailored to the multi label nature of ECG data. Experiments demonstrate that incorporating medical knowledge in the language model and applying the modified loss significantly improve multi label ECG classification. To further enhance performance, we increase the embedding dimensionality and apply random cropping to mitigate data drift. Finally, per label analysis reveals which ECG findings are easier or harder to predict. Our study provides a foundational framework for developing medical models that utilize ECG data.