Control Reinforcement Learning: Token-Level Mechanistic Analysis via Learned SAE Feature Steering
作者: Seonglae Cho, Zekun Wu, Adriano Koshiyama
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-11
💡 一句话要点
提出Control Reinforcement Learning,通过学习SAE特征引导实现token级别机制分析。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 可解释性 强化学习 稀疏自编码器 特征引导 语言模型 机制分析 动态干预
📋 核心要点
- 现有方法仅揭示了哪些SAE特征被激活,而无法确定放大哪些特征会改变模型输出,这是核心问题。
- CRL训练强化学习策略,在每个token选择SAE特征进行引导,从而产生可解释的干预日志,解决上述问题。
- 实验表明,在多个基准测试中,CRL在Gemma-2 2B模型上实现了性能提升,并提供了token级别的干预日志。
📝 摘要(中文)
本文提出控制强化学习(CRL),该方法训练一个策略来选择用于引导的稀疏自编码器(SAE)特征,从而在每个token上产生可解释的干预日志。学习到的策略识别出放大时能够改变模型输出的特征。自适应特征掩码鼓励多样化的特征发现,同时保持单特征的可解释性。该框架产生了新的分析能力:分支点跟踪定位特征选择决定输出正确性的token;评论员轨迹分析将策略限制与价值估计误差分离;逐层比较揭示了早期层中的句法特征和后期层中的语义特征。在MMLU、BBQ、GSM8K、HarmBench和XSTest上,Gemma-2 2B模型通过CRL实现了改进,同时提供了每个token的干预日志。这些结果确立了学习到的特征引导作为一种机制可解释性工具,它通过动态干预探针补充了静态特征分析。
🔬 方法详解
问题定义:现有方法利用稀疏自编码器(SAE)将语言模型激活分解为可解释的特征,但仅能识别哪些特征被激活,无法确定放大哪些特征能够改变模型的输出,从而影响模型的决策过程。这限制了对模型内部机制的深入理解。
核心思路:本文的核心思路是通过强化学习训练一个策略,该策略能够根据当前token选择合适的SAE特征进行引导。通过观察放大这些特征后模型输出的变化,可以推断出这些特征对模型决策的影响。这种动态干预的方式能够更深入地理解模型内部的机制。
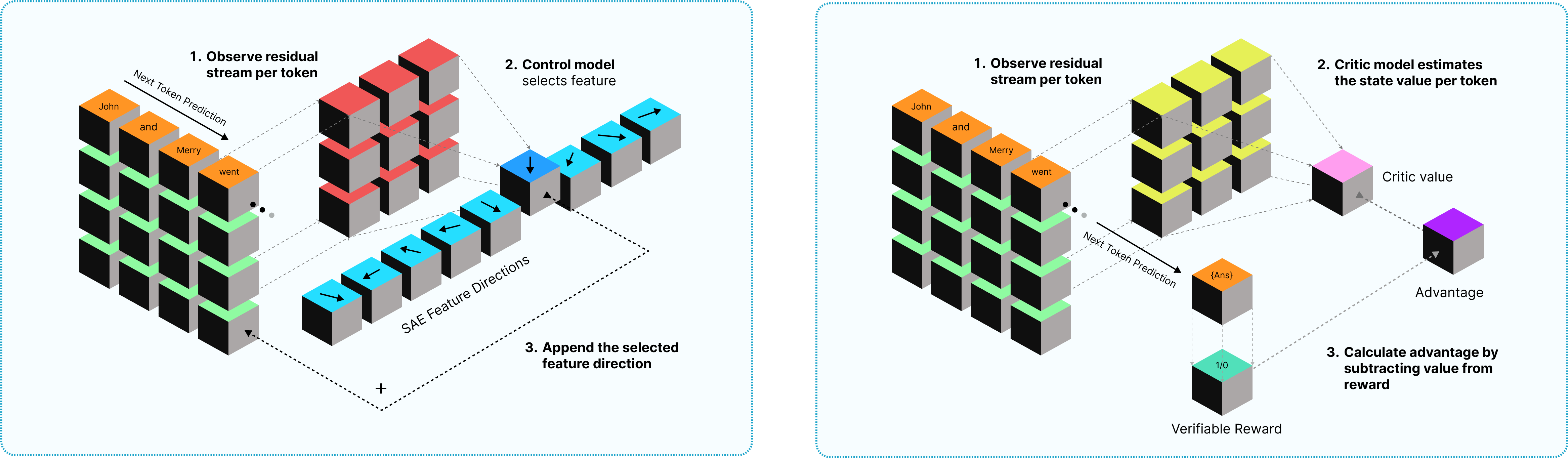
技术框架:CRL框架包含以下主要模块:1) 稀疏自编码器(SAE):用于将语言模型的激活分解为可解释的特征。2) 强化学习策略:根据当前token选择要放大的SAE特征。3) 语言模型:接受干预后的特征激活,并生成输出。4) 奖励函数:根据模型输出的正确性或期望行为来奖励强化学习策略。整个流程是,对于每个token,策略选择SAE特征,然后将这些特征的激活放大并输入到语言模型中,最后根据模型输出计算奖励,并更新策略。
关键创新:最重要的技术创新点在于将强化学习引入到SAE特征引导中,从而实现动态的、token级别的特征干预。与静态的特征分析方法相比,CRL能够更准确地识别出对模型决策有重要影响的特征。此外,Adaptive Feature Masking鼓励策略探索更多样化的特征,避免策略过度依赖少数几个特征。
关键设计:Adaptive Feature Masking是一种关键设计,它通过在训练过程中随机屏蔽一部分特征,来鼓励策略探索更多不同的特征组合。奖励函数的设计至关重要,需要根据具体的任务目标进行调整,例如,可以使用模型输出的正确率作为奖励,或者使用与期望输出的相似度作为奖励。策略网络可以使用Transformer架构,输入是当前token的嵌入向量,输出是每个SAE特征的选择概率。
🖼️ 关键图片

📊 实验亮点
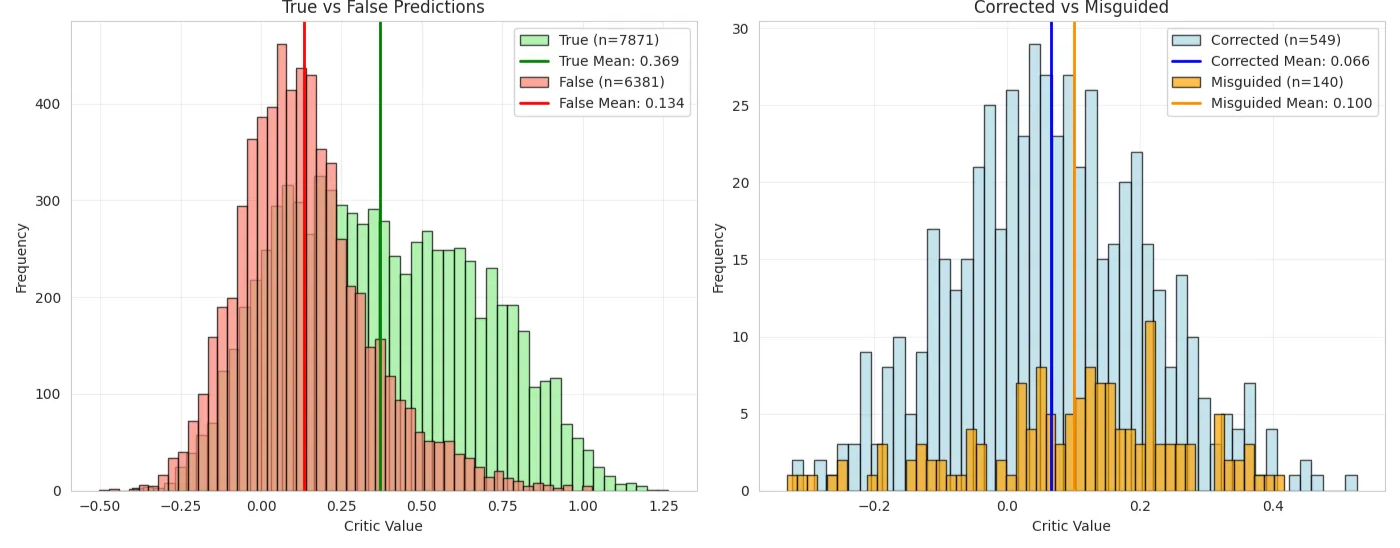
实验结果表明,CRL在多个基准测试(包括MMLU、BBQ、GSM8K、HarmBench和XSTest)上,使用Gemma-2 2B模型实现了性能提升,同时提供了每个token的干预日志。这些日志可以用于分析模型在不同任务上的决策过程,并识别关键的特征。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可解释性和安全性。通过理解模型内部的决策机制,可以更好地诊断和修复模型中的偏差和漏洞,例如,可以用于识别导致模型产生有害或不公平输出的特征,并采取相应的措施进行干预。此外,该方法还可以用于教育领域,帮助学生更好地理解语言模型的内部工作原理。
📄 摘要(原文)
Sparse autoencoders (SAEs) decompose language model activations into interpretable features, but existing methods reveal only which features activate, not which change model outputs when amplified. We introduce Control Reinforcement Learning (CRL), which trains a policy to select SAE features for steering at each token, producing interpretable intervention logs: the learned policy identifies features that change model outputs when amplified. Adaptive Feature Masking encourages diverse feature discovery while preserving singlefeature interpretability. The framework yields new analysis capabilities: branch point tracking locates tokens where feature choice determines output correctness; critic trajectory analysis separates policy limitations from value estimation errors; layer-wise comparison reveals syntactic features in early layers and semantic features in later layers. On Gemma-2 2B across MMLU, BBQ, GSM8K, HarmBench, and XSTest, CRL achieves improvements while providing per-token intervention logs. These results establish learned feature steering as a mechanistic interpretability tool that complements static feature analysis with dynamic intervention probes