QTALE: Quantization-Robust Token-Adaptive Layer Execution for LLMs
作者: Kanghyun Noh, Jinheon Choi, Yulwha Kim
分类: cs.LG
发布日期: 2026-02-11
备注: 8 pages, 6 figures, 6 tables
💡 一句话要点
QTALE:面向LLM的量化鲁棒Token自适应层执行框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 Token自适应 层执行 模型压缩
📋 核心要点
- 现有token自适应方法在量化后精度下降明显,原因是其减少了模型冗余,对量化噪声更加敏感。
- QTALE通过在训练时探索更多样化的执行路径,并在推理时灵活调整执行比例来重新引入冗余,从而提升量化鲁棒性。
- 实验表明,QTALE能够无缝集成token自适应层执行和量化,精度损失很小,在CommonsenseQA上与仅量化模型差距小于0.5%。
📝 摘要(中文)
大型语言模型(LLMs)对计算和内存资源的需求巨大,给高效部署带来了挑战。目前有两种互补的方法来解决这些问题:token自适应层执行,通过选择性地跳过层来减少浮点运算(FLOPs);量化,通过降低权重精度来减少内存占用。然而,由于token自适应模型中冗余的减少,简单地集成这些技术会导致额外的精度下降。我们提出了QTALE(Quantization-Robust Token-Adaptive Layer Execution for LLMs),这是一个新颖的框架,可以无缝集成token自适应执行和量化,同时保持精度。传统的token自适应方法通过两种方式减少冗余:(1)限制微调期间探索的训练路径的多样性,以及(2)降低推理过程中主动参与的参数数量。为了克服这些限制,QTALE引入了两个关键组件:(1)一种训练策略,确保在微调期间积极探索不同的执行路径,以及(2)一种后训练机制,允许在推理时灵活调整执行比例,以便在需要时重新引入冗余。实验结果表明,QTALE能够无缝集成token自适应层执行和量化,在CommonsenseQA基准测试中,精度差异不明显,与仅量化模型的差距保持在0.5%以下。通过结合token自适应执行以减少FLOPs和量化以节省内存,QTALE为高效的LLM部署提供了一个有效的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在部署时面临的计算资源和内存资源挑战。现有的token自适应层执行和量化方法虽然可以分别降低FLOPs和内存占用,但直接结合使用会导致精度显著下降,因为token自适应减少了模型冗余,使得模型对量化引入的噪声更加敏感。
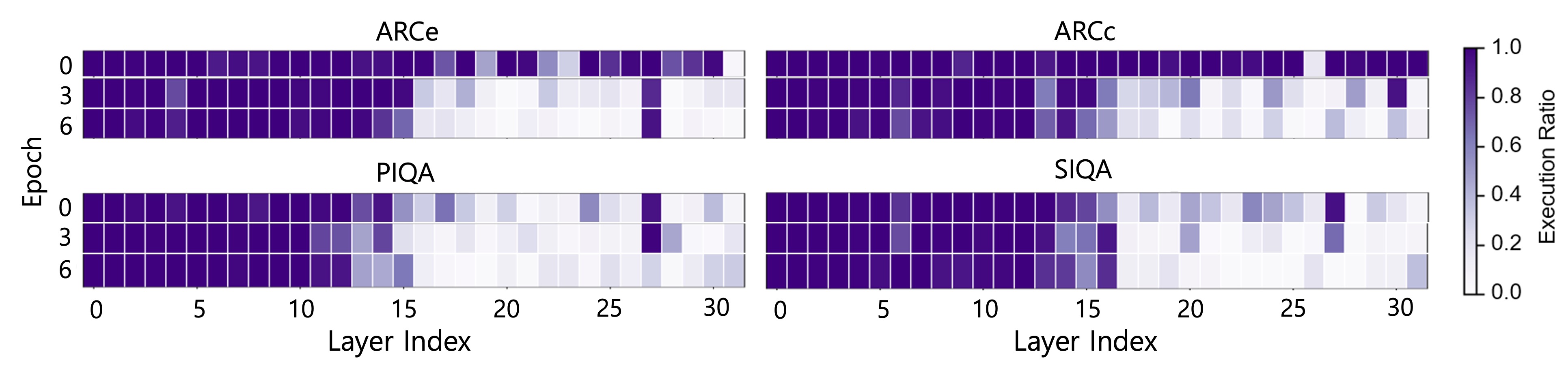
核心思路:QTALE的核心思路是通过在训练和推理阶段重新引入冗余来提高量化鲁棒性。具体来说,通过一种新的训练策略,确保模型在微调期间探索更多样化的执行路径,从而增强模型对不同输入token的适应能力。此外,在推理阶段,允许灵活调整执行比例,以便在需要时重新引入冗余,以抵消量化带来的精度损失。
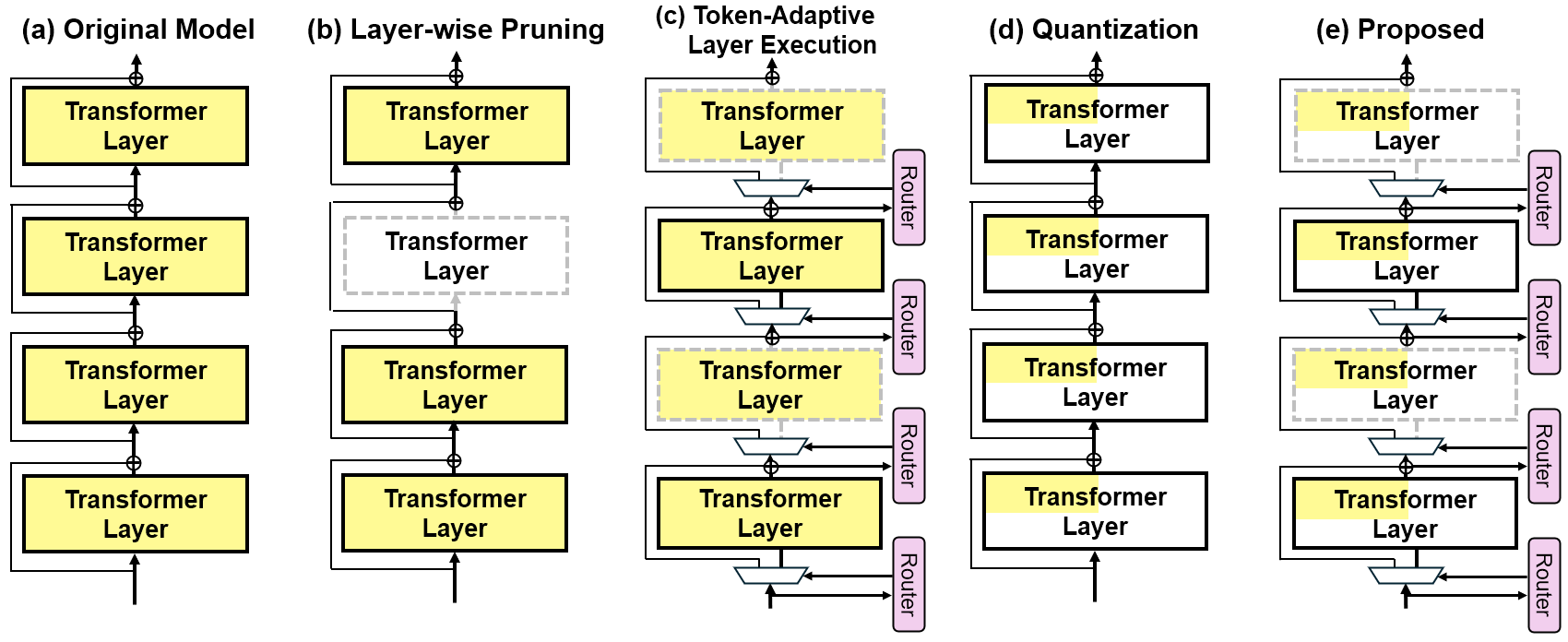
技术框架:QTALE框架主要包含两个关键组件:一是训练策略,用于确保在微调期间积极探索不同的执行路径;二是后训练机制,允许在推理时灵活调整执行比例。训练策略通过鼓励模型探索更多样化的执行路径来增强模型的泛化能力。后训练机制则允许根据实际情况调整执行比例,以在计算效率和精度之间取得平衡。
关键创新:QTALE的关键创新在于其训练策略和后训练机制的结合,能够有效地提高token自适应模型在量化后的鲁棒性。与传统的token自适应方法相比,QTALE不再过度减少模型冗余,而是通过动态调整执行路径和比例,使得模型能够在量化环境下保持较高的精度。
关键设计:训练策略的具体实现可能涉及到修改损失函数,例如引入正则化项来鼓励模型探索更多样化的执行路径。后训练机制则可能需要设计一种算法,根据模型的性能指标(如精度、延迟)动态调整执行比例。具体的参数设置和网络结构细节可能需要根据具体的LLM架构进行调整。
🖼️ 关键图片

📊 实验亮点
QTALE在CommonsenseQA基准测试中表现出色,实现了token自适应层执行与量化的无缝集成,精度损失控制在极低水平,与仅量化模型相比,精度差距小于0.5%。这表明QTALE能够有效提高量化鲁棒性,为LLM的高效部署提供了一种可行的解决方案。
🎯 应用场景
QTALE适用于对计算资源和内存资源有限制的场景,例如移动设备、边缘计算设备等。通过结合token自适应层执行和量化,QTALE可以显著降低LLM的部署成本,使其能够在资源受限的环境中高效运行,从而推动LLM在更广泛的应用领域落地。
📄 摘要(原文)
Large language models (LLMs) demand substantial computational and memory resources, posing challenges for efficient deployment. Two complementary approaches have emerged to address these issues: token-adaptive layer execution, which reduces floating-point operations (FLOPs) by selectively bypassing layers, and quantization, which lowers memory footprint by reducing weight precision. However, naively integrating these techniques leads to additional accuracy degradation due to reduced redundancy in token-adaptive models. We propose QTALE (Quantization-Robust Token-Adaptive Layer Execution for LLMs), a novel framework that enables seamless integration of token-adaptive execution with quantization while preserving accuracy. Conventional token-adaptive methods reduce redundancy in two ways: (1) by limiting the diversity of training paths explored during fine-tuning, and (2) by lowering the number of parameters actively involved in inference. To overcome these limitations, QTALE introduces two key components: (1) a training strategy that ensures diverse execution paths are actively explored during fine-tuning, and (2) a post-training mechanism that allows flexible adjustment of the execution ratio at inference to reintroduce redundancy when needed. Experimental results show that QTALE enables seamless integration of token-adaptive layer execution with quantization, showing no noticeable accuracy difference, with the gap to quantization-only models kept below 0.5% on CommonsenseQA benchmarks. By combining token-adaptive execution for FLOPs reduction and quantization for memory savings, QTALE provides an effective solution for efficient LLM deployment.