Binary Flow Matching: Prediction-Loss Space Alignment for Robust Learning
作者: Jiadong Hong, Lei Liu, Xinyu Bian, Wenjie Wang, Zhaoyang Zhang
分类: cs.LG, cs.IT, eess.IV, eess.SP
发布日期: 2026-02-11
备注: 12 pages, 4 tables, 5 figures
💡 一句话要点
提出二元流匹配,通过预测损失空间对齐实现二元数据生成模型的鲁棒学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 二元数据生成 流匹配 预测损失空间对齐 鲁棒学习 信号空间预测
📋 核心要点
- 现有基于速度的流匹配目标函数在二元数据生成中存在结构失配问题,导致训练不稳定。
- 论文提出预测损失空间对齐的概念,通过信号空间损失函数消除奇异加权,实现梯度一致有界。
- 理论分析和实验结果表明,该方法能够提升二元数据流匹配的鲁棒性,无需启发式调度。
📝 摘要(中文)
流匹配已成为生成建模的强大框架,最近的经验成功突显了信号空间预测($x$-prediction)的有效性。本文研究了将这种范式转移到二元流形上,这是离散数据生成建模的基本设置。虽然$x$-prediction仍然有效,但我们发现当它与基于速度的目标($v$-loss)结合时,会产生潜在的结构失配,导致时间相关的奇异加权,从而放大了梯度对近似误差的敏感性。基于此,我们将预测损失对齐形式化为流匹配训练的必要条件。我们证明,将目标重新对齐到信号空间($x$-loss)可以消除奇异加权,产生一致有界的梯度,并能够在均匀时间步长采样下进行鲁棒训练,而无需依赖启发式调度。最后,在确保对齐的情况下,我们研究了二元数据的特定设计选择,揭示了概率目标(例如,交叉熵)和几何损失(例如,均方误差)之间拓扑相关的区别。总之,这些结果为二元(以及相关的离散)域上的鲁棒流匹配提供了理论基础和实践指导,将信号空间对齐定位为鲁棒扩散学习的关键原则。
🔬 方法详解
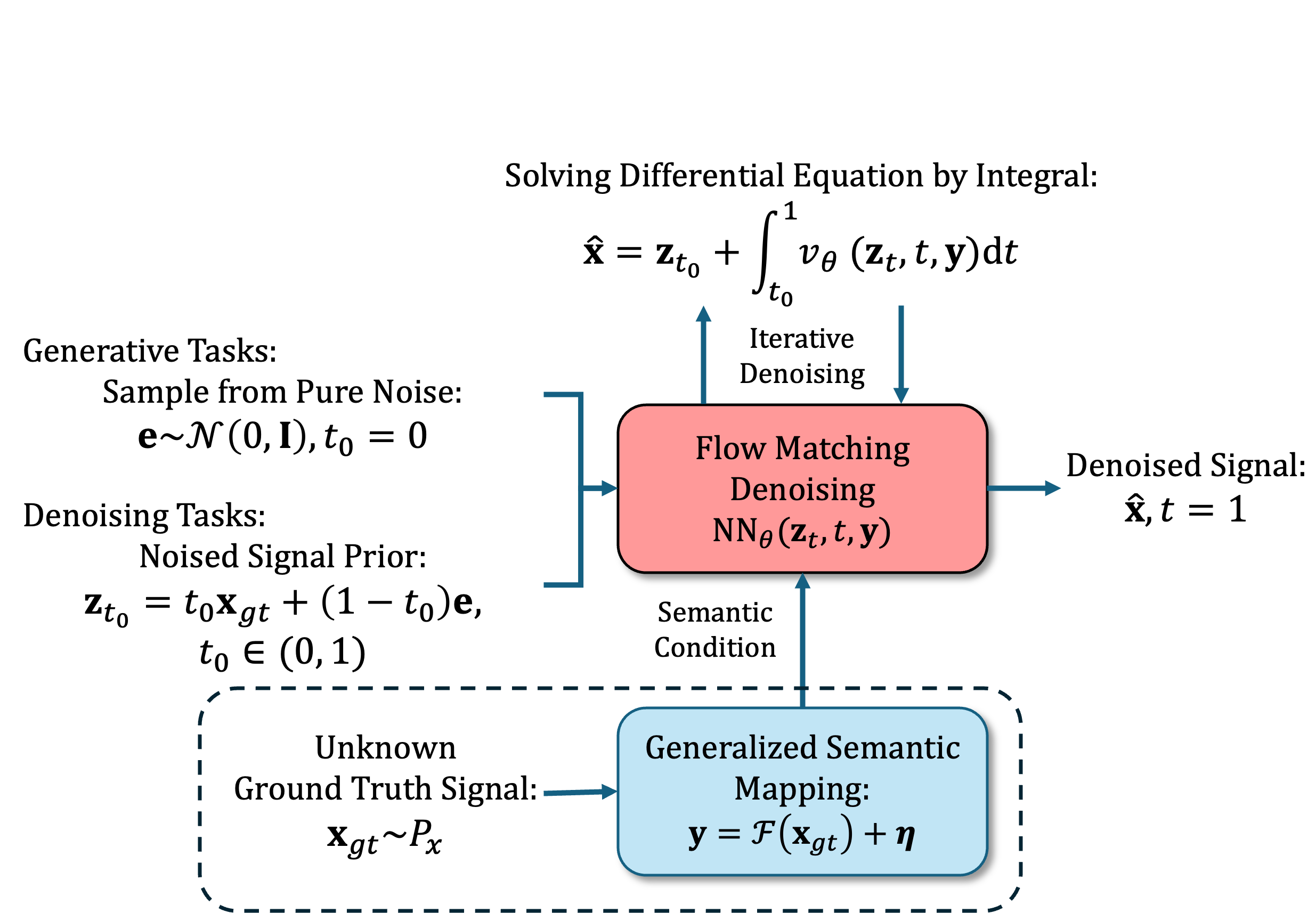
问题定义:论文旨在解决二元数据生成建模中,使用流匹配方法时遇到的训练不稳定问题。具体来说,当使用基于速度的目标函数(v-loss)进行训练时,会产生时间相关的奇异加权,导致梯度对近似误差非常敏感,使得训练过程难以收敛。现有的解决方法通常依赖于启发式调度,缺乏理论支撑。
核心思路:论文的核心思路是将预测损失空间进行对齐。作者观察到,使用信号空间预测(x-prediction)结合基于速度的损失函数(v-loss)会导致结构失配。为了解决这个问题,作者提出将目标函数重新对齐到信号空间(x-loss),从而消除奇异加权,使得梯度具有一致的有界性。这样可以避免梯度爆炸或消失,从而实现更鲁棒的训练。
技术框架:整体框架仍然是基于流匹配的生成模型,主要包含以下几个阶段: 1. 定义二元流形上的连续时间动力系统。 2. 使用神经网络学习该动力系统的速度场。 3. 通过求解常微分方程(ODE)或随机微分方程(SDE)来生成数据。 4. 使用提出的信号空间损失函数(x-loss)训练神经网络。
关键创新:论文最重要的技术创新点在于提出了预测损失空间对齐的概念,并证明了使用信号空间损失函数可以消除奇异加权,从而实现更鲁棒的训练。与现有方法相比,该方法不需要启发式调度,具有更好的理论基础和泛化能力。
关键设计:论文的关键设计包括: 1. 使用信号空间损失函数(x-loss)作为训练目标,例如均方误差(MSE)。 2. 分析了概率目标(如交叉熵)和几何损失(如MSE)在二元数据上的区别,并给出了选择的建议。 3. 采用均匀时间步长采样进行训练,避免了启发式调度。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了所提出的信号空间对齐方法的有效性。实验结果表明,使用信号空间损失函数(x-loss)训练的二元流匹配模型,在均匀时间步长采样下,能够实现更稳定的训练和更好的生成效果,无需依赖启发式调度。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于各种二元数据的生成建模任务,例如图像二值化、文本生成、生物序列建模等。通过提高生成模型的鲁棒性和稳定性,可以降低训练成本,提升生成质量,从而在人工智能、计算机视觉、自然语言处理等领域发挥重要作用。
📄 摘要(原文)
Flow matching has emerged as a powerful framework for generative modeling, with recent empirical successes highlighting the effectiveness of signal-space prediction ($x$-prediction). In this work, we investigate the transfer of this paradigm to binary manifolds, a fundamental setting for generative modeling of discrete data. While $x$-prediction remains effective, we identify a latent structural mismatch that arises when it is coupled with velocity-based objectives ($v$-loss), leading to a time-dependent singular weighting that amplifies gradient sensitivity to approximation errors. Motivated by this observation, we formalize prediction-loss alignment as a necessary condition for flow matching training. We prove that re-aligning the objective to the signal space ($x$-loss) eliminates the singular weighting, yielding uniformly bounded gradients and enabling robust training under uniform timestep sampling without reliance on heuristic schedules. Finally, with alignment secured, we examine design choices specific to binary data, revealing a topology-dependent distinction between probabilistic objectives (e.g., cross-entropy) and geometric losses (e.g., mean squared error). Together, these results provide theoretical foundations and practical guidelines for robust flow matching on binary -- and related discrete -- domains, positioning signal-space alignment as a key principle for robust diffusion learning.