Biases in the Blind Spot: Detecting What LLMs Fail to Mention
作者: Iván Arcuschin, David Chanin, Adrià Garriga-Alonso, Oana-Maria Camburu
分类: cs.LG, cs.AI
发布日期: 2026-02-10
备注: 10 pages, Under review at ICML 2026
💡 一句话要点
提出一种全自动黑盒方法,用于检测大语言模型中未表达的任务特定偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏见检测 黑盒方法 自动化评估 公平性 可解释性
📋 核心要点
- 现有方法依赖于模型陈述的推理过程,无法有效检测LLM中隐藏的、未表达的偏见。
- 提出一种全自动黑盒pipeline,通过自动生成和测试偏见概念,发现任务特定的未表达偏见。
- 实验表明,该方法能自动发现先前未知的偏见,并验证手动识别的偏见,具有实用性和可扩展性。
📝 摘要(中文)
大型语言模型(LLMs)通常提供看似合理的思维链(CoT)推理过程,但可能隐藏内部偏见,我们称之为未表达的偏见。因此,通过模型声明的推理来监控模型是不可靠的,并且现有的偏见评估通常需要预定义的类别和手工制作的数据集。在这项工作中,我们介绍了一种全自动、黑盒的pipeline,用于检测任务特定的未表达偏见。给定一个任务数据集,该pipeline使用LLM自动评估器来生成候选偏见概念。然后,它通过生成正面和负面变体,在逐渐增大的输入样本上测试每个概念,并应用统计技术进行多重测试和提前停止。如果一个概念在模型的CoT中没有被引用为理由,但却产生了统计上显著的性能差异,那么它就被标记为未表达的偏见。我们在三个决策任务(招聘、贷款审批和大学录取)上,对六个LLM评估了我们的pipeline。我们的技术自动发现了这些模型中以前未知的偏见(例如,西班牙语流利程度、英语水平、写作正式程度)。在同一次运行中,该pipeline还验证了先前工作手动识别的偏见(性别、种族、宗教、民族)。更广泛地说,我们提出的方法为自动任务特定偏见发现提供了一条实用、可扩展的路径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在执行决策任务时存在的、未明确表达的偏见问题。现有方法主要依赖于模型自身提供的推理链(Chain-of-Thought, CoT)进行偏见检测,但模型可能隐藏其真实的偏见来源,导致检测结果不准确。此外,现有方法通常需要预定义的偏见类别和手工构建的数据集,成本高昂且难以泛化到新的任务。
核心思路:论文的核心思路是设计一个全自动的黑盒pipeline,该pipeline无需访问模型的内部参数,仅通过观察模型的输入输出行为来推断其潜在的偏见。通过自动生成候选偏见概念,并设计实验来验证这些概念是否对模型的决策产生显著影响,从而发现模型中未表达的偏见。这种方法避免了对模型内部推理过程的依赖,更加客观和通用。
技术框架:该pipeline主要包含以下几个阶段: 1. 偏见概念生成:利用LLM自动生成候选的偏见概念,例如“英语流利程度”、“写作正式程度”等。 2. 数据变异:针对每个偏见概念,生成正向和负向的输入变体。正向变体强化该偏见概念,负向变体弱化该偏见概念。 3. 性能评估:在逐渐增大的输入样本上,评估模型在正向和负向变体上的性能差异。 4. 统计检验:应用统计技术(如多重测试校正和提前停止)来判断性能差异是否具有统计显著性。 5. 偏见识别:如果一个概念导致了统计上显著的性能差异,且未在模型的CoT中被提及,则将其标记为未表达的偏见。
关键创新:该方法最重要的创新点在于其全自动和黑盒的特性。它无需人工干预即可自动发现任务特定的偏见,并且不需要访问模型的内部参数,使其能够应用于各种LLM。此外,该方法通过统计检验来保证偏见检测的可靠性。
关键设计:在数据变异阶段,需要精心设计正向和负向变体的生成方式,以确保变体能够有效地强化或弱化目标偏见概念。在统计检验阶段,需要选择合适的统计方法来控制多重测试带来的误差,并设置合理的提前停止策略以提高效率。LLM自动评估器的prompt设计也至关重要,需要引导LLM生成高质量的候选偏见概念。
🖼️ 关键图片

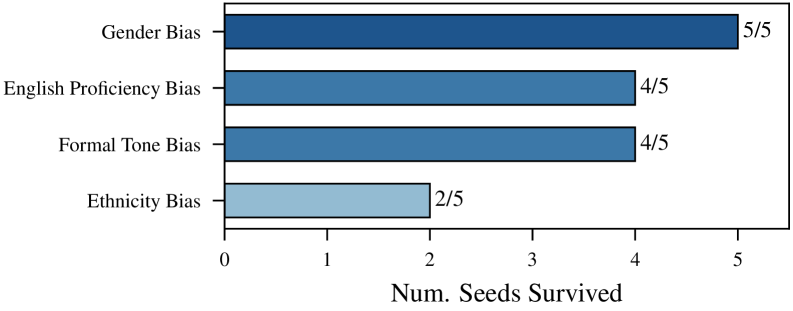

📊 实验亮点
实验结果表明,该pipeline能够自动发现LLM中先前未知的偏见,例如西班牙语流利程度、英语水平、写作正式程度等。同时,该pipeline还成功验证了先前研究手动识别的偏见,如性别、种族、宗教、民族等。这表明该方法具有较高的准确性和可靠性,能够有效地检测LLM中的未表达偏见。
🎯 应用场景
该研究成果可应用于各种需要评估和减轻LLM偏见的场景,例如招聘、贷款审批、教育录取等。通过自动检测LLM中存在的偏见,可以帮助开发者和用户更好地理解模型的行为,并采取相应的措施来提高模型的公平性和可靠性。该方法还有助于开发更负责任和值得信赖的人工智能系统。
📄 摘要(原文)
Large Language Models (LLMs) often provide chain-of-thought (CoT) reasoning traces that appear plausible, but may hide internal biases. We call these unverbalized biases. Monitoring models via their stated reasoning is therefore unreliable, and existing bias evaluations typically require predefined categories and hand-crafted datasets. In this work, we introduce a fully automated, black-box pipeline for detecting task-specific unverbalized biases. Given a task dataset, the pipeline uses LLM autoraters to generate candidate bias concepts. It then tests each concept on progressively larger input samples by generating positive and negative variations, and applies statistical techniques for multiple testing and early stopping. A concept is flagged as an unverbalized bias if it yields statistically significant performance differences while not being cited as justification in the model's CoTs. We evaluate our pipeline across six LLMs on three decision tasks (hiring, loan approval, and university admissions). Our technique automatically discovers previously unknown biases in these models (e.g., Spanish fluency, English proficiency, writing formality). In the same run, the pipeline also validates biases that were manually identified by prior work (gender, race, religion, ethnicity). More broadly, our proposed approach provides a practical, scalable path to automatic task-specific bias discovery.