Optimistic World Models: Efficient Exploration in Model-Based Deep Reinforcement Learning
作者: Akshay Mete, Shahid Aamir Sheikh, Tzu-Hsiang Lin, Dileep Kalathil, P. R. Kumar
分类: cs.LG, cs.AI, eess.SY
发布日期: 2026-02-10
💡 一句话要点
提出乐观世界模型(OWMs),通过奖励偏置最大似然估计实现高效探索
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 世界模型 探索策略 奖励偏置 乐观探索
📋 核心要点
- 强化学习中,尤其是在稀疏奖励环境中,高效探索仍然是一个核心挑战。
- OWMs通过引入乐观动态损失,直接将乐观性融入模型学习,鼓励模型想象更高奖励的转换。
- 实验表明,乐观DreamerV3和乐观STORM在样本效率和累积回报方面优于其基线模型。
📝 摘要(中文)
本文提出乐观世界模型(OWMs),一个有原则且可扩展的乐观探索框架,将自适应控制中的经典奖励偏置最大似然估计(RBMLE)引入深度强化学习。与上限置信区间(UCB)式探索方法不同,OWMs通过增加乐观动态损失,直接将乐观性融入模型学习中,该损失偏向于奖励更高的想象转换。这种完全基于梯度的损失既不需要不确定性估计,也不需要约束优化。我们的方法可以即插即用,与现有的世界模型框架兼容,在保持可扩展性的同时,仅需对标准训练程序进行最小的修改。我们将OWMs实例化到两个最先进的世界模型架构中,从而产生了乐观DreamerV3和乐观STORM,与它们的基线相比,在样本效率和累积回报方面都表现出显著的改进。
🔬 方法详解
问题定义:强化学习,尤其是在稀疏奖励环境中,智能体难以有效地探索环境并找到最优策略。现有的基于不确定性的探索方法,如UCB,通常需要估计模型的不确定性,计算成本高昂,且在深度强化学习中难以准确估计。此外,约束优化方法也增加了训练的复杂性。
核心思路:论文的核心思路是将自适应控制中的奖励偏置最大似然估计(RBMLE)的思想引入到深度强化学习的世界模型中。通过在模型学习过程中引入一个乐观动态损失,鼓励模型学习到更有利于获得高奖励的转换,从而引导智能体进行更有效的探索。这种方法避免了显式地估计不确定性,而是通过奖励信号来隐式地引导探索。
技术框架:OWMs可以即插即用地集成到现有的世界模型框架中,如DreamerV3和STORM。整体流程包括:1) 使用环境数据训练世界模型,包括状态转移模型和奖励模型;2) 在训练状态转移模型时,除了标准的重构损失外,还加入一个乐观动态损失,该损失鼓励模型预测更高的奖励;3) 使用训练好的世界模型进行策略学习,例如通过模型预测控制(MPC)或策略梯度方法。
关键创新:最重要的技术创新点在于乐观动态损失的设计。与传统的基于不确定性的探索方法不同,OWMs直接将乐观性融入到模型学习过程中,避免了显式地估计不确定性。这种方法更加高效,且易于实现。此外,OWMs是完全基于梯度的,不需要约束优化,进一步简化了训练过程。
关键设计:乐观动态损失的具体形式为:L_optimistic = -λ * E[r(s', a')],其中λ是一个超参数,用于控制乐观程度,E[r(s', a')]表示在想象的转换(s', a')中获得的预期奖励。通过最小化这个损失,模型会被鼓励预测更高的奖励。论文中λ被设置为一个正值,使得模型倾向于学习能够带来更高奖励的转换。此外,论文还探索了不同的λ值对性能的影响。
🖼️ 关键图片

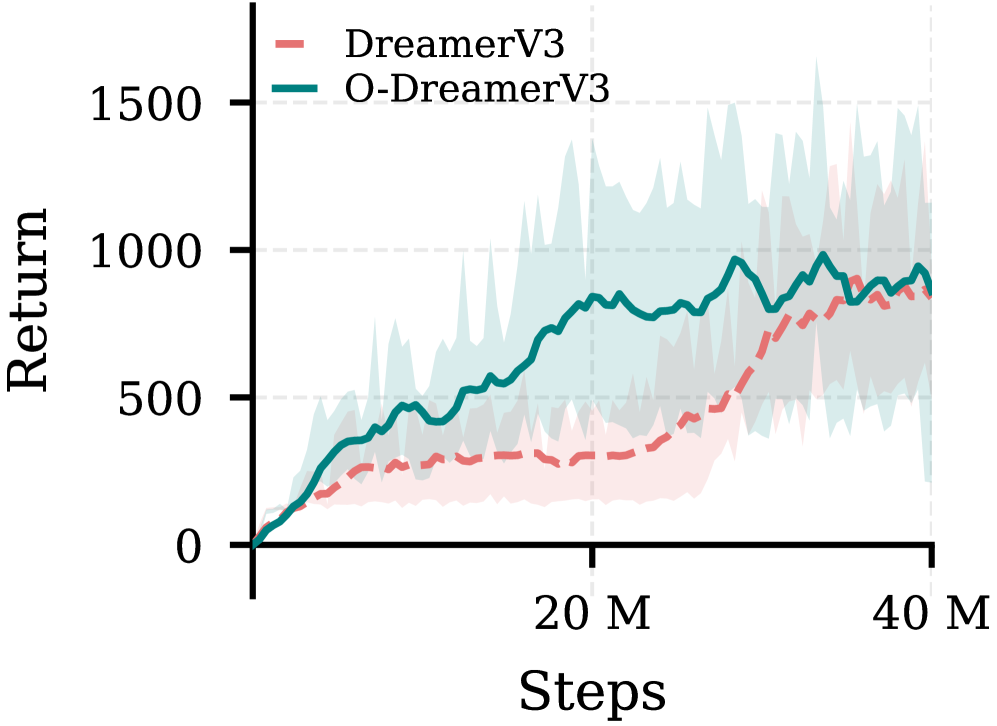
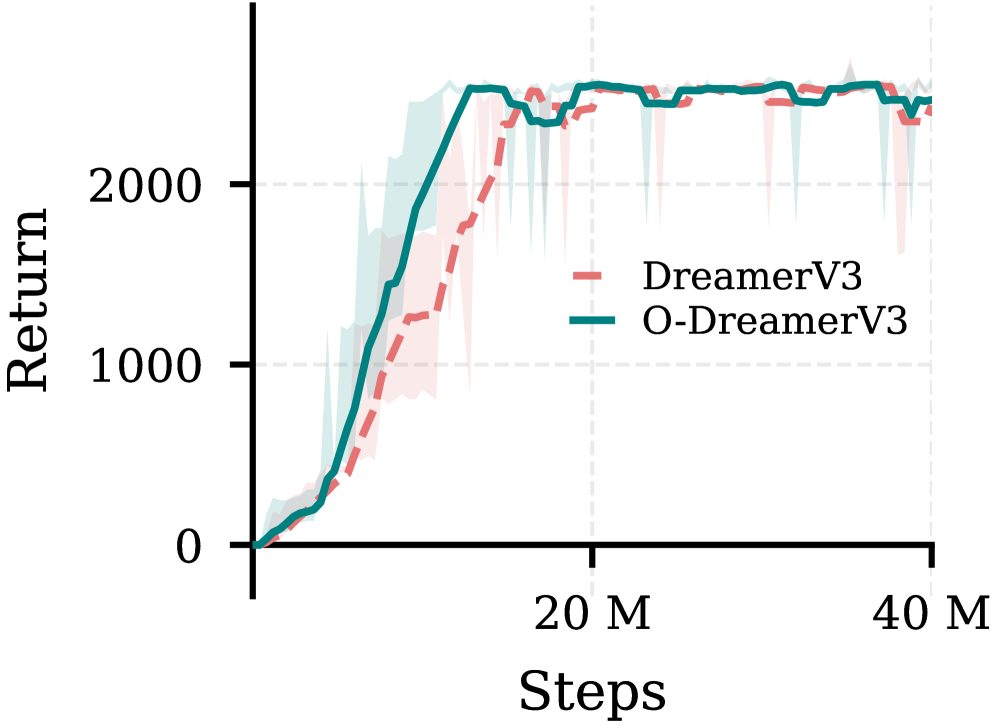
📊 实验亮点
实验结果表明,将OWMs集成到DreamerV3和STORM中,分别产生了乐观DreamerV3和乐观STORM,在多个benchmark任务上都取得了显著的性能提升。例如,在某些任务中,乐观DreamerV3的样本效率比DreamerV3提高了50%以上,累积回报也得到了显著提升。这些结果表明OWMs是一种有效的探索方法,能够显著提高强化学习的性能。
🎯 应用场景
OWMs具有广泛的应用前景,可以应用于机器人导航、游戏AI、自动驾驶等需要高效探索的强化学习任务中。该方法能够显著提高智能体在稀疏奖励环境中的学习效率,降低训练成本,并有望推动强化学习在更复杂和现实世界的场景中的应用。
📄 摘要(原文)
Efficient exploration remains a central challenge in reinforcement learning (RL), particularly in sparse-reward environments. We introduce Optimistic World Models (OWMs), a principled and scalable framework for optimistic exploration that brings classical reward-biased maximum likelihood estimation (RBMLE) from adaptive control into deep RL. In contrast to upper confidence bound (UCB)-style exploration methods, OWMs incorporate optimism directly into model learning by augmentation with an optimistic dynamics loss that biases imagined transitions toward higher-reward outcomes. This fully gradient-based loss requires neither uncertainty estimates nor constrained optimization. Our approach is plug-and-play with existing world model frameworks, preserving scalability while requiring only minimal modifications to standard training procedures. We instantiate OWMs within two state-of-the-art world model architectures, leading to Optimistic DreamerV3 and Optimistic STORM, which demonstrate significant improvements in sample efficiency and cumulative return compared to their baseline counterparts.