A Task-Centric Theory for Iterative Self-Improvement with Easy-to-Hard Curricula
作者: Chenruo Liu, Yijun Dong, Yiqiu Shen, Qi Lei
分类: cs.LG, stat.ML
发布日期: 2026-02-10
💡 一句话要点
提出基于任务中心的迭代自提升理论,利用由易到难课程学习提升LLM性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自提升 大语言模型 课程学习 有限样本保证 最大似然估计
📋 核心要点
- 现有自提升方法缺乏在有限样本下的理论保证,难以解释其有效性和局限性。
- 论文将自提升建模为奖励过滤分布上的最大似然微调,推导了预期奖励的有限样本保证。
- 研究表明,由易到难的课程学习在特定条件下优于固定任务混合训练,并通过实验验证。
📝 摘要(中文)
本文研究了迭代自提升方法,该方法通过在大语言模型(LLM)自身生成的、经过奖励验证的输出上进行微调来提升模型性能。尽管自提升在经验上取得了成功,但在实际的有限样本设置中,这种生成式的迭代过程的理论基础仍然有限。本文通过将每一轮自提升建模为在奖励过滤分布上的最大似然微调,并推导出预期奖励的有限样本保证,从而朝着这个目标迈进了一步。分析揭示了一个显式的反馈循环,其中更好的模型在每次迭代中接受更多数据,从而支持持续的自提升,同时也解释了这种提升的最终饱和。通过采用以任务为中心的视角,考虑具有多个难度级别的推理任务,进一步证明了在模型初始化、任务难度和样本预算方面的可量化条件,在这些条件下,由易到难的课程学习比在固定任务混合上训练能获得更好的保证。通过蒙特卡罗模拟和基于图的推理任务上的受控实验验证了分析结果。
🔬 方法详解
问题定义:现有自提升方法虽然在实践中表现良好,但缺乏坚实的理论基础,尤其是在有限样本情况下,其有效性、收敛性和局限性难以解释。现有方法难以确定何时以及为何自提升能够成功,以及如何设计更有效的自提升策略。
核心思路:论文的核心思路是将迭代自提升过程建模为一个在奖励过滤后的数据分布上的最大似然微调过程。通过这种建模,可以将自提升过程与统计学习理论联系起来,从而推导出有限样本保证,并分析自提升的收敛性和饱和现象。此外,论文还引入了任务难度的概念,并研究了由易到难的课程学习策略在自提升中的作用。
技术框架:论文的技术框架主要包含以下几个部分:1) 将自提升过程建模为奖励过滤分布上的最大似然微调;2) 推导预期奖励的有限样本保证;3) 分析自提升的收敛性和饱和现象;4) 研究由易到难的课程学习策略;5) 通过蒙特卡罗模拟和受控实验验证理论分析。
关键创新:论文的关键创新在于:1) 提出了一个基于任务中心的自提升理论框架,为理解和设计自提升策略提供了新的视角;2) 推导了预期奖励的有限样本保证,为自提升的有效性提供了理论支撑;3) 证明了由易到难的课程学习策略在特定条件下优于固定任务混合训练,为自提升策略的设计提供了指导。
关键设计:论文的关键设计包括:1) 使用奖励函数来过滤LLM生成的输出,从而选择高质量的训练数据;2) 使用最大似然估计来微调LLM,从而提高模型性能;3) 设计由易到难的课程学习策略,从而逐步提高任务难度,避免模型过早陷入局部最优。
🖼️ 关键图片
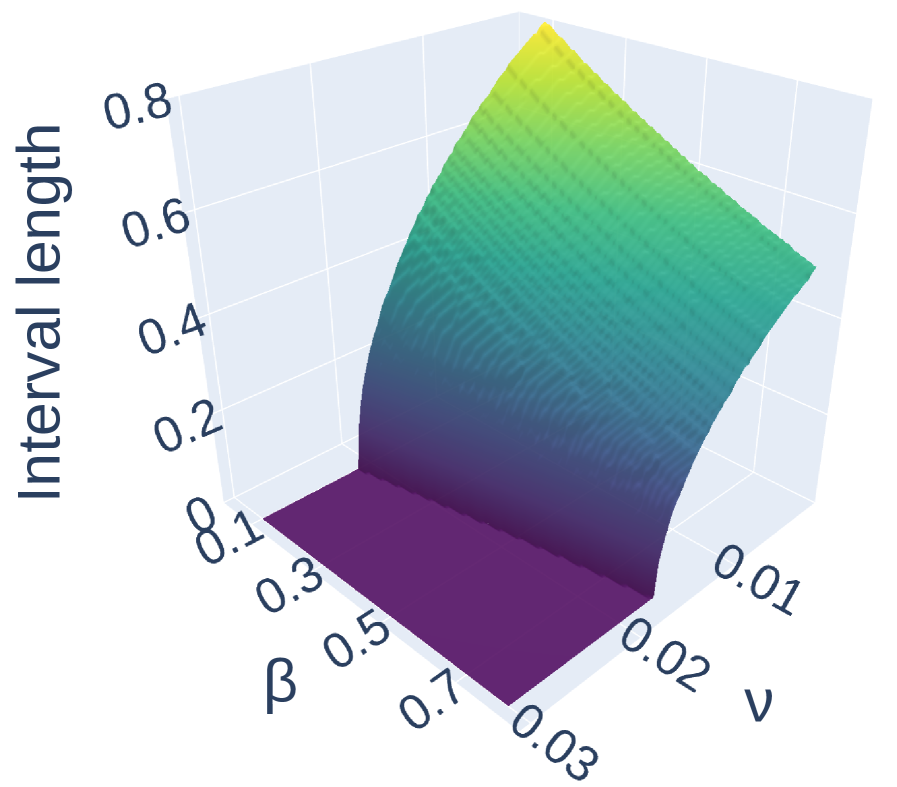

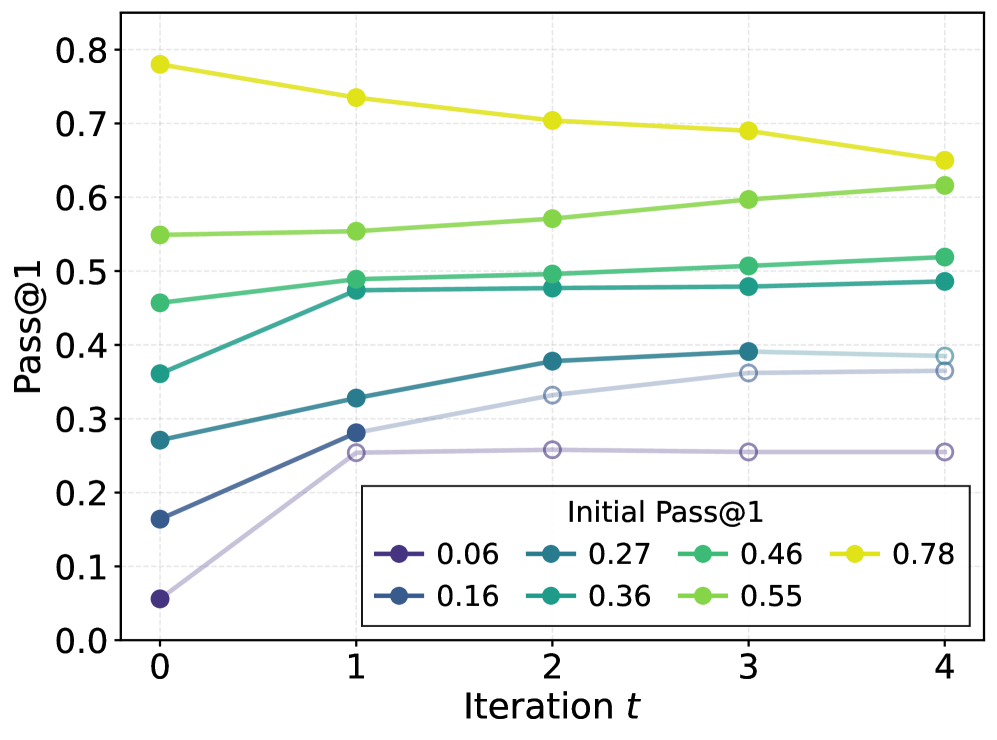
📊 实验亮点
论文通过蒙特卡罗模拟和基于图的推理任务上的受控实验验证了理论分析。实验结果表明,由易到难的课程学习策略在特定条件下能够显著提高LLM的性能,并且验证了有限样本保证的有效性。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于各种需要迭代自提升的场景,例如:智能对话系统、代码生成、文本摘要等。通过理论指导,可以设计更有效的自提升策略,提高LLM的性能和泛化能力。此外,由易到难的课程学习策略可以帮助LLM更好地学习复杂任务,降低训练成本。
📄 摘要(原文)
Iterative self-improvement fine-tunes an autoregressive large language model (LLM) on reward-verified outputs generated by the LLM itself. In contrast to the empirical success of self-improvement, the theoretical foundation of this generative, iterative procedure in a practical, finite-sample setting remains limited. We make progress toward this goal by modeling each round of self-improvement as maximum-likelihood fine-tuning on a reward-filtered distribution and deriving finite-sample guarantees for the expected reward. Our analysis reveals an explicit feedback loop where better models accept more data per iteration, supporting sustained self-improvement while explaining eventual saturation of such improvement. Adopting a task-centric view by considering reasoning tasks with multiple difficulty levels, we further prove quantifiable conditions on model initialization, task difficulty, and sample budget where easy-to-hard curricula provably achieve better guarantees than training on fixed mixtures of tasks. Our analyses are validated via Monte-Carlo simulations and controlled experiments on graph-based reasoning tasks.