Answer First, Reason Later: Aligning Search Relevance via Mode-Balanced Reinforcement Learning
作者: Shijie Zhang, Xiang Guo, Rujun Guo, Shaoyu Liu, Xiaozhao Wang, Guanjun Jiang, Kevin Zhang
分类: cs.LG
发布日期: 2026-02-10
💡 一句话要点
提出AFRL范式和Mode-Balanced RL,解决搜索排序中低延迟与高性能的平衡问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 搜索排序 强化学习 知识蒸馏 模式平衡 指令学习
📋 核心要点
- 现有搜索排序模型难以同时满足低延迟和高性能的需求,尤其是在需要可解释推理的情况下。
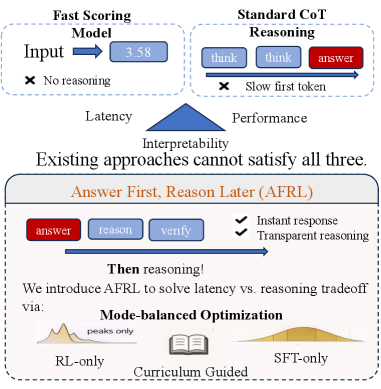
- 提出AFRL范式,模型先输出相关性得分,再进行逻辑解释,并采用模式平衡强化学习避免模式崩溃。
- 实验表明,AFRL范式在保证性能的同时,能够将知识蒸馏到小模型,实现低延迟部署。
📝 摘要(中文)
本文提出了一种新颖的“先回答,后推理”(Answer-First, Reason Later, AFRL)范式,旨在构建兼具低延迟和高性能的搜索排序模型。该范式要求模型在第一个token就输出最终的相关性得分,随后给出结构化的逻辑解释。借鉴推理模型的成功经验,采用“监督微调(SFT)+强化学习(RL)”流程实现AFRL。针对搜索排序任务中RL训练易出现的模式崩溃问题,提出了模式平衡优化策略,将SFT辅助损失融入Stepwise-GRPO训练中,平衡探索与利用。此外,构建了自动化指令进化系统和多阶段课程,确保数据质量。实验结果表明,32B教师模型取得了最先进的性能。AFRL架构支持高效的知识蒸馏,成功将专家级逻辑迁移到0.6B模型,兼顾了推理深度和部署延迟。
🔬 方法详解
问题定义:论文旨在解决搜索排序模型中低延迟和高性能难以兼顾的问题。现有方法要么牺牲推理深度以降低延迟,要么延迟过高无法满足在线系统的毫秒级响应要求。此外,直接应用强化学习进行训练容易导致模式崩溃,模型会为了追求高奖励而忘记复杂的长尾规则。
核心思路:论文的核心思路是采用“先回答,后推理”的AFRL范式,让模型首先输出最终的相关性得分,然后给出结构化的逻辑解释。通过这种方式,可以在保证推理能力的同时,显著降低延迟。为了解决RL训练中的模式崩溃问题,引入模式平衡优化策略,平衡探索和利用。
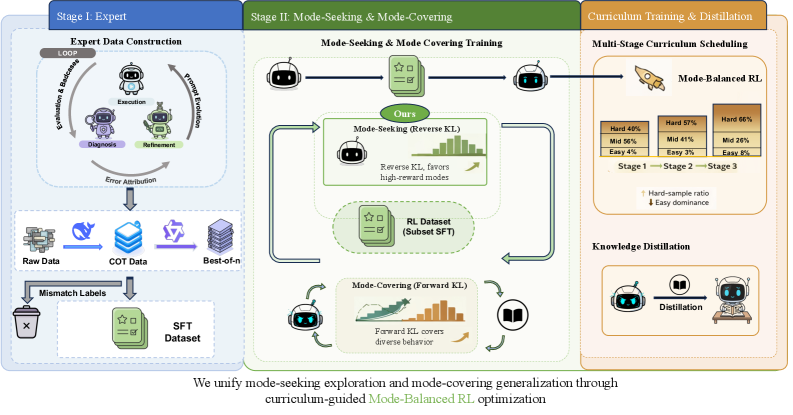
技术框架:整体框架包括数据准备、模型训练和知识蒸馏三个阶段。数据准备阶段,构建自动化指令进化系统和多阶段课程,生成高质量的训练数据。模型训练阶段,采用SFT+RL的流程,首先使用SFT进行预训练,然后使用Mode-Balanced RL进行微调。知识蒸馏阶段,将训练好的大模型知识迁移到小模型,实现低延迟部署。
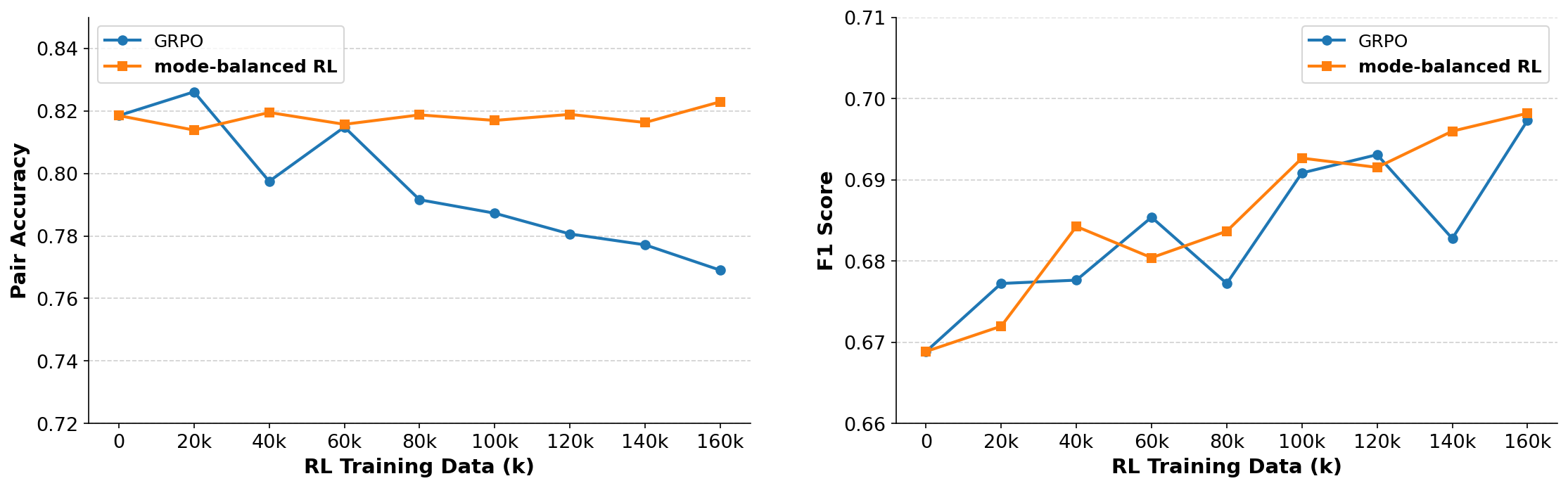
关键创新:最重要的技术创新点在于AFRL范式和Mode-Balanced Optimization策略。AFRL范式改变了传统的推理模式,实现了低延迟和高性能的平衡。Mode-Balanced Optimization策略通过引入SFT辅助损失,平衡了RL的模式寻求特性和SFT的模式覆盖特性,有效避免了模式崩溃。
关键设计:Mode-Balanced Optimization策略的关键在于SFT辅助损失的权重设置。论文将SFT辅助损失融入Stepwise-GRPO训练中,通过调整SFT损失的权重来平衡探索和利用。此外,自动化指令进化系统和多阶段课程的设计也至关重要,保证了训练数据的质量和多样性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,32B教师模型在搜索排序任务中取得了state-of-the-art的性能。更重要的是,通过AFRL架构,可以将专家级别的逻辑知识成功地蒸馏到一个0.6B的模型中,在推理深度和部署延迟之间取得了良好的平衡。这使得在实际应用中部署高性能、低延迟的搜索排序模型成为可能。
🎯 应用场景
该研究成果可应用于各种在线搜索和推荐系统,尤其是在对延迟有严格要求的场景下。通过AFRL范式和知识蒸馏,可以将复杂的推理逻辑部署到资源受限的设备上,提升用户体验,并为个性化推荐提供更强的可解释性。
📄 摘要(原文)
Building a search relevance model that achieves both low latency and high performance is a long-standing challenge in the search industry. To satisfy the millisecond-level response requirements of online systems while retaining the interpretable reasoning traces of Large Language Models (LLMs), we propose a novel \textbf{Answer-First, Reason Later (AFRL)} paradigm. This paradigm requires the model to output the definitive relevance score in the very first token, followed by a structured logical explanation. Inspired by the success of reasoning models, we adopt a "Supervised Fine-Tuning (SFT) + Reinforcement Learning (RL)" pipeline to achieve AFRL. However, directly applying existing RL training often leads to \textbf{mode collapse} in the search relevance task, where the model forgets complex long-tail rules in pursuit of high rewards. From an information theory perspective: RL inherently minimizes the \textbf{Reverse KL divergence}, which tends to seek probability peaks (mode-seeking) and is prone to "reward hacking." On the other hand, SFT minimizes the \textbf{Forward KL divergence}, forcing the model to cover the data distribution (mode-covering) and effectively anchoring expert rules. Based on this insight, we propose a \textbf{Mode-Balanced Optimization} strategy, incorporating an SFT auxiliary loss into Stepwise-GRPO training to balance these two properties. Furthermore, we construct an automated instruction evolution system and a multi-stage curriculum to ensure expert-level data quality. Extensive experiments demonstrate that our 32B teacher model achieves state-of-the-art performance. Moreover, the AFRL architecture enables efficient knowledge distillation, successfully transferring expert-level logic to a 0.6B model, thereby reconciling reasoning depth with deployment latency.