A Controlled Study of Double DQN and Dueling DQN Under Cross-Environment Transfer
作者: Azka Nasir, Fatima Dossa, Muhammad Ahmed Atif, Mohammad Ahmed Atif
分类: cs.LG, cs.AI
发布日期: 2026-02-10
💡 一句话要点
对比DDQN与Dueling DQN在跨环境迁移中的表现差异
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 迁移学习 Double DQN Dueling DQN 负迁移 架构归纳偏置 跨环境迁移
📋 核心要点
- 深度强化学习迁移学习面临领域差异带来的负迁移问题,现有方法难以保证跨环境迁移的稳定性。
- 本文对比DDQN和Dueling DQN在跨环境迁移中的表现,研究架构差异对迁移学习的影响。
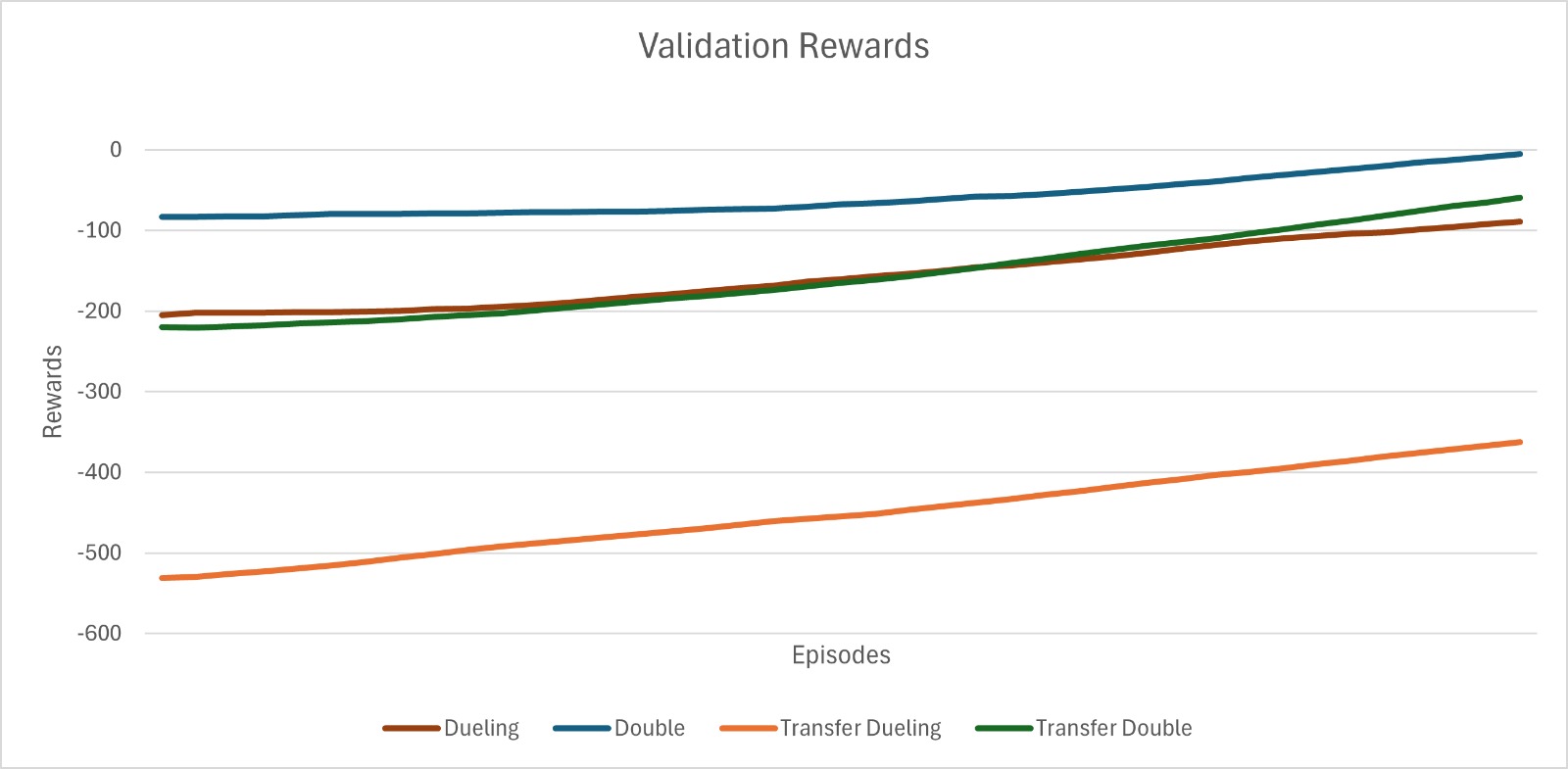
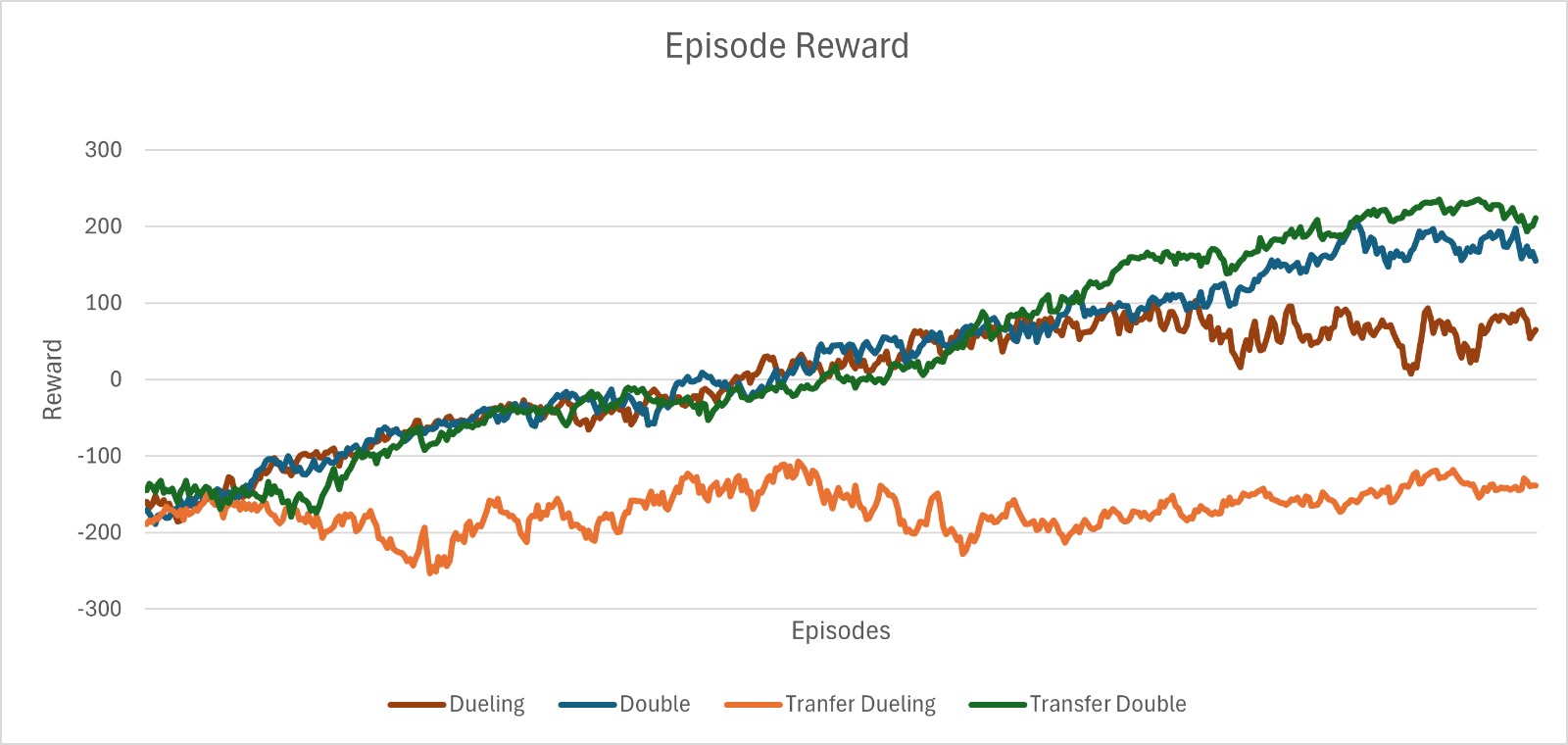
- 实验表明,DDQN能避免负迁移,保持学习动态;Dueling DQN则出现负迁移,奖励降低且优化不稳定。
📝 摘要(中文)
深度强化学习中的迁移学习通常旨在提高稳定性和降低训练成本,但也可能在领域差异较大时失效。本文进行了一项受控的实证研究,考察了Double Deep Q-Networks (DDQN)和Dueling DQN之间的架构差异如何影响跨环境的迁移行为。使用CartPole作为源任务,LunarLander作为结构上不同的目标任务,我们在相同的超参数和训练条件下评估了固定的分层表示迁移协议,并使用从头开始训练的基线智能体来分析迁移效果。实验结果表明,在所研究的设置下,DDQN始终避免了负迁移,并保持了与目标环境中基线性能相当的学习动态。相比之下,Dueling DQN在相同的条件下始终表现出负迁移,其特征是奖励降低和优化行为不稳定。跨多个随机种子的统计分析证实了迁移下的显著性能差距。这些发现表明,在所研究的迁移协议下,架构归纳偏置与基于价值的深度强化学习中跨环境迁移的鲁棒性密切相关。
🔬 方法详解
问题定义:论文旨在研究深度强化学习中,在源环境训练好的智能体迁移到目标环境时,由于环境差异可能导致的负迁移问题。现有方法在处理具有显著领域差异的环境时,往往难以保证迁移的有效性和稳定性,导致性能下降甚至不如从头开始训练。
核心思路:论文的核心思路是通过对比具有不同架构的两种深度Q网络(DDQN和Dueling DQN)在跨环境迁移中的表现,来探究架构归纳偏置对迁移学习鲁棒性的影响。通过控制超参数和训练条件,着重分析两种网络在面对结构差异较大的环境时的迁移行为。
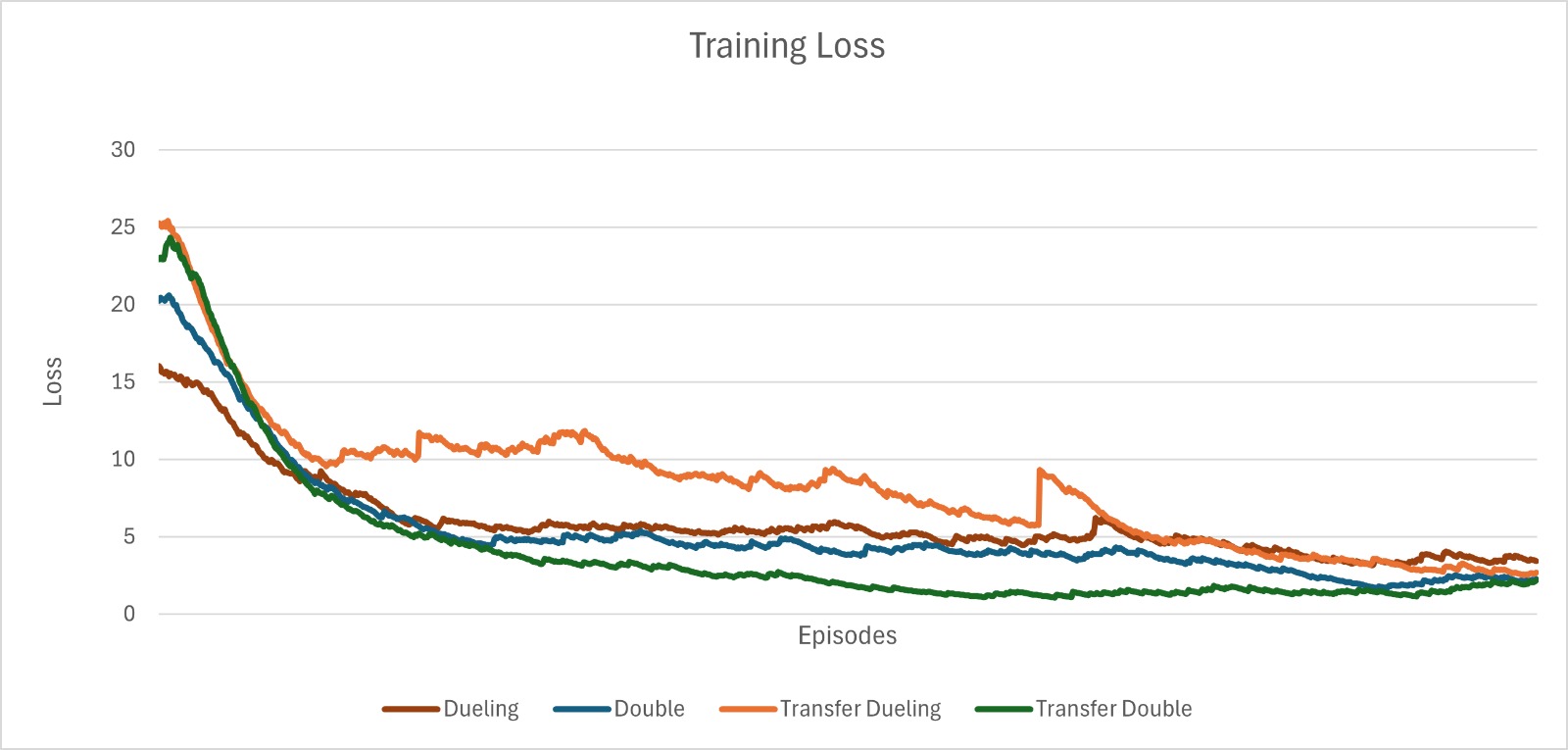
技术框架:整体框架包括:1) 在源环境(CartPole)上预训练DDQN和Dueling DQN;2) 将预训练模型的网络层参数迁移到目标环境(LunarLander);3) 在目标环境中使用迁移后的模型进行训练;4) 对比迁移学习和从头开始训练的基线模型的性能,评估迁移效果。
关键创新:论文的关键创新在于通过受控实验,揭示了DDQN和Dueling DQN这两种常用深度强化学习算法在跨环境迁移学习中表现出的显著差异。强调了架构归纳偏置在提升迁移学习鲁棒性方面的重要性,为后续研究提供了新的视角。
关键设计:实验中,源环境和目标环境分别选择了CartPole和LunarLander,这两个环境在状态空间、动作空间和动力学特性上存在显著差异。迁移策略采用固定的分层表示迁移,即直接将预训练模型的网络层参数复制到目标环境的模型中。超参数和训练条件保持一致,以确保实验的公平性。通过多次随机种子运行,并进行统计分析,验证结果的可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在CartPole到LunarLander的跨环境迁移中,DDQN能够避免负迁移,保持与基线性能相当的学习动态。而Dueling DQN则表现出显著的负迁移,奖励值降低,优化过程不稳定。统计分析显示,两种算法在迁移学习下的性能差距具有统计显著性,验证了架构归纳偏置对迁移学习鲁棒性的影响。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI等领域,尤其是在需要将智能体从模拟环境迁移到真实环境,或从一个游戏迁移到另一个游戏时。通过选择合适的网络架构,可以提高迁移学习的效率和稳定性,降低训练成本,加速智能体的部署。
📄 摘要(原文)
Transfer learning in deep reinforcement learning is often motivated by improved stability and reduced training cost, but it can also fail under substantial domain shift. This paper presents a controlled empirical study examining how architectural differences between Double Deep Q-Networks (DDQN) and Dueling DQN influence transfer behavior across environments. Using CartPole as a source task and LunarLander as a structurally distinct target task, we evaluate a fixed layer-wise representation transfer protocol under identical hyperparameters and training conditions, with baseline agents trained from scratch used to contextualize transfer effects. Empirical results show that DDQN consistently avoids negative transfer under the examined setup and maintains learning dynamics comparable to baseline performance in the target environment. In contrast, Dueling DQN consistently exhibits negative transfer under identical conditions, characterized by degraded rewards and unstable optimization behavior. Statistical analysis across multiple random seeds confirms a significant performance gap under transfer. These findings suggest that architectural inductive bias is strongly associated with robustness to cross-environment transfer in value-based deep reinforcement learning under the examined transfer protocol.