Towards Poisoning Robustness Certification for Natural Language Generation
作者: Mihnea Ghitu, Matthew Wicker
分类: cs.LG
发布日期: 2026-02-10
💡 一句话要点
提出TPA算法,为自然语言生成提供可验证的投毒鲁棒性保证
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言生成 投毒攻击 鲁棒性认证 目标分区聚合 混合整数线性规划
📋 核心要点
- 现有认证投毒防御方法难以应对自然语言生成任务中序列预测和指数级输出空间的挑战。
- 提出目标分区聚合(TPA)算法,通过计算最小投毒预算来认证语言生成模型的有效性和稳定性。
- 实验证明TPA在代理工具调用和基于偏好的对齐等任务中,能够有效认证语言生成模型的鲁棒性。
📝 摘要(中文)
在安全敏感领域部署大型语言模型,理解自然语言生成(NLG)的可靠性至关重要。虽然经过认证的投毒防御为分类任务提供了可证明的鲁棒性边界,但它们从根本上不适用于自回归生成:它们无法处理序列预测或语言模型的指数级大的输出空间。为了建立一个用于认证自然语言生成的框架,我们形式化了两个安全属性:稳定性(对生成中任何变化的鲁棒性)和有效性(对有针对性的、有害变化的鲁棒性)。我们引入了目标分区聚合(TPA),这是第一个通过计算诱导特定有害类别、token或短语所需的最小投毒预算来认证有效性/目标攻击的算法。此外,我们使用混合整数线性规划(MILP)扩展了TPA,为多轮生成提供更严格的保证。在实验中,我们证明了TPA在各种设置中的有效性,包括:当攻击者修改高达0.5%的数据集时,认证代理工具调用的有效性,以及在基于偏好的对齐中认证8-token的稳定性范围。虽然推理时延迟仍然是一个开放的挑战,但我们的贡献使得在安全关键应用中认证部署语言模型成为可能。
🔬 方法详解
问题定义:论文旨在解决自然语言生成模型在面对投毒攻击时的鲁棒性问题。现有的认证防御方法主要针对分类任务,无法直接应用于自回归生成模型,因为它们无法处理序列预测和语言模型的巨大输出空间。因此,需要一种新的方法来为自然语言生成提供可验证的鲁棒性保证,特别是针对有目标的攻击。
核心思路:论文的核心思路是形式化自然语言生成的安全属性,包括稳定性和有效性,并设计一种算法来计算诱导特定有害行为所需的最小投毒预算。通过确定这个最小预算,可以为模型的鲁棒性提供一个可证明的下界。这种方法允许在部署前评估模型对特定攻击的抵抗能力。
技术框架:论文提出的技术框架主要包含以下几个阶段:1) 形式化自然语言生成的安全属性,定义稳定性和有效性。2) 提出目标分区聚合(TPA)算法,用于计算诱导特定有害类别、token或短语所需的最小投毒预算。3) 使用混合整数线性规划(MILP)扩展TPA,以提供更严格的多轮生成保证。4) 通过实验验证TPA在各种设置中的有效性。
关键创新:论文最重要的技术创新点是提出了目标分区聚合(TPA)算法,这是第一个能够为自然语言生成提供可验证的投毒鲁棒性保证的算法。与现有的认证防御方法不同,TPA专门设计用于处理自回归生成模型的序列预测和巨大输出空间。此外,使用MILP扩展TPA进一步提高了多轮生成的认证精度。
关键设计:TPA算法的关键设计在于如何有效地搜索所有可能的投毒样本,并计算诱导特定有害行为所需的最小预算。算法通过将输出空间划分为多个分区,并聚合这些分区的信息来估计最小预算。MILP扩展的关键在于如何将多轮生成过程建模为线性约束,以便使用MILP求解器找到最优解。具体的参数设置和损失函数细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
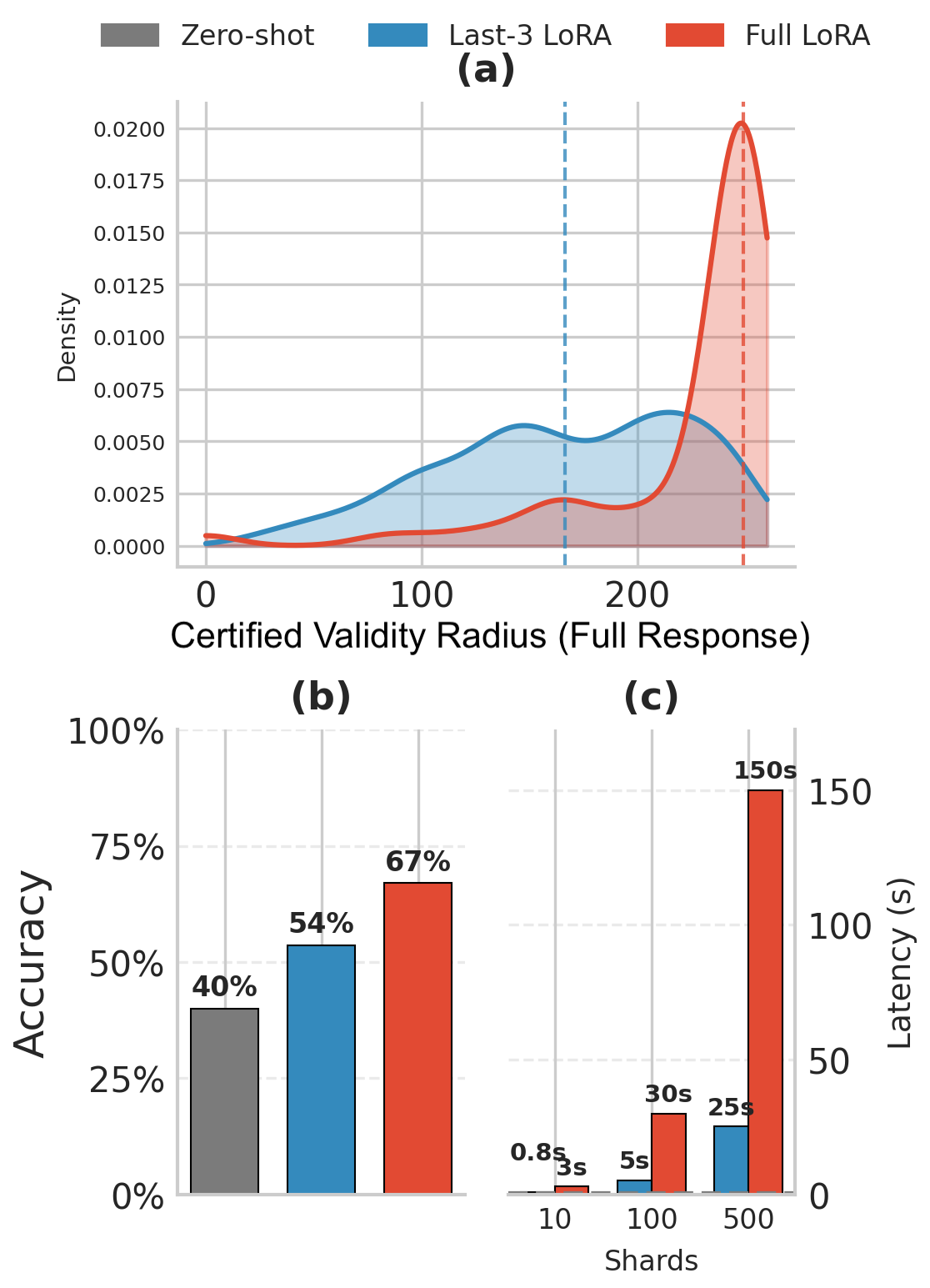
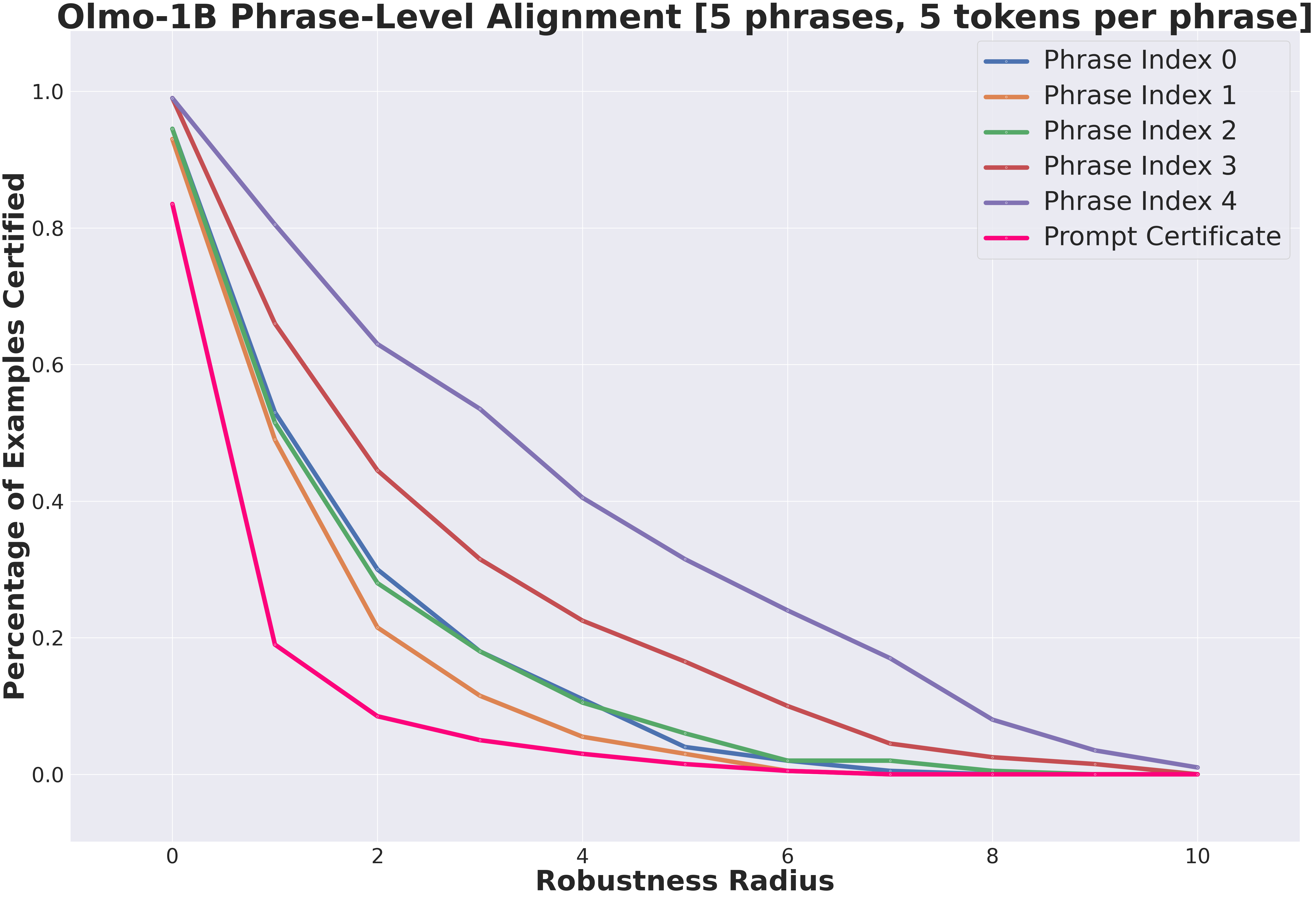
实验结果表明,TPA算法在代理工具调用任务中,能够有效认证模型在攻击者修改高达0.5%数据集时的有效性。此外,在基于偏好的对齐任务中,TPA能够认证8-token的稳定性范围。这些结果证明了TPA在不同场景下为自然语言生成提供可验证鲁棒性保证的有效性。
🎯 应用场景
该研究成果可应用于安全关键的自然语言生成任务,例如智能助手、对话系统和代码生成。通过认证模型的鲁棒性,可以确保模型在面对恶意攻击时仍能安全可靠地运行,避免生成有害或不准确的内容。这对于在金融、医疗和法律等敏感领域部署语言模型至关重要。
📄 摘要(原文)
Understanding the reliability of natural language generation is critical for deploying foundation models in security-sensitive domains. While certified poisoning defenses provide provable robustness bounds for classification tasks, they are fundamentally ill-equipped for autoregressive generation: they cannot handle sequential predictions or the exponentially large output space of language models. To establish a framework for certified natural language generation, we formalize two security properties: stability (robustness to any change in generation) and validity (robustness to targeted, harmful changes in generation). We introduce Targeted Partition Aggregation (TPA), the first algorithm to certify validity/targeted attacks by computing the minimum poisoning budget needed to induce a specific harmful class, token, or phrase. Further, we extend TPA to provide tighter guarantees for multi-turn generations using mixed integer linear programming (MILP). Empirically, we demonstrate TPA's effectiveness across diverse settings including: certifying validity of agent tool-calling when adversaries modify up to 0.5% of the dataset and certifying 8-token stability horizons in preference-based alignment. Though inference-time latency remains an open challenge, our contributions enable certified deployment of language models in security-critical applications.