ExO-PPO: an Extended Off-policy Proximal Policy Optimization Algorithm
作者: Hanyong Wang, Menglong Yang
分类: cs.LG, cs.AI
发布日期: 2026-02-10
💡 一句话要点
ExO-PPO:一种扩展的Off-policy近端策略优化算法,提升样本效率和稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 近端策略优化 Off-policy学习 样本效率 策略优化
📋 核心要点
- 深度强化学习调参困难,PPO虽稳定但样本效率低,Off-policy方法虽能提高样本利用率,但方差和偏差较高。
- ExO-PPO结合On-policy的稳定性和Off-policy的效率,通过扩展的Off-policy改进和分段指数函数裁剪机制实现。
- 实验表明,ExO-PPO在多种任务上,相较于PPO和其他先进变体,实现了样本效率和稳定性的平衡。
📝 摘要(中文)
深度强化学习在解决各种任务中取得了成功,但由于策略梯度构建和训练动态,深度强化学习模型的调整仍然具有挑战性。近端策略优化算法(PPO)是最成功的深度强化学习算法之一,它将策略梯度限制在保守的on-policy更新范围内,从而确保可靠和稳定的策略改进。然而,这种训练模式可能会牺牲样本效率。另一方面,off-policy方法通过样本重用更充分地利用数据,但代价是增加了估计方差和偏差。为了利用两者的优点,在本文中,我们提出了一种新的PPO变体,它基于保守on-policy迭代的稳定性保证,并具有更高效的off-policy数据利用率。具体来说,我们首先从广义策略改进下界的期望形式推导出扩展的off-policy改进。然后,我们使用分段指数函数扩展了裁剪机制,以获得合适的替代目标函数。第三,将过去M个策略生成的轨迹组织在回放缓冲区中,用于off-policy训练。我们将此方法称为扩展的Off-policy近端策略优化(ExO-PPO)。与PPO和其他一些最先进的变体相比,我们在实证实验中证明了ExO-PPO在各种任务中具有改进的性能,并平衡了样本效率和稳定性。
🔬 方法详解
问题定义:PPO算法作为一种On-policy算法,虽然具有训练稳定性的优点,但是其样本效率较低,限制了其在一些需要大量交互才能学习的任务上的应用。而Off-policy算法虽然可以提高样本利用率,但是容易引入偏差和方差,导致训练不稳定。因此,如何结合On-policy和Off-policy的优点,提高样本效率的同时保证训练的稳定性,是本文要解决的问题。
核心思路:ExO-PPO的核心思路是利用Off-policy数据来加速PPO的训练过程,同时通过一些机制来保证训练的稳定性。具体来说,首先从广义策略改进下界推导出扩展的Off-policy改进,然后使用分段指数函数来扩展PPO的裁剪机制,最后使用回放缓冲区来存储过去策略生成的轨迹,用于Off-policy训练。
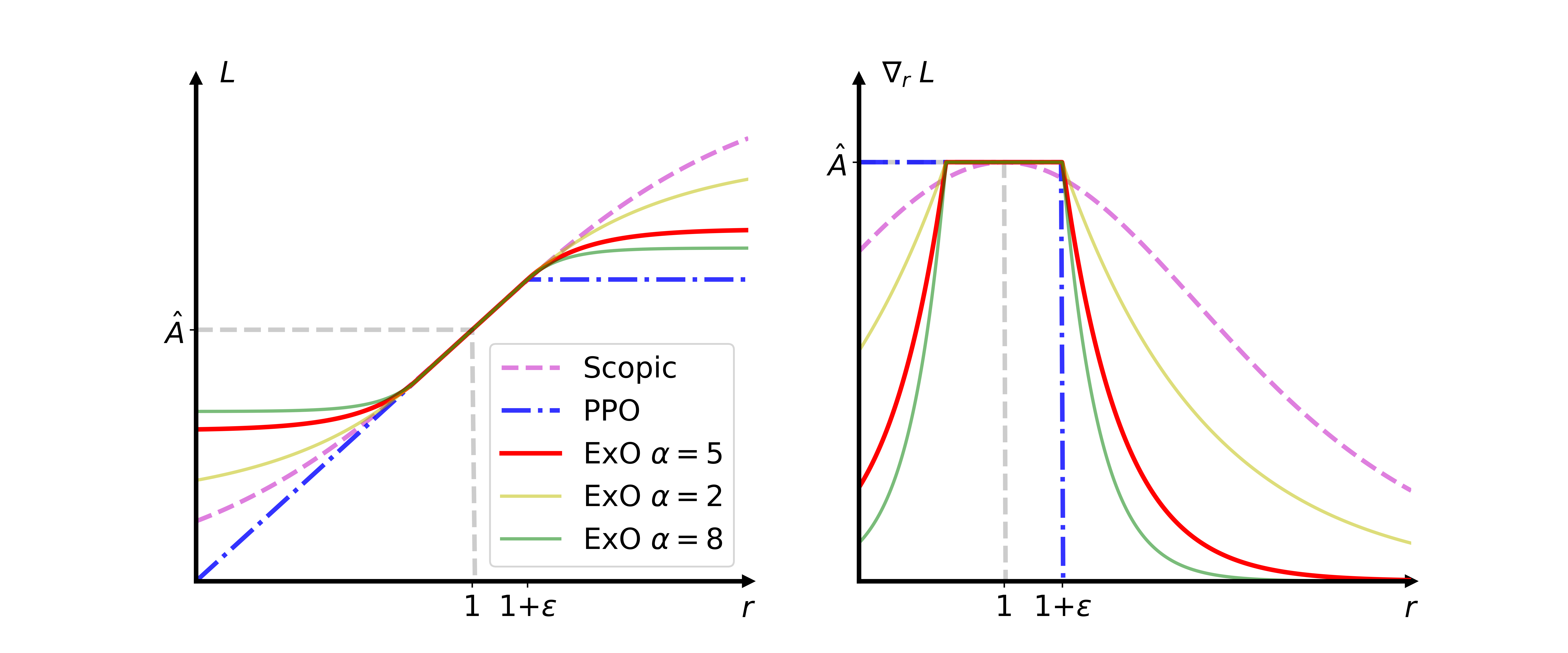
技术框架:ExO-PPO的整体框架可以分为三个主要部分:1)扩展的Off-policy改进:从广义策略改进下界推导出扩展的Off-policy改进,用于更新策略;2)分段指数函数裁剪机制:使用分段指数函数来扩展PPO的裁剪机制,用于限制策略更新的幅度,保证训练的稳定性;3)回放缓冲区:使用回放缓冲区来存储过去策略生成的轨迹,用于Off-policy训练。
关键创新:ExO-PPO的关键创新在于将Off-policy学习融入到PPO框架中,并设计了相应的机制来保证训练的稳定性。具体来说,扩展的Off-policy改进使得算法可以利用Off-policy数据来加速训练,而分段指数函数裁剪机制则可以限制策略更新的幅度,避免训练过程中的不稳定现象。
关键设计:ExO-PPO的关键设计包括:1)扩展的Off-policy改进的推导过程;2)分段指数函数的具体形式和参数设置;3)回放缓冲区的大小和更新策略;4)目标函数的构建和优化方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ExO-PPO在多个强化学习任务上都取得了优于PPO和其他先进算法的性能。例如,在MuJoCo连续控制任务中,ExO-PPO在样本效率和最终性能上都优于PPO。具体而言,ExO-PPO在达到与PPO相同的性能水平时,所需的样本数量更少,并且最终能够达到更高的性能。
🎯 应用场景
ExO-PPO算法可应用于各种需要高样本效率和稳定性的强化学习任务中,例如机器人控制、游戏AI、自动驾驶等。该算法能够加速智能体的学习过程,降低训练成本,并提高智能体的性能。未来,该算法有望在更多实际场景中得到应用,推动人工智能技术的发展。
📄 摘要(原文)
Deep reinforcement learning has been able to solve various tasks successfully, however, due to the construction of policy gradient and training dynamics, tuning deep reinforcement learning models remains challenging. As one of the most successful deep reinforcement-learning algorithm, the Proximal Policy Optimization algorithm (PPO) clips the policy gradient within a conservative on-policy updates, which ensures reliable and stable policy improvement. However, this training pattern may sacrifice sample efficiency. On the other hand, off-policy methods make more adequate use of data through sample reuse, though at the cost of increased the estimation variance and bias. To leverage the advantages of both, in this paper, we propose a new PPO variant based on the stability guarantee from conservative on-policy iteration with a more efficient off-policy data utilization. Specifically, we first derive an extended off-policy improvement from an expectation form of generalized policy improvement lower bound. Then, we extend the clipping mechanism with segmented exponential functions for a suitable surrogate objective function. Third, the trajectories generated by the past $M$ policies are organized in the replay buffer for off-policy training. We refer to this method as Extended Off-policy Proximal Policy Optimization (ExO-PPO). Compared with PPO and some other state-of-the-art variants, we demonstrate an improved performance of ExO-PPO with balanced sample efficiency and stability on varied tasks in the empirical experiments.