LLM-FS: Zero-Shot Feature Selection for Effective and Interpretable Malware Detection
作者: Naveen Gill, Ajvad Haneef K, Madhu Kumar S D
分类: cs.LG, cs.CR
发布日期: 2026-02-10
💡 一句话要点
提出LLM-FS:一种零样本特征选择方法,用于有效且可解释的恶意软件检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 恶意软件检测 特征选择 大型语言模型 零样本学习 可解释性 安全应用 自然语言处理
📋 核心要点
- 传统特征选择方法依赖统计启发式或模型驱动的得分,忽略了特征的语义信息,在高维恶意软件检测中表现受限。
- 利用大型语言模型(LLM)的语义理解能力,在零样本设置下,仅通过特征名称和任务描述指导特征选择。
- 实验表明,LLM指导的零样本特征选择在性能上与传统方法相当,同时提升了可解释性和稳定性。
📝 摘要(中文)
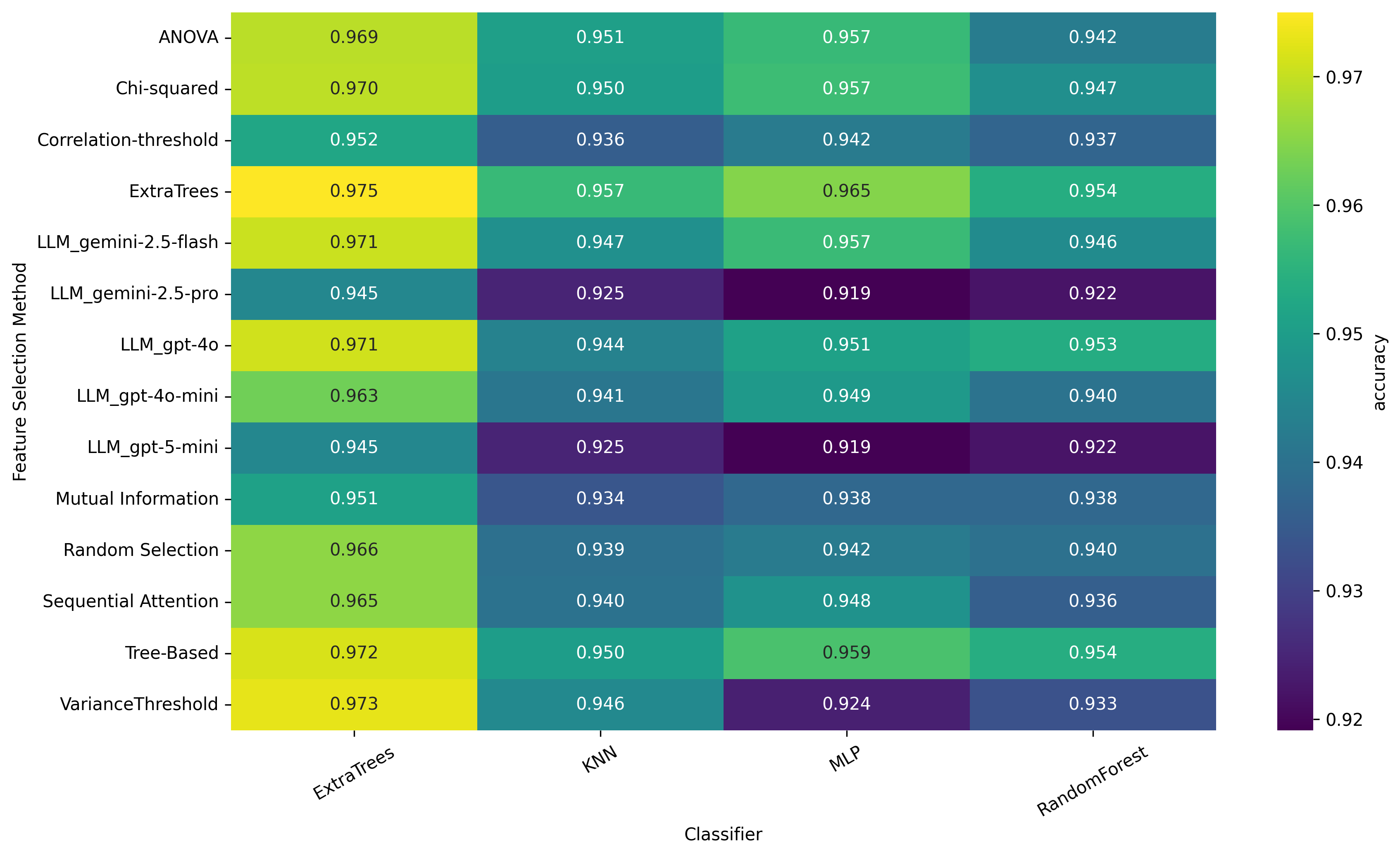
特征选择(FS)对于构建准确且可解释的检测模型至关重要,尤其是在高维恶意软件数据集中。传统的FS方法,如Extra Trees、方差阈值、基于树的模型、卡方检验、ANOVA、随机选择和序列注意力,主要依赖于统计启发式或模型驱动的重要性得分,常常忽略特征的语义上下文。受LLM驱动的FS最新进展的启发,我们研究了大型语言模型(LLM)是否可以在零样本设置下,仅使用特征名称和任务描述来指导特征选择,作为传统方法的可行替代方案。我们在EMBOD数据集(EMBER和BODMAS基准数据集的融合)上评估了多个LLM(GPT-5.0、GPT-4.0、Gemini-2.5等),并将它们与随机森林、Extra Trees、MLP和KNN等多种分类器上的既定FS方法进行比较。使用准确率、精确率、召回率、F1、AUC、MCC和运行时间来评估性能。结果表明,LLM指导的零样本特征选择在性能上与传统FS方法具有竞争力,同时在可解释性、稳定性和减少对标记数据的依赖性方面提供了额外的优势。这些发现将基于零样本LLM的FS定位为有效且可解释的恶意软件检测的一种有前途的替代策略,为安全关键应用中知识指导的特征选择铺平了道路。
🔬 方法详解
问题定义:论文旨在解决高维恶意软件检测中特征选择的问题。现有方法如Extra Trees等依赖统计或模型驱动的指标,忽略了特征的语义信息,导致选择的特征可能并非最优,且缺乏可解释性。此外,这些方法通常需要大量的标注数据进行训练,成本较高。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语义理解能力,直接从特征名称和任务描述中推断特征的重要性。通过将特征选择问题转化为LLM的自然语言理解和推理任务,避免了对大量标注数据的依赖,并提升了特征选择的可解释性。
技术框架:该方法的核心框架是:1) 输入特征名称和任务描述给LLM;2) LLM基于其预训练的知识和推理能力,对每个特征的重要性进行评估和排序;3) 选择LLM认为最重要的特征子集;4) 使用选择的特征子集训练恶意软件检测模型(如随机森林、MLP等)并评估性能。
关键创新:该方法最重要的创新点在于利用LLM进行零样本特征选择。与传统方法不同,该方法不需要任何标注数据进行训练,而是直接利用LLM的预训练知识和推理能力来指导特征选择。这使得该方法具有更强的通用性和可扩展性,可以应用于各种不同的恶意软件检测任务。
关键设计:论文的关键设计包括:1) 选择合适的LLM模型(如GPT-4.0、Gemini-2.5等),并根据任务需求进行适当的prompt工程,以引导LLM进行特征重要性评估;2) 设计合适的评估指标,如准确率、精确率、召回率、F1值等,以全面评估特征选择的效果;3) 探索不同的特征子集选择策略,例如选择LLM认为最重要的前N个特征。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM指导的零样本特征选择方法在EMBOD数据集上取得了与传统特征选择方法相当甚至更优的性能。例如,在某些分类器上,该方法在准确率、F1值等方面均超过了传统方法。此外,该方法还具有更好的可解释性和稳定性,并且不需要大量的标注数据。
🎯 应用场景
该研究成果可应用于各种安全领域的恶意软件检测、入侵检测等场景,尤其适用于缺乏标注数据的场景。通过利用LLM的知识,可以快速构建有效且可解释的检测模型,降低安全分析的成本,并提升安全防护的效率。未来,该方法还可以扩展到其他安全任务,如漏洞挖掘、威胁情报分析等。
📄 摘要(原文)
Feature selection (FS) remains essential for building accurate and interpretable detection models, particularly in high-dimensional malware datasets. Conventional FS methods such as Extra Trees, Variance Threshold, Tree-based models, Chi-Squared tests, ANOVA, Random Selection, and Sequential Attention rely primarily on statistical heuristics or model-driven importance scores, often overlooking the semantic context of features. Motivated by recent progress in LLM-driven FS, we investigate whether large language models (LLMs) can guide feature selection in a zero-shot setting, using only feature names and task descriptions, as a viable alternative to traditional approaches. We evaluate multiple LLMs (GPT-5.0, GPT-4.0, Gemini-2.5 etc.) on the EMBOD dataset (a fusion of EMBER and BODMAS benchmark datasets), comparing them against established FS methods across several classifiers, including Random Forest, Extra Trees, MLP, and KNN. Performance is assessed using accuracy, precision, recall, F1, AUC, MCC, and runtime. Our results demonstrate that LLM-guided zero-shot feature selection achieves competitive performance with traditional FS methods while offering additional advantages in interpretability, stability, and reduced dependence on labeled data. These findings position zero-shot LLM-based FS as a promising alternative strategy for effective and interpretable malware detection, paving the way for knowledge-guided feature selection in security-critical applications