Rollout-Training Co-Design for Efficient LLM-Based Multi-Agent Reinforcement Learning
作者: Zhida Jiang, Zhaolong Xing, Jiawei Lu, Yipei Niu, Qingyuan Sang, Liangxu Zhang, Wenquan Dai, Junhua Shu, Jiaxing Wang, Qiangyu Pei, Qiong Chen, Xinyu Liu, Fangming Liu, Ai Han, Zhen Chen, Ke Zhang
分类: cs.LG
发布日期: 2026-02-10
💡 一句话要点
FlexMARL:面向大规模LLM多智能体强化学习的高效Rollout-Training协同设计框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 大规模训练 LLM Rollout-Training协同 异步流水线
📋 核心要点
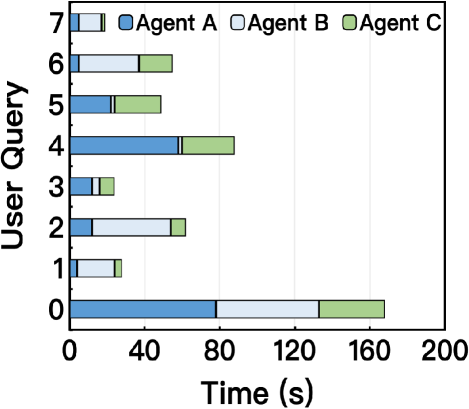
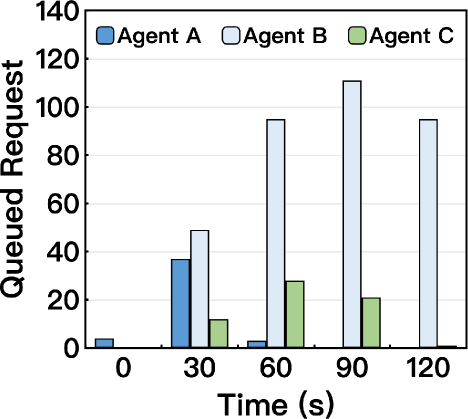
- 现有MARL训练框架主要针对单智能体场景优化,忽略了大规模MARL训练中rollout-training同步、负载不均衡和资源未充分利用等系统级挑战。
- FlexMARL通过联合编排器管理数据流,采用微批驱动的异步流水线消除同步障碍,并结合并行采样和分层负载均衡优化rollout效率。
- 实验结果表明,FlexMARL在大型生产集群上实现了高达7.3倍的加速,并将硬件利用率提高了高达5.6倍,显著提升了训练效率。
📝 摘要(中文)
本文提出FlexMARL,这是一个端到端的训练框架,旨在整体优化大规模基于LLM的多智能体强化学习(MARL)的rollout、训练及其编排。FlexMARL引入联合编排器来管理rollout-training分离架构下的数据流。基于经验存储,一种新型的微批驱动异步流水线消除了同步障碍,同时提供了强大的数据一致性保证。Rollout引擎采用并行采样方案,结合分层负载均衡,以适应倾斜的智能体间/内请求模式。训练引擎通过以智能体为中心的资源分配实现按需硬件绑定。不同智能体的训练状态通过统一且位置无关的通信进行交换。在大型生产集群上的实验结果表明,与现有框架相比,FlexMARL实现了高达7.3倍的加速,并将硬件利用率提高了高达5.6倍。
🔬 方法详解
问题定义:现有的大规模多智能体强化学习(MARL)训练框架,特别是基于大型语言模型(LLM)的MARL,在系统层面存在诸多挑战。这些挑战包括:rollout阶段和training阶段的同步障碍,导致训练效率低下;rollout阶段的负载不均衡,某些智能体或某些请求的处理时间过长;以及训练资源的利用率不足,无法根据不同智能体的需求动态分配资源。这些问题限制了MARL在实际生产环境中的应用。
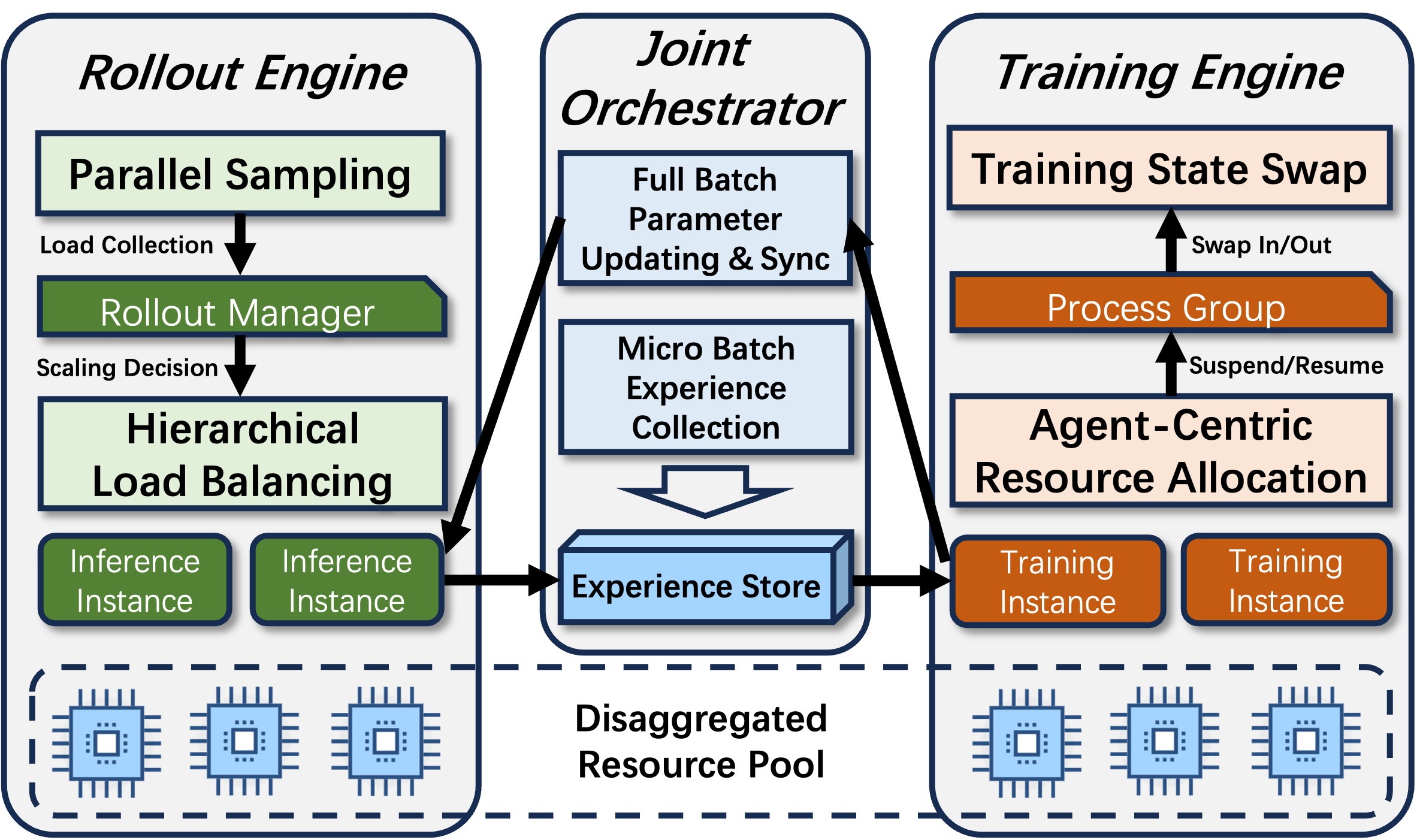
核心思路:FlexMARL的核心思路是通过rollout-training协同设计,打破传统MARL训练框架的瓶颈。它将rollout和training阶段解耦,并引入一个联合编排器来管理数据流,实现异步流水线处理。通过并行采样和分层负载均衡优化rollout效率,并通过智能体为中心的资源分配实现按需硬件绑定,从而提高资源利用率。
技术框架:FlexMARL的整体架构包含三个主要模块:rollout引擎、训练引擎和联合编排器。Rollout引擎负责生成训练数据,采用并行采样和分层负载均衡策略。训练引擎负责利用rollout数据更新模型参数,采用智能体为中心的资源分配策略。联合编排器负责管理rollout和training之间的数据流,实现异步流水线处理,并保证数据一致性。
关键创新:FlexMARL的关键创新在于其rollout-training协同设计理念和微批驱动的异步流水线。传统的MARL训练框架通常采用同步更新方式,导致rollout和training之间存在同步障碍。FlexMARL通过异步流水线消除了这些障碍,提高了训练效率。此外,FlexMARL的并行采样和分层负载均衡策略以及智能体为中心的资源分配策略也显著提高了rollout效率和资源利用率。
关键设计:FlexMARL的关键设计包括:1) 微批驱动的异步流水线,通过将训练数据分成微批,实现异步更新,并采用经验存储保证数据一致性;2) 并行采样和分层负载均衡,通过将rollout任务分配给多个worker并行执行,并根据智能体的请求模式动态调整负载;3) 智能体为中心的资源分配,根据不同智能体的计算需求动态分配硬件资源。
🖼️ 关键图片
📊 实验亮点
FlexMARL在大型生产集群上的实验结果表明,与现有框架相比,FlexMARL实现了高达7.3倍的加速,并将硬件利用率提高了高达5.6倍。这些显著的性能提升证明了FlexMARL在解决大规模MARL训练挑战方面的有效性。实验结果还表明,FlexMARL能够有效地处理倾斜的智能体间/内请求模式,并实现高效的资源利用。
🎯 应用场景
FlexMARL适用于需要大规模多智能体协作的复杂环境,例如:自动驾驶、机器人集群控制、大规模在线游戏、金融交易等。通过提高训练效率和资源利用率,FlexMARL能够加速这些领域的算法研发和部署,并降低训练成本。未来,FlexMARL有望推动LLM在MARL领域的更广泛应用,并促进相关技术的进步。
📄 摘要(原文)
Despite algorithm-level innovations for multi-agent reinforcement learning (MARL), the underlying networked infrastructure for large-scale MARL training remains underexplored. Existing training frameworks primarily optimize for single-agent scenarios and fail to address the unique system-level challenges of MARL, including rollout-training synchronization barriers, rollout load imbalance, and training resource underutilization. To bridge this gap, we propose FlexMARL, the first end-to-end training framework that holistically optimizes rollout, training, and their orchestration for large-scale LLM-based MARL. Specifically, FlexMARL introduces the joint orchestrator to manage data flow under the rollout-training disaggregated architecture. Building upon the experience store, a novel micro-batch driven asynchronous pipeline eliminates the synchronization barriers while providing strong consistency guarantees. Rollout engine adopts a parallel sampling scheme combined with hierarchical load balancing, which adapts to skewed inter/intra-agent request patterns. Training engine achieves on-demand hardware binding through agent-centric resource allocation. The training states of different agents are swapped via unified and location-agnostic communication. Empirical results on a large-scale production cluster demonstrate that FlexMARL achieves up to 7.3x speedup and improves hardware utilization by up to 5.6x compared to existing frameworks.