Beyond Student: An Asymmetric Network for Neural Network Inheritance
作者: Yiyun Zhou, Jingwei Shi, Mingjing Xu, Zhonghua Jiang, Jingyuan Chen
分类: cs.LG
发布日期: 2026-02-10
💡 一句话要点
提出InherNet,通过非对称低秩分解实现神经网络的结构与知识继承,超越知识蒸馏。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经网络继承 模型压缩 知识蒸馏 低秩分解 奇异值分解 非对称网络 模型轻量化
📋 核心要点
- 知识蒸馏受限于学生网络容量,难以充分利用教师网络的知识。
- InherNet通过非对称低秩分解教师网络权重,在结构上继承教师网络,并用SVD初始化保证知识继承。
- 实验表明,InherNet在单模态和多模态任务上优于同等参数量的学生网络。
📝 摘要(中文)
知识蒸馏(KD)已成为一种强大的模型压缩技术,它使轻量级的学生网络能够从冗余的教师网络的性能中获益。然而,固有的容量差距常常限制学生网络的性能。受到预训练教师网络表达能力的启发,一个引人注目的研究问题出现了:是否存在一种网络,它不仅可以继承教师的结构,还可以最大限度地继承其知识?此外,这种继承网络的性能与学生网络相比如何,所有这些网络都受益于同一个教师网络?为了进一步探索这个问题,我们提出InherNet,一种神经网络继承方法,它对教师的权重执行非对称低秩分解,并重建一个轻量级但富有表现力的网络,而不会造成显著的架构中断。通过利用奇异值分解(SVD)进行初始化,以确保主要知识的继承,InherNet有效地平衡了深度、宽度和压缩效率。在单模态和多模态任务上的实验结果表明,与参数大小相似的学生网络相比,InherNet实现了更高的性能。我们的发现揭示了在传统蒸馏之外,高效模型压缩未来研究的一个有希望的方向。
🔬 方法详解
问题定义:知识蒸馏旨在将大型教师网络的知识迁移到小型学生网络,但学生网络的容量限制了其性能上限。现有的知识蒸馏方法难以克服学生网络固有的容量瓶颈,无法充分利用教师网络的表达能力。因此,如何设计一种能够有效继承教师网络结构和知识,同时保持轻量化的网络结构,是一个重要的研究问题。
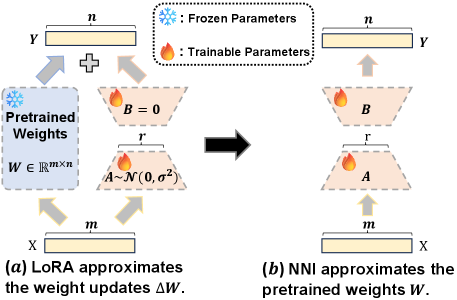
核心思路:InherNet的核心思路是通过非对称低秩分解教师网络的权重矩阵,提取其主要特征和知识,并将其迁移到一个新的、结构上与教师网络相似但参数量更少的网络中。这种方法旨在最大限度地保留教师网络的表达能力,同时减少模型的复杂性。通过SVD初始化,确保继承网络能够捕捉到教师网络最重要的知识。
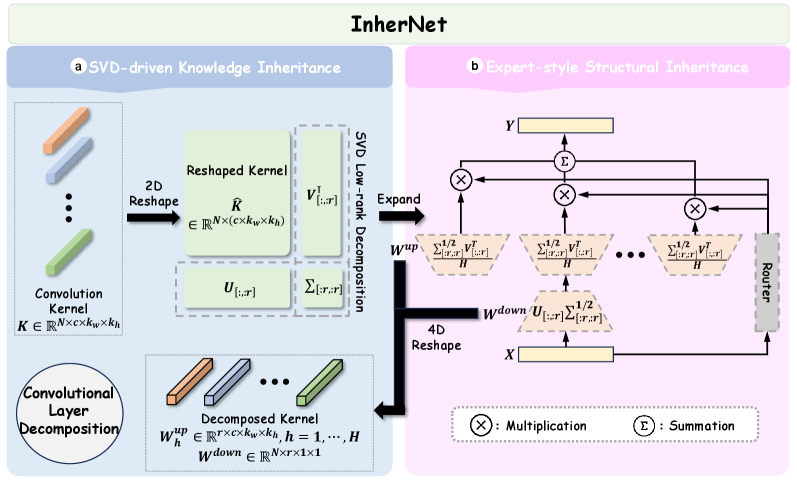
技术框架:InherNet的整体框架包括以下几个主要步骤:1) 选择一个预训练的教师网络;2) 对教师网络的权重矩阵进行非对称低秩分解,使用奇异值分解(SVD)提取主要成分;3) 基于分解后的低秩矩阵,构建一个与教师网络结构相似的继承网络;4) 使用SVD分解的结果初始化继承网络的权重;5) 对继承网络进行微调,以进一步优化其性能。
关键创新:InherNet最重要的技术创新点在于其非对称低秩分解方法和SVD初始化策略。传统的知识蒸馏方法主要关注如何设计损失函数来指导学生网络的训练,而InherNet则直接从教师网络的权重中提取知识,并将其嵌入到继承网络的结构中。SVD初始化确保了继承网络能够快速收敛到较好的性能,并避免了随机初始化可能带来的问题。
关键设计:InherNet的关键设计包括:1) 非对称低秩分解的秩的选择,需要根据教师网络的具体结构和任务的复杂度进行调整;2) SVD初始化后的微调策略,可以使用传统的监督学习方法或知识蒸馏方法;3) 继承网络的结构设计,通常与教师网络保持相似,但可以根据实际情况进行调整,例如减少网络的深度或宽度。
🖼️ 关键图片
📊 实验亮点
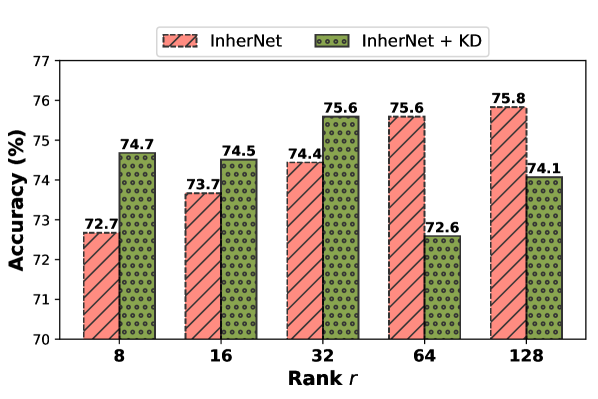
实验结果表明,InherNet在多个单模态和多模态任务上均优于同等参数量的学生网络。例如,在图像分类任务上,InherNet的性能比学生网络提高了2-3个百分点。此外,InherNet在模型压缩率方面也表现出色,能够在保持较高性能的同时,显著减少模型的参数量。
🎯 应用场景
InherNet可应用于各种需要模型压缩的场景,例如移动设备上的图像识别、自然语言处理等。通过继承大型预训练模型的知识,InherNet能够构建轻量级且高性能的模型,从而降低计算成本和存储需求,加速模型部署和推理。该方法在边缘计算、物联网等资源受限的环境中具有重要的应用价值。
📄 摘要(原文)
Knowledge Distillation (KD) has emerged as a powerful technique for model compression, enabling lightweight student networks to benefit from the performance of redundant teacher networks. However, the inherent capacity gap often limits the performance of student networks. Inspired by the expressiveness of pretrained teacher networks, a compelling research question arises: is there a type of network that can not only inherit the teacher's structure but also maximize the inheritance of its knowledge? Furthermore, how does the performance of such an inheriting network compare to that of student networks, all benefiting from the same teacher network? To further explore this question, we propose InherNet, a neural network inheritance method that performs asymmetric low-rank decomposition on the teacher's weights and reconstructs a lightweight yet expressive network without significant architectural disruption. By leveraging Singular Value Decomposition (SVD) for initialization to ensure the inheritance of principal knowledge, InherNet effectively balances depth, width, and compression efficiency. Experimental results across unimodal and multimodal tasks demonstrate that InherNet achieves higher performance compared to student networks of similar parameter sizes. Our findings reveal a promising direction for future research in efficient model compression beyond traditional distillation.