Towards Uniformity and Alignment for Multimodal Representation Learning
作者: Wenzhe Yin, Pan Zhou, Zehao Xiao, Jie Liu, Shujian Yu, Jan-Jakob Sonke, Efstratios Gavves
分类: cs.LG
发布日期: 2026-02-10
💡 一句话要点
提出解耦对齐与均匀性的多模态表征学习方法,缓解模态间分布差异。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态表征学习 对齐 均匀性 InfoNCE 跨模态检索
📋 核心要点
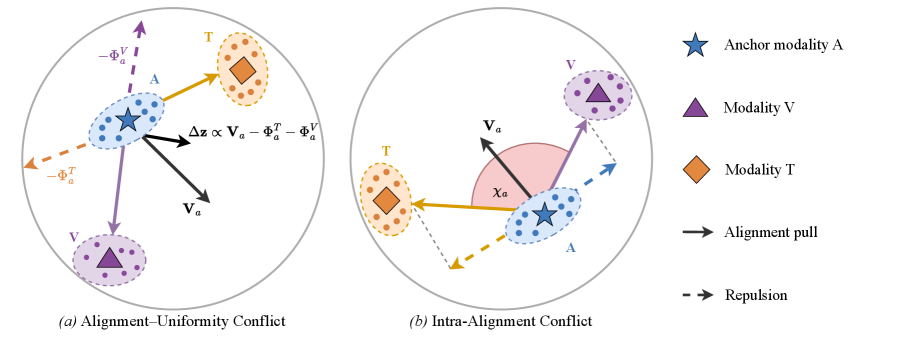
- 基于InfoNCE的多模态表征学习方法存在对齐-均匀性冲突和内部对齐冲突,导致模态间分布差距。
- 论文提出解耦对齐和均匀性的方法,避免模态间的冲突,从而更好地学习多模态表征。
- 实验结果表明,该方法在检索和UnCLIP风格生成任务上均取得了显著的性能提升。
📝 摘要(中文)
多模态表征学习旨在构建一个共享嵌入空间,其中异构模态在语义上对齐。尽管基于InfoNCE的目标取得了显著的经验结果,但它们引入了固有的冲突,导致模态间的分布差距。本文识别了多模态机制中的两个冲突,并且随着模态数量的增加而加剧:(i)对齐-均匀性冲突,即均匀性的排斥破坏了成对对齐;(ii)内部对齐冲突,即对齐多个模态会引起竞争性的对齐方向。为了解决这些问题,我们提出了一种原则性的对齐和均匀性解耦方法,为多模态表征学习提供了一种无冲突的方案,同时支持判别和生成用例,而无需特定于任务的模块。我们还提供了理论保证,证明我们的方法可以有效地代理多个模态分布上的全局Hölder散度,从而减少模态之间的分布差距。在检索和UnCLIP风格生成方面的广泛实验证明了一致的收益。
🔬 方法详解
问题定义:多模态表征学习旨在将来自不同模态的数据映射到共享的嵌入空间,以便进行跨模态检索、生成等任务。现有的基于InfoNCE的方法在多模态场景下存在两个主要问题:一是“对齐-均匀性冲突”,即为了保证嵌入空间的均匀性而排斥样本,反而会损害模态间的对齐;二是“内部对齐冲突”,即多个模态同时对齐时,不同模态之间存在竞争关系,导致对齐效果不佳。这些问题在高模态数量的情况下尤为突出。
核心思路:论文的核心思路是将多模态表征学习中的对齐(Alignment)和均匀性(Uniformity)这两个目标解耦。通过解耦,可以避免对齐和均匀性之间的相互干扰,从而更好地学习多模态表征。具体来说,论文设计了一种新的损失函数,该损失函数可以独立地控制对齐和均匀性,从而避免了它们之间的冲突。
技术框架:该方法没有明确的整体架构图,但其核心在于损失函数的设计。该损失函数由两部分组成:一部分负责模态间的对齐,另一部分负责保证嵌入空间的均匀性。这两部分损失函数是相互独立的,可以分别进行优化。该方法可以应用于各种多模态学习框架,无需引入特定于任务的模块。
关键创新:该论文的关键创新在于提出了对齐和均匀性解耦的思想,并设计了一种新的损失函数来实现这一目标。与现有方法相比,该方法可以更好地平衡对齐和均匀性,从而学习到更有效的多模态表征。此外,论文还提供了理论保证,证明该方法可以有效地代理多个模态分布上的全局Hölder散度,从而减少模态之间的分布差距。
关键设计:论文的关键设计在于损失函数的设计。具体来说,论文设计了一个包含对齐损失和均匀性损失的损失函数。对齐损失用于衡量不同模态之间的相似度,均匀性损失用于衡量嵌入空间中样本的分布情况。这两个损失函数的具体形式未知,需要参考原文。此外,论文还可能涉及到一些超参数的设置,例如对齐损失和均匀性损失的权重等。
🖼️ 关键图片


📊 实验亮点
论文在跨模态检索和UnCLIP风格生成任务上进行了实验,结果表明该方法能够显著提升性能。具体提升幅度未知,但摘要中提到“一致的收益”。实验结果验证了解耦对齐和均匀性的有效性,表明该方法能够学习到更有效的多模态表征。
🎯 应用场景
该研究成果可广泛应用于跨模态检索、多模态生成、视频理解、图像描述等领域。例如,在跨模态检索中,可以利用该方法学习到的多模态表征,实现文本到图像、图像到文本的检索。在多模态生成中,可以利用该方法生成与输入模态相关的其他模态数据。该研究有助于提升多模态人工智能系统的性能和鲁棒性。
📄 摘要(原文)
Multimodal representation learning aims to construct a shared embedding space in which heterogeneous modalities are semantically aligned. Despite strong empirical results, InfoNCE-based objectives introduce inherent conflicts that yield distribution gaps across modalities. In this work, we identify two conflicts in the multimodal regime, both exacerbated as the number of modalities increases: (i) an alignment-uniformity conflict, whereby the repulsion of uniformity undermines pairwise alignment, and (ii) an intra-alignment conflict, where aligning multiple modalities induces competing alignment directions. To address these issues, we propose a principled decoupling of alignment and uniformity for multimodal representations, providing a conflict-free recipe for multimodal learning that simultaneously supports discriminative and generative use cases without task-specific modules. We then provide a theoretical guarantee that our method acts as an efficient proxy for a global Hölder divergence over multiple modality distributions, and thus reduces the distribution gap among modalities. Extensive experiments on retrieval and UnCLIP-style generation demonstrate consistent gains.