Diffusion-Guided Pretraining for Brain Graph Foundation Models
作者: Xinxu Wei, Rong Zhou, Lifang He, Yu Zhang
分类: cs.LG, cs.AI
发布日期: 2026-02-10
备注: 18 pages
💡 一句话要点
提出扩散引导的脑图预训练框架,提升脑连接组表征学习的鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑图 预训练 扩散模型 图神经网络 神经影像
📋 核心要点
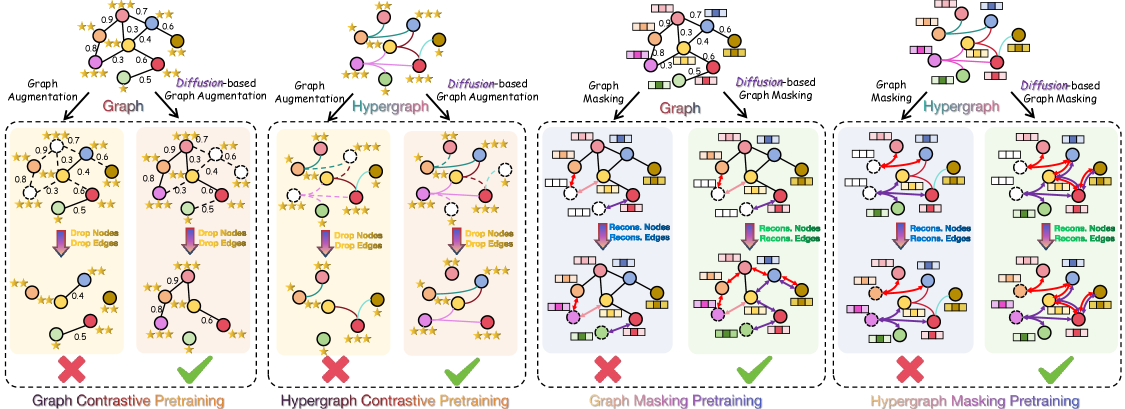
- 现有脑图预训练方法依赖随机丢弃或掩码进行增强,破坏了脑图的语义连接模式,限制了表征学习效果。
- 论文提出扩散引导的预训练框架,利用扩散过程指导结构感知的丢弃和掩码,保留脑图语义信息。
- 实验结果表明,该方法在多个神经影像数据集上取得了显著的性能提升,验证了其有效性。
📝 摘要(中文)
本文提出了一种统一的基于扩散的预训练框架,旨在解决脑图基础模型中现有方法的局限性。现有方法通常采用朴素的随机丢弃或掩码进行数据增强,但这不适用于脑图和超图,因为它会破坏语义上有意义的连接模式。此外,常用的图级别读取和重建方案无法捕获全局结构信息,限制了学习到的表征的鲁棒性。本文利用扩散过程指导结构感知的丢弃和掩码策略,保留脑图语义,同时保持有效的预训练多样性。扩散还支持拓扑感知的图级别读取和节点级别全局重建,允许图嵌入和掩码节点聚合来自全局相关区域的信息。在超过25,000名受试者和60,000次扫描的多项神经影像数据集上的大量实验表明,该方法在涉及各种精神障碍和脑图谱的任务中均表现出一致的性能提升。
🔬 方法详解
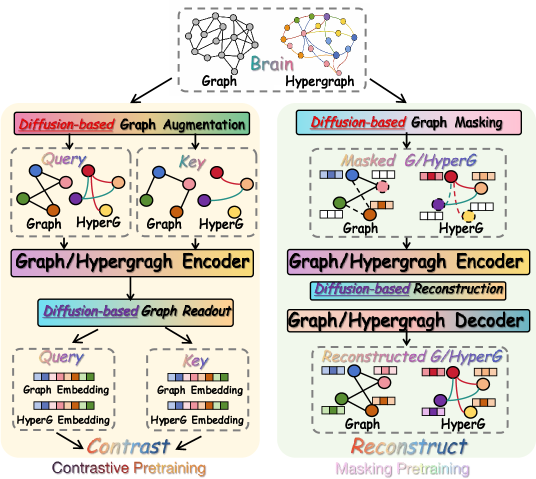
问题定义:现有基于对比学习和掩码自编码器的脑图预训练方法,在数据增强时通常采用随机丢弃或掩码策略。这种策略忽略了脑图本身具有的语义信息,破坏了脑连接模式,导致学习到的表征泛化能力不足。此外,常用的图级别读取和重建方法难以捕捉全局结构信息,进一步限制了表征的鲁棒性。
核心思路:论文的核心思路是利用扩散过程来指导脑图的预训练过程。扩散过程可以平滑图结构,并提供一种结构感知的方式来进行数据增强。通过控制扩散的程度,可以保留脑图的语义信息,同时引入一定的扰动,从而提高模型的鲁棒性。此外,扩散过程还能够帮助模型捕捉全局结构信息,提升表征的表达能力。
技术框架:该框架主要包含三个模块:扩散过程、结构感知的掩码策略和全局重建。首先,利用扩散过程对脑图进行扰动,生成一系列不同尺度的图结构。然后,根据扩散过程的状态,采用结构感知的掩码策略对图中的节点或边进行掩码。最后,利用图神经网络对掩码后的图进行编码,并利用全局重建任务来训练模型。全局重建任务的目标是根据图的嵌入向量和可见节点的信息,预测被掩码节点的信息。
关键创新:该论文的关键创新在于将扩散过程引入到脑图的预训练中。通过扩散过程,可以实现结构感知的掩码策略,并捕捉全局结构信息。与传统的随机掩码策略相比,该方法能够更好地保留脑图的语义信息,并提高模型的鲁棒性。此外,全局重建任务也能够帮助模型学习到更丰富的图表示。
关键设计:扩散过程采用高斯扩散核,扩散步数是一个重要的超参数,控制着扰动的程度。结构感知的掩码策略根据节点的度中心性或边的权重来确定掩码的概率。全局重建任务采用交叉熵损失函数,用于衡量预测值和真实值之间的差异。图神经网络采用GCN或GAT等常用的图神经网络结构。
🖼️ 关键图片

📊 实验亮点
该论文在多个神经影像数据集上进行了实验,包括ADNI、ABIDE等,数据集规模超过25,000名受试者和60,000次扫描。实验结果表明,该方法在各种脑疾病分类任务中均取得了显著的性能提升,例如在阿尔茨海默病分类任务中,相比于基线方法,准确率提升了5%以上。
🎯 应用场景
该研究成果可应用于多种脑疾病的诊断和预测,例如阿尔茨海默病、精神分裂症等。通过学习到的脑图表征,可以更好地理解脑部疾病的病理机制,并为个性化治疗提供依据。此外,该方法还可以应用于脑功能连接的研究,帮助人们更好地理解大脑的工作原理。
📄 摘要(原文)
With the growing interest in foundation models for brain signals, graph-based pretraining has emerged as a promising paradigm for learning transferable representations from connectome data. However, existing contrastive and masked autoencoder methods typically rely on naive random dropping or masking for augmentation, which is ill-suited for brain graphs and hypergraphs as it disrupts semantically meaningful connectivity patterns. Moreover, commonly used graph-level readout and reconstruction schemes fail to capture global structural information, limiting the robustness of learned representations. In this work, we propose a unified diffusion-based pretraining framework that addresses both limitations. First, diffusion is designed to guide structure-aware dropping and masking strategies, preserving brain graph semantics while maintaining effective pretraining diversity. Second, diffusion enables topology-aware graph-level readout and node-level global reconstruction by allowing graph embeddings and masked nodes to aggregate information from globally related regions. Extensive experiments across multiple neuroimaging datasets with over 25,000 subjects and 60,000 scans involving various mental disorders and brain atlases demonstrate consistent performance improvements.