Squeezing More from the Stream : Learning Representation Online for Streaming Reinforcement Learning
作者: Nilaksh, Antoine Clavaud, Mathieu Reymond, François Rivest, Sarath Chandar
分类: cs.LG, cs.AI
发布日期: 2026-02-10
备注: 8 pages, 4 figures
💡 一句话要点
针对流式强化学习,提出在线自预测表征学习方法,提升样本效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 流式强化学习 自预测表征 在线学习 表征学习 梯度正交化
📋 核心要点
- 流式强化学习因缺乏回放缓冲区,导致样本效率低,难以提取有效表征。
- 提出将自预测表征(SPR)扩展到流式管道,最大化每个帧的效用,学习更丰富的表征。
- 引入梯度正交更新和梯度冲突解决机制,避免训练不稳定,并在多个benchmark上超越现有方法。
📝 摘要(中文)
在流式强化学习(RL)中,转移样本在单次更新后立即被丢弃。虽然这最小化了设备上的资源使用,但也导致智能体样本效率低下,因为仅基于价值的损失函数难以从瞬态数据中提取有意义的表征。本文提出将自预测表征(SPR)扩展到流式管道,以最大化每个观察帧的效用。然而,由于流式机制导致的高度相关样本,直接应用这种辅助损失会导致训练不稳定。因此,我们引入了相对于动量目标的梯度正交更新,并解决了由流式特定优化器引起的梯度冲突。在Atari、MinAtar和Octax套件上的验证表明,我们的方法系统地优于现有的流式基线。包括t-SNE可视化和有效秩测量在内的潜在空间分析证实,我们的方法学习了更丰富的表征,弥合了因缺少回放缓冲区而导致的性能差距,同时保持了足够的效率,可以在几个CPU核心上进行训练。
🔬 方法详解
问题定义:流式强化学习面临着严重的样本效率问题。由于数据在更新后立即丢弃,智能体无法像传统强化学习那样利用回放缓冲区进行多次学习。这使得智能体难以从有限的、瞬态的数据中学习到有效的状态表征,从而影响整体性能。现有的基于价值的损失函数不足以解决这个问题,需要更有效的表征学习方法。
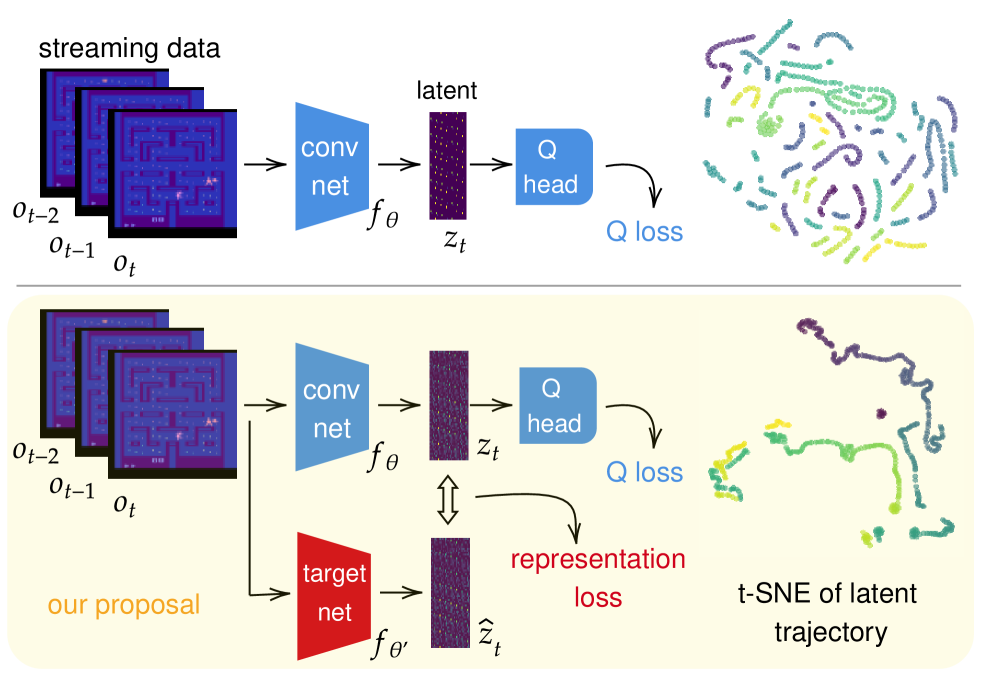
核心思路:本文的核心思路是利用自预测表征(SPR)来提升流式强化学习的样本效率。SPR通过预测自身未来的状态来学习更丰富的状态表征。通过最大化每个观察帧的效用,即使在没有回放缓冲区的情况下,也能从瞬态数据中提取更多信息。
技术框架:该方法将SPR作为辅助损失函数添加到现有的流式强化学习框架中。整体流程如下:1) 智能体与环境交互,获得状态转移样本;2) 使用状态转移样本更新价值函数;3) 使用SPR损失函数更新状态表征;4) 丢弃状态转移样本。关键在于SPR损失函数的引入,它与价值函数损失共同优化状态表征。
关键创新:主要的创新点在于将SPR成功应用于流式强化学习,并解决了由此带来的训练不稳定问题。由于流式数据的高度相关性,直接应用SPR会导致梯度爆炸或震荡。为了解决这个问题,本文提出了梯度正交更新策略,确保SPR的梯度与价值函数的梯度方向尽可能正交,避免梯度冲突。
关键设计:为了解决训练不稳定问题,论文引入了相对于动量目标的梯度正交更新。具体来说,计算SPR损失的梯度后,将其投影到与价值函数损失的动量梯度正交的空间中,然后再进行更新。此外,论文还针对流式特定优化器可能引起的梯度冲突,设计了相应的解决方案。这些设计保证了SPR能够稳定地提升状态表征的质量。
🖼️ 关键图片
📊 实验亮点
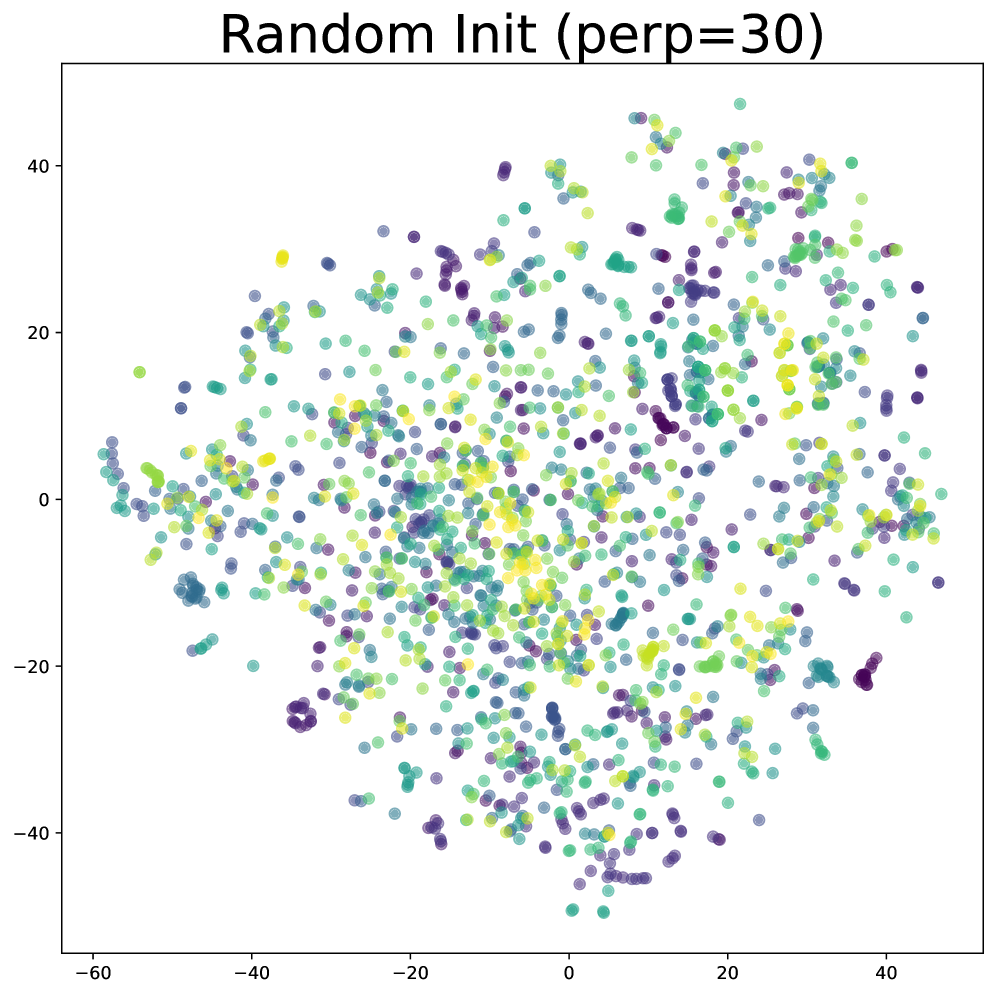
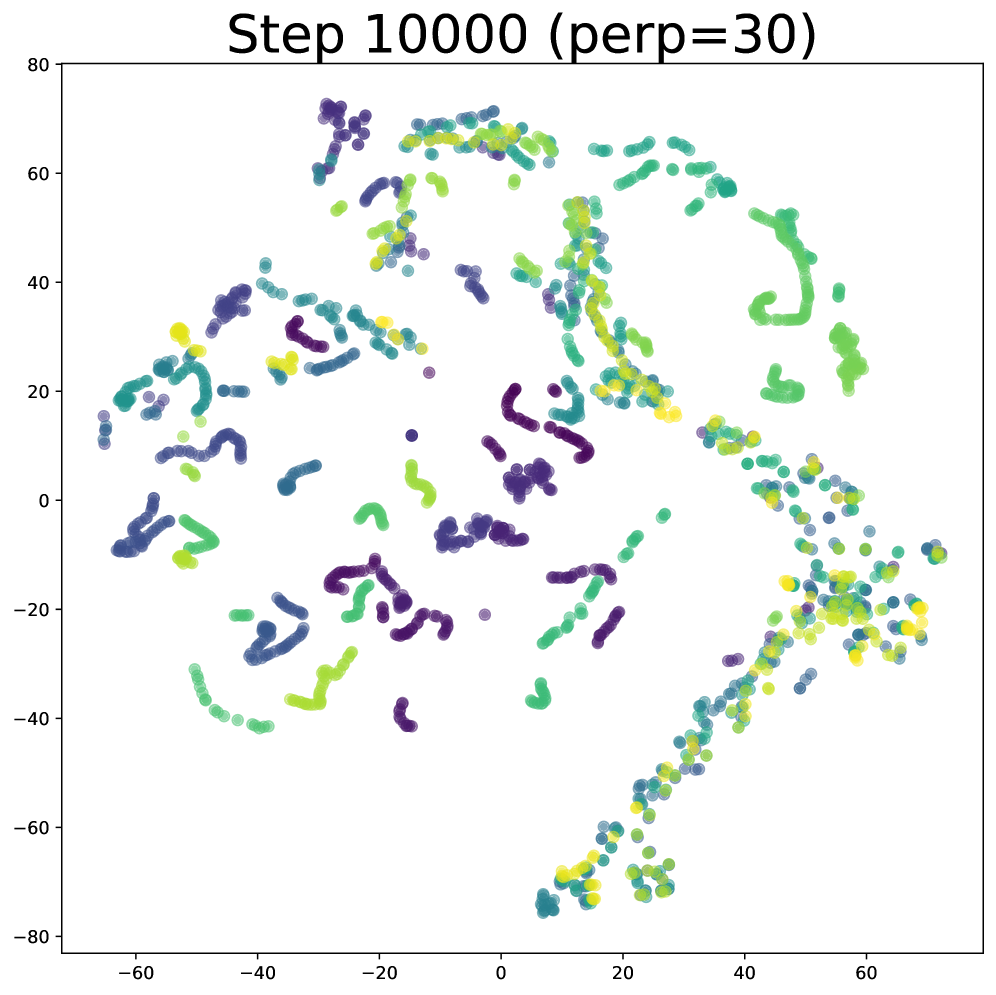
实验结果表明,该方法在Atari、MinAtar和Octax等多个benchmark上均优于现有的流式强化学习基线。通过t-SNE可视化和有效秩测量,验证了该方法能够学习到更丰富的状态表征。尤其是在一些复杂的Atari游戏中,性能提升显著,证明了该方法在提升样本效率方面的有效性。
🎯 应用场景
该研究成果可应用于资源受限的设备上的强化学习任务,例如移动机器人、嵌入式系统和物联网设备。在这些场景中,存储空间和计算资源有限,无法使用传统的基于回放缓冲区的强化学习方法。该方法能够提升智能体在这些环境中的学习效率和性能,使其能够更好地适应动态变化的环境。
📄 摘要(原文)
In streaming Reinforcement Learning (RL), transitions are observed and discarded immediately after a single update. While this minimizes resource usage for on-device applications, it makes agents notoriously sample-inefficient, since value-based losses alone struggle to extract meaningful representations from transient data. We propose extending Self-Predictive Representations (SPR) to the streaming pipeline to maximize the utility of every observed frame. However, due to the highly correlated samples induced by the streaming regime, naively applying this auxiliary loss results in training instabilities. Thus, we introduce orthogonal gradient updates relative to the momentum target and resolve gradient conflicts arising from streaming-specific optimizers. Validated across the Atari, MinAtar, and Octax suites, our approach systematically outperforms existing streaming baselines. Latent-space analysis, including t-SNE visualizations and effective-rank measurements, confirms that our method learns significantly richer representations, bridging the performance gap caused by the absence of a replay buffer, while remaining efficient enough to train on just a few CPU cores.