Sparse Layer Sharpness-Aware Minimization for Efficient Fine-Tuning
作者: Yifei Cheng, Xianglin Yang, Guoxia Wang, Chao Huang, Fei Ma, Dianhai Yu, Xiaochun Cao, Li Shen
分类: cs.LG
发布日期: 2026-02-10
💡 一句话要点
提出SL-SAM:一种稀疏层感知的锐度最小化方法,用于高效微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 锐度感知最小化 稀疏训练 模型微调 多臂老虎机 高效优化
📋 核心要点
- SAM微调计算量大,参数扰动步骤导致计算成本翻倍,成为实际应用的瓶颈。
- SL-SAM将层选择建模为多臂老虎机问题,动态选择参与梯度上升和下降的层,降低计算复杂度。
- 实验表明,SL-SAM在多个任务中实现了与SOTA基线相当的性能,同时显著降低了活跃参数的比例。
📝 摘要(中文)
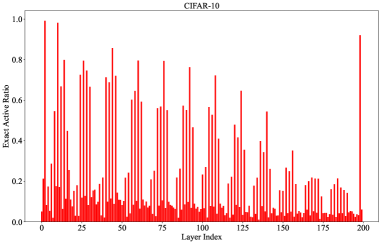
锐度感知最小化(SAM)旨在寻找具有平坦损失曲面的最小值,以提高机器学习任务(包括微调)中的泛化性能。然而,其额外的参数扰动步骤使计算成本翻倍,这成为SAM在实际应用中的瓶颈。本文提出了一种名为SL-SAM的方法,通过引入层上的稀疏技术来打破这个瓶颈。我们的关键创新是将梯度上升(扰动)和下降(更新)步骤中层的动态选择建模为一个多臂老虎机问题。在每次迭代开始时,SL-SAM根据梯度范数采样模型的一部分层来参与后续的参数扰动和更新步骤的反向传播,从而降低计算复杂度。我们还提供了分析来保证SL-SAM的收敛性。在多个任务中微调模型的实验表明,SL-SAM实现了与最先进的基线相当的性能,包括在LLM微调中排名第一。同时,SL-SAM显著降低了反向传播中活跃参数的比例(SL-SAM在视觉、中等和大型语言模型上分别激活了47%、22%和21%的参数,而vanilla SAM始终激活100%),验证了我们提出的算法的效率。
🔬 方法详解
问题定义:论文旨在解决锐度感知最小化(SAM)在模型微调过程中计算成本过高的问题。传统的SAM方法由于需要额外的参数扰动步骤,导致计算量翻倍,限制了其在实际应用中的可行性,尤其是在大型模型上。
核心思路:论文的核心思路是通过引入稀疏性,只选择模型的部分层参与参数扰动和更新的反向传播过程,从而降低计算复杂度。具体来说,将层的选择过程建模为一个多臂老虎机问题,根据梯度范数动态选择参与计算的层。
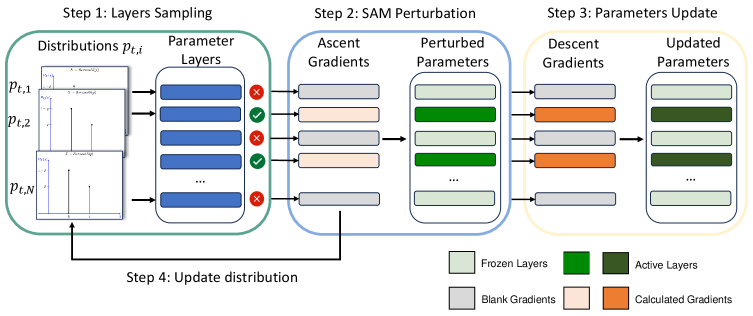
技术框架:SL-SAM算法的整体流程如下: 1. 层选择:根据梯度范数,使用多臂老虎机策略选择一部分层。 2. 参数扰动:仅在选定的层上进行参数扰动,计算扰动后的损失。 3. 梯度更新:仅在选定的层上进行梯度下降,更新模型参数。 4. 策略更新:根据损失变化,更新多臂老虎机策略,调整层选择的概率。
关键创新:SL-SAM的关键创新在于将稀疏性引入到SAM算法中,并使用多臂老虎机策略动态选择参与计算的层。这与传统的SAM方法不同,后者需要对所有层进行参数扰动和更新。通过这种方式,SL-SAM显著降低了计算复杂度,同时保持了良好的泛化性能。
关键设计: * 多臂老虎机策略:论文使用了一种基于梯度范数的探索-利用策略来选择层。梯度范数较大的层更有可能被选择,但也保留了一定的探索概率,以避免陷入局部最优。 * 损失函数:SL-SAM使用与传统SAM相同的损失函数,但只在选定的层上计算损失和梯度。 * 参数更新:使用标准的梯度下降算法更新模型参数,但只更新选定层的参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SL-SAM在视觉、中等和大型语言模型上分别激活了47%、22%和21%的参数,而vanilla SAM始终激活100%的参数。在多个任务中,SL-SAM实现了与最先进的基线相当的性能,包括在LLM微调中排名第一,验证了该算法的有效性和效率。
🎯 应用场景
SL-SAM算法可应用于各种需要微调的机器学习任务,尤其是在计算资源有限的情况下。例如,在移动设备上部署大型语言模型或视觉模型时,可以使用SL-SAM来降低计算成本,提高推理速度。此外,SL-SAM还可以应用于联邦学习等场景,以减少客户端的计算负担。
📄 摘要(原文)
Sharpness-aware minimization (SAM) seeks the minima with a flat loss landscape to improve the generalization performance in machine learning tasks, including fine-tuning. However, its extra parameter perturbation step doubles the computation cost, which becomes the bottleneck of SAM in the practical implementation. In this work, we propose an approach SL-SAM to break this bottleneck by introducing the sparse technique to layers. Our key innovation is to frame the dynamic selection of layers for both the gradient ascent (perturbation) and descent (update) steps as a multi-armed bandit problem. At the beginning of each iteration, SL-SAM samples a part of the layers of the model according to the gradient norm to participate in the backpropagation of the following parameter perturbation and update steps, thereby reducing the computation complexity. We then provide the analysis to guarantee the convergence of SL-SAM. In the experiments of fine-tuning models in several tasks, SL-SAM achieves the performances comparable to the state-of-the-art baselines, including a #1 rank on LLM fine-tuning. Meanwhile, SL-SAM significantly reduces the ratio of active parameters in backpropagation compared to vanilla SAM (SL-SAM activates 47\%, 22\% and 21\% parameters on the vision, moderate and large language model respectively while vanilla SAM always activates 100\%), verifying the efficiency of our proposed algorithm.