Effective MoE-based LLM Compression by Exploiting Heterogeneous Inter-Group Experts Routing Frequency and Information Density
作者: Zhendong Mi, Yixiao Chen, Pu Zhao, Xiaodong Yu, Hao Wang, Yanzhi Wang, Shaoyi Huang
分类: cs.LG
发布日期: 2026-02-10
💡 一句话要点
提出RFID-MoE,通过异构专家路由频率和信息密度实现高效MoE LLM压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 模型压缩 奇异值分解 路由频率 信息密度 自适应秩分配 稀疏投影
📋 核心要点
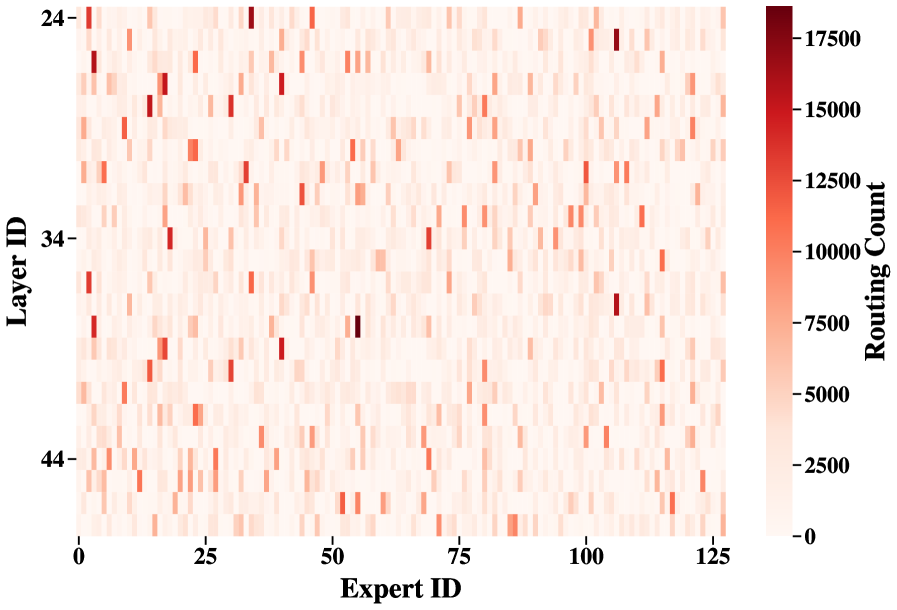
- 现有MoE压缩方法忽略了专家利用率的异构性,导致压缩性能受限。
- RFID-MoE通过融合路由频率和信息密度来衡量专家重要性,自适应分配秩。
- 通过稀疏投影重建压缩残差,在最小参数开销下恢复丢失的信息,提升性能。
📝 摘要(中文)
基于混合专家(MoE)的大型语言模型(LLM)取得了卓越的性能,但存储多个专家网络所带来的巨大内存开销严重阻碍了它们的实际部署。基于奇异值分解(SVD)的压缩已成为一种有前途的后训练技术;然而,大多数现有方法采用统一的秩分配或仅依赖于静态权重属性。这忽略了MoE模型中观察到的专家利用率的巨大异质性,其中频繁的路由模式和内在信息密度在不同专家之间差异很大。本文提出RFID-MoE,一种通过利用异构路由频率和信息密度来实现MoE压缩的有效框架。首先,引入一个融合指标,将专家激活频率与有效秩相结合来衡量专家重要性,在固定预算下自适应地为关键专家组分配更高的秩。此外,没有丢弃压缩残差,而是通过参数高效的稀疏投影机制重建它们,以最小的参数开销恢复丢失的信息。在代表性的MoE LLM(例如,Qwen3、DeepSeekMoE)上进行的大量实验表明,在多个压缩比下,RFID-MoE始终优于最先进的方法,如MoBE和D2-MoE。值得注意的是,RFID-MoE在60%的压缩比下,使用Qwen3-30B模型在PTB上实现了16.92的困惑度,与基线相比,困惑度降低了8.0以上,并且在HellaSwag上的零样本准确率提高了约8%。
🔬 方法详解
问题定义:现有基于SVD的MoE模型压缩方法,要么采用统一的秩分配,要么仅依赖静态权重属性,忽略了不同专家之间路由频率和信息密度的差异性。这种同等对待所有专家的策略,导致重要专家压缩不足,非重要专家过度参数化,最终影响压缩模型的性能。
核心思路:RFID-MoE的核心思路是根据专家的重要性自适应地分配压缩秩。重要性由融合指标衡量,该指标结合了专家的激活频率和有效秩。通过这种方式,模型能够优先保留对性能影响更大的专家,从而在相同压缩率下获得更好的性能。此外,为了弥补压缩过程中丢失的信息,RFID-MoE采用参数高效的稀疏投影机制来重建压缩残差。
技术框架:RFID-MoE的整体框架包含以下几个主要阶段:1) 专家重要性评估:计算每个专家的融合重要性指标,该指标结合了激活频率和有效秩。2) 自适应秩分配:根据专家重要性,在给定的压缩预算下,自适应地为每个专家分配压缩后的秩。重要性高的专家分配更高的秩,反之则分配较低的秩。3) SVD压缩:使用SVD对每个专家进行压缩,将其权重矩阵分解为三个矩阵,并截断奇异值。4) 残差重建:通过稀疏投影机制重建压缩过程中丢失的信息,进一步提升模型性能。
关键创新:RFID-MoE的关键创新在于:1) 融合重要性指标:结合了专家激活频率和有效秩,更准确地衡量了专家对模型性能的贡献。2) 自适应秩分配:根据专家重要性动态调整压缩秩,避免了传统方法中一刀切的压缩策略。3) 稀疏投影残差重建:通过参数高效的方式恢复压缩损失的信息,进一步提升模型性能。
关键设计:1) 融合重要性指标:采用加权平均的方式融合激活频率和有效秩,权重系数需要根据具体任务进行调整。2) 稀疏投影矩阵:采用稀疏连接,减少参数量,同时保留关键信息。稀疏模式可以通过剪枝等方法学习得到。3) 损失函数:除了常规的语言模型损失函数外,还可以加入正则化项,约束稀疏投影矩阵的参数。
🖼️ 关键图片


📊 实验亮点
在Qwen3-30B模型上,RFID-MoE在60%的压缩率下,PTB数据集上的困惑度为16.92,相比基线方法降低了超过8.0。在HellaSwag数据集上,零样本准确率提升了约8%。实验结果表明,RFID-MoE在多个压缩率下均优于现有SOTA方法,如MoBE和D2-MoE。
🎯 应用场景
RFID-MoE可应用于各种基于MoE的LLM的压缩,从而降低模型部署的硬件需求,使其能够在资源受限的设备上运行。这对于移动设备、边缘计算和云计算等场景具有重要意义,能够加速LLM在实际应用中的普及。
📄 摘要(原文)
Mixture-of-Experts (MoE) based Large Language Models (LLMs) have achieved superior performance, yet the massive memory overhead caused by storing multiple expert networks severely hinders their practical deployment. Singular Value Decomposition (SVD)-based compression has emerged as a promising post-training technique; however, most existing methods apply uniform rank allocation or rely solely on static weight properties. This overlooks the substantial heterogeneity in expert utilization observed in MoE models, where frequent routing patterns and intrinsic information density vary significantly across experts. In this work, we propose RFID-MoE, an effective framework for MoE compression by exploiting heterogeneous Routing Frequency and Information Density. We first introduce a fused metric that combines expert activation frequency with effective rank to measure expert importance, adaptively allocating higher ranks to critical expert groups under a fixed budget. Moreover, instead of discarding compression residuals, we reconstruct them via a parameter-efficient sparse projection mechanism to recover lost information with minimal parameter overhead. Extensive experiments on representative MoE LLMs (e.g., Qwen3, DeepSeekMoE) across multiple compression ratios demonstrate that RFID-MoE consistently outperforms state-of-the-art methods like MoBE and D2-MoE. Notably, RFID-MoE achieves a perplexity of 16.92 on PTB with the Qwen3-30B model at a 60% compression ratio, reducing perplexity by over 8.0 compared to baselines, and improves zero-shot accuracy on HellaSwag by approximately 8%.