StealthRL: Reinforcement Learning Paraphrase Attacks for Multi-Detector Evasion of AI-Text Detectors
作者: Suraj Ranganath, Atharv Ramesh
分类: cs.LG, cs.AI, cs.CR
发布日期: 2026-02-09
备注: Expanded version of a workshop submission. Code available
🔗 代码/项目: GITHUB
💡 一句话要点
StealthRL:一种基于强化学习的AI文本检测器对抗性复述攻击方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对抗性攻击 强化学习 AI文本检测 复述攻击 鲁棒性评估
📋 核心要点
- AI文本检测器面临对抗性复述攻击的严峻挑战,现有方法难以在保持语义的同时有效规避检测。
- StealthRL利用强化学习训练复述策略,通过优化复合奖励函数,平衡检测器规避和语义保持。
- 实验表明,StealthRL能有效降低检测率,并成功迁移到未见过的检测器,揭示了潜在的架构脆弱性。
📝 摘要(中文)
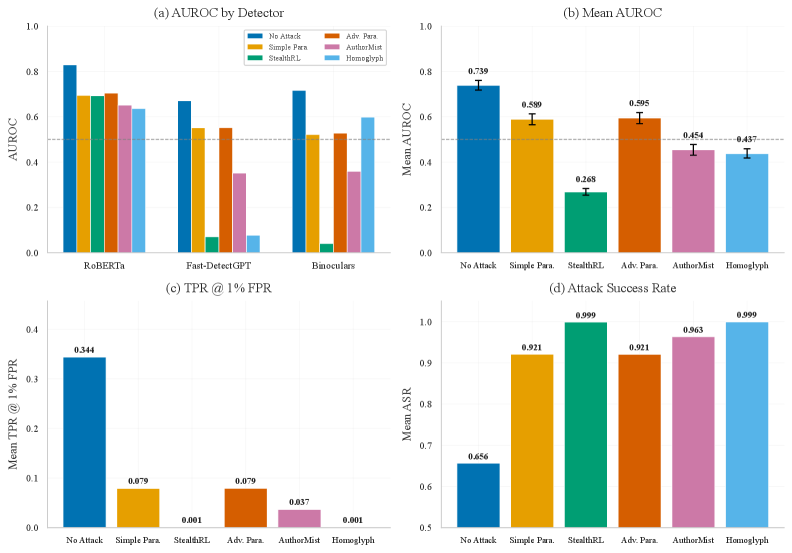
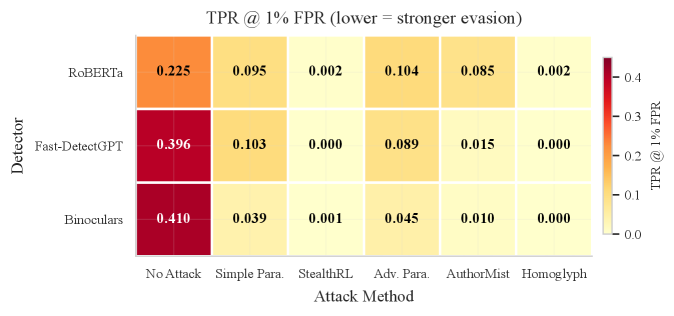
本文提出了一种名为StealthRL的强化学习框架,用于评估AI文本检测器在对抗性复述攻击下的鲁棒性。该框架利用Group Relative Policy Optimization (GRPO) 训练复述策略,并结合Qwen3-4B模型和LoRA适配器,针对多检测器集成进行优化,同时平衡检测器规避和语义保持。在六种攻击设置(M0-M5)下,针对RoBERTa、FastDetectGPT和Binoculars三种检测器,在1%误报率的安全阈值下进行评估。StealthRL实现了接近于零的检测率(平均TPR@1%FPR为0.001),将平均AUROC从0.74降低到0.27,并达到了99.9%的攻击成功率。更重要的是,攻击可以迁移到训练期间未见过的检测器家族,揭示了共享的架构漏洞。此外,还进行了基于LLM的质量评估,分析了检测器分数分布,并提供了每个检测器的AUROC置信区间。结果表明,当前的AI文本检测存在显著的鲁棒性差距,StealthRL为对抗性评估提供了一种有效方法。
🔬 方法详解
问题定义:当前AI文本检测器容易受到对抗性复述攻击的影响,攻击者可以通过改变文本的表达方式,在不改变语义的情况下,绕过检测器。现有的复述方法可能无法很好地平衡语义保持和规避检测,或者泛化能力不足,难以应对多种检测器。
核心思路:StealthRL的核心思路是利用强化学习训练一个复述策略,该策略能够生成既能保持原始文本语义,又能有效规避AI文本检测器的文本。通过将复述过程建模为一个马尔可夫决策过程,并使用奖励函数来指导策略的学习,从而实现对抗性复述的目的。这种方法允许模型学习复杂的复述模式,并适应不同的检测器。
技术框架:StealthRL框架包含以下主要模块:1) 复述策略网络:使用Qwen3-4B模型和LoRA适配器作为复述策略网络,负责生成候选复述文本。2) 多检测器集成:使用RoBERTa、FastDetectGPT和Binoculars等多个AI文本检测器组成检测器集成,用于评估复述文本的真伪。3) 奖励函数:设计一个复合奖励函数,用于平衡检测器规避和语义保持。该奖励函数包括检测器分数、语义相似度等指标。4) 强化学习算法:使用Group Relative Policy Optimization (GRPO) 算法训练复述策略网络,使其能够生成既能规避检测器,又能保持语义的复述文本。
关键创新:StealthRL的关键创新在于:1) 提出了一种基于强化学习的对抗性复述框架,能够自动学习有效的复述策略。2) 使用Group Relative Policy Optimization (GRPO) 算法,提高了策略学习的效率和稳定性。3) 设计了一个复合奖励函数,能够平衡检测器规避和语义保持。4) 实验表明,攻击可以迁移到训练期间未见过的检测器家族,揭示了共享的架构漏洞。
关键设计:在StealthRL中,关键的设计包括:1) 使用Qwen3-4B模型和LoRA适配器作为复述策略网络,以提高生成文本的质量和效率。2) 使用多个AI文本检测器组成检测器集成,以提高攻击的鲁棒性。3) 设计一个复合奖励函数,包括检测器分数、语义相似度等指标,以平衡检测器规避和语义保持。4) 使用Group Relative Policy Optimization (GRPO) 算法训练复述策略网络,以提高策略学习的效率和稳定性。具体来说,奖励函数的设计需要仔细考虑各个指标的权重,以达到最佳的平衡效果。此外,GRPO算法的参数设置也需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
StealthRL在六种攻击设置下,针对RoBERTa、FastDetectGPT和Binoculars三种检测器,在1%误报率的安全阈值下实现了接近于零的检测率(平均TPR@1%FPR为0.001),将平均AUROC从0.74降低到0.27,并达到了99.9%的攻击成功率。更重要的是,攻击可以迁移到训练期间未见过的检测器家族。
🎯 应用场景
StealthRL可用于评估和提升AI文本检测器的鲁棒性,帮助开发者发现检测器中的漏洞并进行修复。此外,该研究可以促进对抗性机器学习领域的发展,推动更安全可靠的AI系统的构建。该方法还可应用于内容安全领域,例如识别和过滤恶意生成的文本。
📄 摘要(原文)
AI-text detectors face a critical robustness challenge: adversarial paraphrasing attacks that preserve semantics while evading detection. We introduce StealthRL, a reinforcement learning framework that stress-tests detector robustness under realistic adversarial conditions. StealthRL trains a paraphrase policy against a multi-detector ensemble using Group Relative Policy Optimization (GRPO) with LoRA adapters on Qwen3-4B, optimizing a composite reward that balances detector evasion with semantic preservation. We evaluate six attack settings (M0-M5) against three detector families (RoBERTa, FastDetectGPT, and Binoculars) at the security-relevant 1% false positive rate operating point. StealthRL achieves near-zero detection (0.001 mean TPR@1%FPR), reduces mean AUROC from 0.74 to 0.27, and attains a 99.9% attack success rate. Critically, attacks transfer to a held-out detector family not seen during training, revealing shared architectural vulnerabilities rather than detector-specific brittleness. We additionally conduct LLM-based quality evaluation via Likert scoring, analyze detector score distributions to explain why evasion succeeds, and provide per-detector AUROC with bootstrap confidence intervals. Our results expose significant robustness gaps in current AI-text detection and establish StealthRL as a principled adversarial evaluation protocol. Code and evaluation pipeline are publicly available at https://github.com/suraj-ranganath/StealthRL.