Dr. MAS: Stable Reinforcement Learning for Multi-Agent LLM Systems
作者: Lang Feng, Longtao Zheng, Shuo He, Fuxiang Zhang, Bo An
分类: cs.LG, cs.AI
发布日期: 2026-02-09
备注: Preprint
💡 一句话要点
Dr. MAS:针对多智能体LLM系统的稳定强化学习训练框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体系统 强化学习 大型语言模型 梯度稳定 优势函数归一化 多轮搜索 数学推理
📋 核心要点
- 多智能体LLM系统面临强化学习训练不稳定的问题,现有基于群体的RL方法难以有效应用。
- Dr. MAS通过智能体层面的优势函数归一化,校准梯度尺度,从而稳定多智能体LLM系统的强化学习训练。
- 实验表明,Dr. MAS在数学推理和多轮搜索任务上显著优于现有方法,并有效消除了梯度爆炸问题。
📝 摘要(中文)
多智能体LLM系统通过角色专业化实现高级推理和工具使用,但对此类系统进行可靠的强化学习(RL)后训练仍然困难。本文从理论上指出了将基于群体的RL扩展到多智能体LLM系统时训练不稳定的一个关键原因。研究表明,在GRPO风格的优化下,全局归一化基线可能偏离不同智能体的奖励分布,最终导致梯度范数不稳定。基于这一发现,我们提出了Dr. MAS,一种简单而稳定的多智能体LLM系统RL训练方法。Dr. MAS使用一种智能体层面的补救措施:使用每个智能体自身的奖励统计信息来归一化每个智能体的优势函数,从而校准梯度尺度并显著稳定训练,这在理论和实验上都得到了验证。除了算法之外,Dr. MAS还为多智能体LLM系统提供了一个端到端的RL训练框架,支持可扩展的编排、灵活的每个智能体LLM服务和优化配置,以及LLM actor后端的共享资源调度。我们在使用Qwen2.5和Qwen3系列模型的多智能体数学推理和多轮搜索基准上评估了Dr. MAS。Dr. MAS实现了优于vanilla GRPO的明显收益(例如,在数学上+5.6% avg@16和+4.6% pass@16,在搜索上+15.2% avg@16和+13.1% pass@16),同时在很大程度上消除了梯度峰值。此外,它在异构智能体模型分配下仍然非常有效,同时提高了效率。
🔬 方法详解
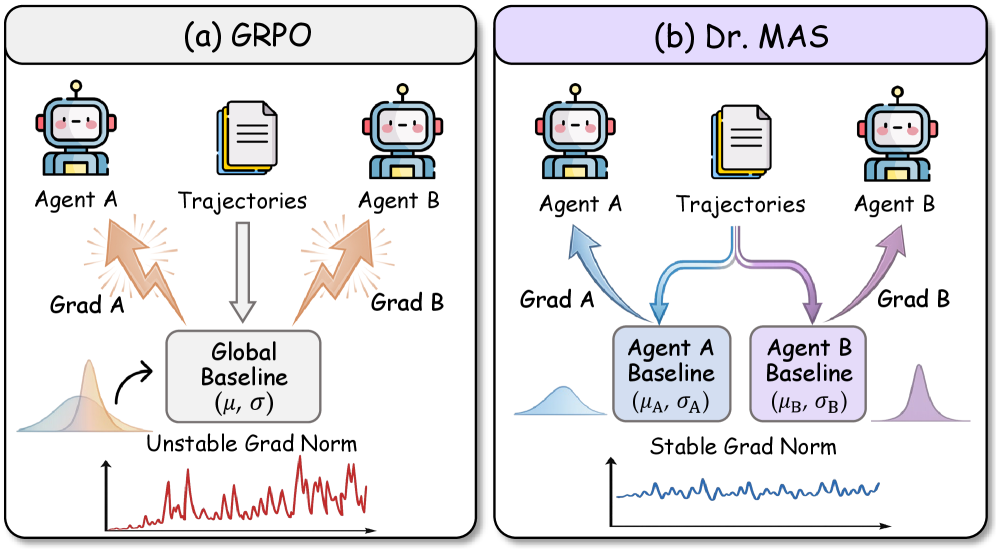
问题定义:多智能体LLM系统在强化学习训练中存在不稳定性,尤其是在使用GRPO(Group Reinforcement Learning Policy Optimization)等方法时。现有方法采用全局归一化基线,忽略了不同智能体奖励分布的差异,导致梯度范数不稳定,训练效果不佳。
核心思路:Dr. MAS的核心思路是针对每个智能体进行独立的优势函数归一化。通过使用每个智能体自身的奖励统计信息来归一化其优势函数,可以更准确地估计每个智能体的策略梯度,从而避免全局归一化带来的偏差,稳定训练过程。这种方法能够更好地适应不同智能体之间的差异,提高训练效率和性能。
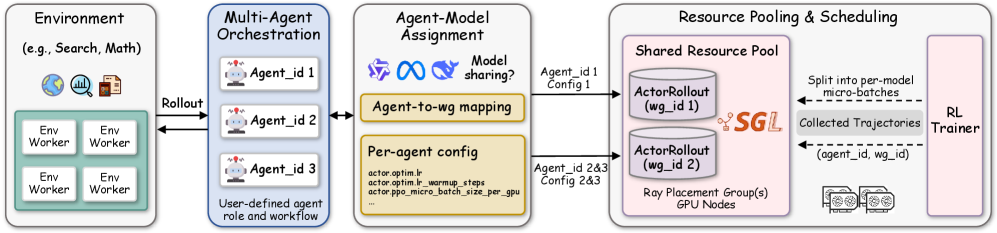
技术框架:Dr. MAS提供了一个端到端的RL训练框架,包括:1) 可扩展的智能体编排,支持大规模多智能体系统的训练;2) 灵活的智能体LLM服务和优化配置,允许为每个智能体定制模型和服务;3) LLM actor后端的共享资源调度,提高资源利用率。整体流程包括:环境交互、奖励收集、优势函数计算、策略更新等步骤,其中优势函数计算是Dr. MAS的关键环节。
关键创新:Dr. MAS最重要的技术创新在于智能体层面的优势函数归一化。与传统的全局归一化方法不同,Dr. MAS考虑了每个智能体的独特奖励分布,从而更准确地估计策略梯度。这种方法能够有效解决多智能体LLM系统训练中的梯度不稳定性问题,提高训练效果。
关键设计:Dr. MAS的关键设计包括:1) 智能体层面的奖励统计信息收集和维护;2) 基于智能体奖励统计信息的优势函数归一化公式;3) 灵活的智能体模型配置和优化策略。具体而言,优势函数的计算公式为:A_i = (R_i - V_i) / std(R_i),其中A_i是智能体i的优势函数,R_i是智能体i的奖励,V_i是智能体i的价值函数,std(R_i)是智能体i奖励的标准差。
🖼️ 关键图片

📊 实验亮点
Dr. MAS在数学推理和多轮搜索任务上取得了显著的性能提升。在数学推理任务中,Dr. MAS相比于vanilla GRPO,avg@16指标提升了5.6%,pass@16指标提升了4.6%。在多轮搜索任务中,avg@16指标提升了15.2%,pass@16指标提升了13.1%。此外,Dr. MAS还能够有效消除梯度峰值,稳定训练过程。
🎯 应用场景
Dr. MAS可应用于各种多智能体LLM系统,例如:多智能体协作解决复杂问题、多智能体对话系统、多智能体游戏等。该研究成果有助于提升多智能体系统的智能化水平和协作效率,具有广泛的应用前景和实际价值,未来可能推动更智能、更高效的多智能体应用发展。
📄 摘要(原文)
Multi-agent LLM systems enable advanced reasoning and tool use via role specialization, yet reliable reinforcement learning (RL) post-training for such systems remains difficult. In this work, we theoretically pinpoint a key reason for training instability when extending group-based RL to multi-agent LLM systems. We show that under GRPO-style optimization, a global normalization baseline may deviate from diverse agents' reward distributions, which ultimately leads to gradient-norm instability. Based on this finding, we propose Dr. MAS, a simple and stable RL training recipe for multi-agent LLM systems. Dr. MAS uses an agent-wise remedy: normalizing advantages per agent using each agent's own reward statistics, which calibrates gradient scales and dramatically stabilizes training, both theoretically and empirically. Beyond the algorithm, Dr. MAS provides an end-to-end RL training framework for multi-agent LLM systems, supporting scalable orchestration, flexible per-agent LLM serving and optimization configs, and shared resource scheduling of LLM actor backends. We evaluate Dr. MAS on multi-agent math reasoning and multi-turn search benchmarks using Qwen2.5 and Qwen3 series models. Dr. MAS achieves clear gains over vanilla GRPO (e.g., +5.6\% avg@16 and +4.6\% pass@16 on math, and +15.2\% avg@16 and +13.1\% pass@16 on search) while largely eliminating gradient spikes. Moreover, it remains highly effective under heterogeneous agent-model assignments while improving efficiency.