CompilerKV: Risk-Adaptive KV Compression via Offline Experience Compilation
作者: Ning Yang, Chengzhi Wang, Yibo Liu, Baoliang Tian, Haijun Zhang
分类: cs.LG, cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出CompilerKV,通过离线经验编译实现风险自适应的KV压缩,提升长文本LLM性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV压缩 长文本LLM 注意力机制 离线学习 风险自适应
📋 核心要点
- 现有KV压缩方法在内存预算紧张时,忽略了prompt依赖的风险变化和attention head的功能异质性,导致性能下降。
- CompilerKV通过离线经验编译,构建头部异质性表和风险自适应阈值门控,实现风险自适应和头部感知的KV压缩。
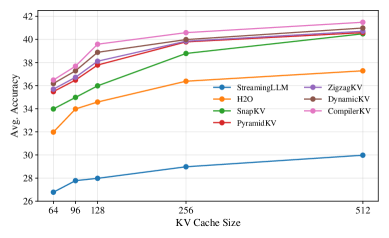
- 实验表明,CompilerKV在512 token预算下,相比SOTA方法有显著提升,接近FullKV的性能。
📝 摘要(中文)
长文本场景下,大型语言模型(LLM)受到Key-Value(KV)缓存内存线性增长的严重限制。现有的KV压缩方法要么依赖静态阈值和仅关注注意力的启发式方法,要么依赖粗略的内存预算分配。在严格的内存预算下,这些方法忽略了两个关键因素:压缩风险中提示依赖的变化以及注意力头之间的功能异质性,这会破坏token选择并导致尾部失败。为了解决这些挑战,我们提出了CompilerKV,这是一种风险自适应和头感知的压缩框架,该框架将离线经验编译为可重用的决策表,用于仅预填充部署。CompilerKV集成了两个关键的协同组件:(i)通过离线上下文bandit学习的头部异质性表,该表分配头部特定的可靠性权重,以明确控制注意力头之间的功能差异;(ii)风险自适应阈值门控机制,该机制共同建模注意力熵和局部困惑度,将提示级别的风险转换为可部署的保留阈值。在LongBench上的实验表明,CompilerKV在512-token预算下优于SOTA方法,恢复了97.7%的FullKV性能,同时比最强的竞争对手获得了高达+5.2的收益。
🔬 方法详解
问题定义:论文旨在解决长文本LLM中KV缓存线性增长带来的内存瓶颈问题。现有KV压缩方法,如基于静态阈值或粗略内存分配的方法,无法有效应对prompt依赖的风险变化和attention head的功能异质性,导致压缩性能下降,尤其是在长尾任务上表现不佳。
核心思路:CompilerKV的核心思路是利用离线经验学习,构建可重用的决策表,从而在在线部署时进行风险自适应和头部感知的KV压缩。通过离线学习,可以更全面地考虑各种prompt和attention head的特性,从而做出更明智的压缩决策。
技术框架:CompilerKV主要包含两个核心模块:头部异质性表(Head Heterogeneity Table)和风险自适应阈值门控(Risk-Adaptive Threshold Gating)。首先,通过离线上下文bandit学习,为每个attention head分配特定的可靠性权重,形成头部异质性表。然后,利用注意力熵和局部困惑度,将prompt级别的风险转化为可部署的保留阈值,实现风险自适应的token选择。
关键创新:CompilerKV的关键创新在于:(1) 显式建模并利用了attention head之间的功能异质性,通过头部异质性表为不同的head分配不同的重要性权重;(2) 提出了风险自适应阈值门控机制,能够根据prompt的风险动态调整压缩策略,从而更好地平衡压缩率和性能。与现有方法相比,CompilerKV更加精细化,能够更好地适应不同的prompt和attention head。
关键设计:头部异质性表通过离线上下文bandit学习得到,bandit算法的目标是最大化下游任务的性能。风险自适应阈值门控机制结合了注意力熵和局部困惑度,使用一个函数将这两个指标映射到保留阈值。具体的函数形式和参数需要根据实验进行调整,以达到最佳的压缩效果。
🖼️ 关键图片

📊 实验亮点
CompilerKV在LongBench数据集上进行了评估,结果表明,在512-token预算下,CompilerKV恢复了97.7%的FullKV性能,并且比最强的竞争对手获得了高达+5.2的性能提升。这些结果表明,CompilerKV能够有效地压缩KV缓存,同时保持较高的模型性能。
🎯 应用场景
CompilerKV可应用于各种需要处理长文本的LLM应用场景,例如长文档摘要、长篇小说生成、代码生成等。通过降低KV缓存的内存需求,CompilerKV可以使LLM在资源受限的设备上运行,或者在相同的硬件资源下处理更长的上下文,从而提升LLM的实用性和适用范围。未来,该技术还可以扩展到其他类型的模型压缩和加速领域。
📄 摘要(原文)
Large Language Models (LLMs) in long-context scenarios are severely constrained by the linear growth of Key-Value (KV) cache memory. Existing KV compression methods rely either on static thresholds and attention-only heuristics or on coarse memory budget allocation. Under tight memory budgets, these methods overlook two key factors: prompt-dependent variation in compression risk and functional heterogeneity across attention heads, which destabilize token selection and lead to tail failures. To address these challenges, we propose CompilerKV, a risk-adaptive and head-aware compression framework that compiles offline experience into reusable decision tables for prefill-only deployment. CompilerKV integrates two key synergistic components: (i) a Head Heterogeneity Table, learned via offline contextual bandits, which assigns head-specific reliability weights to govern functional differences across attention heads explicitly; and (ii) a Risk-Adaptive Threshold Gating mechanism that jointly models attention entropy and local perplexity, transforming prompt-level risk into deployable retention thresholds. Experiments on LongBench show CompilerKV dominates SOTA methods under a 512-token budget, recovering 97.7\% of FullKV performance while achieving up to +5.2 points gain over the strongest competitor.