Contextual Rollout Bandits for Reinforcement Learning with Verifiable Rewards
作者: Xiaodong Lu, Xiaohan Wang, Jiajun Chai, Guojun Yin, Wei Lin, Zhijun Chen, Yu Luo, Fuzhen Zhuang, Yikun Ban, Deqing Wang
分类: cs.LG, cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出上下文Rollout Bandits方法,提升可验证奖励强化学习的数学推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 上下文Bandits rollout调度 数学推理
📋 核心要点
- 现有RLVR方法对rollout的使用方式粗糙,忽略了rollout质量差异,导致监督信号噪声大。
- 论文提出基于上下文Bandits的rollout调度框架,自适应选择高质量rollout,提高样本利用率。
- 实验证明,该方法在数学推理任务上,能够显著提升性能和训练效率,优于现有方法。
📝 摘要(中文)
本文针对可验证奖励强化学习(RLVR)中,现有方法对rollout利用不充分的问题,提出了一种基于上下文Bandits的rollout调度框架。现有RLVR方法通常以无差别且短视的方式使用rollout,忽略了rollout质量的差异性,并且在单次使用后丢弃历史rollout,导致监督信号噪声大、样本效率低和策略更新次优。本文将RLVR中的rollout调度建模为上下文Bandits问题,并提出一个统一的神经调度框架,自适应地选择高质量的rollout。每个rollout被视为一个臂,其奖励由连续优化步骤之间的性能增益定义。该调度器支持噪声感知的组内选择和历史rollout的自适应全局重用。理论分析表明,该方法具有亚线性后悔界,并且扩大rollout缓冲区可以提高可实现的性能上限。在六个数学推理基准上的实验表明,该方法在多个RLVR优化方法中均能实现性能和训练效率的持续提升。
🔬 方法详解
问题定义:现有RLVR方法在利用rollout时存在两个主要问题:一是将同一prompt下的不同质量的response同等对待,导致监督信号存在噪声;二是历史rollout在使用一次后就被丢弃,造成样本利用率低。这些问题最终导致策略更新效果不佳,影响模型性能。
核心思路:论文的核心思路是将rollout调度问题建模为一个上下文Bandits问题。每个rollout被视为一个“臂”,其“奖励”定义为使用该rollout进行策略更新后,性能提升的程度。通过学习一个调度器,根据rollout的上下文信息(例如,prompt、response等)来选择最有价值的rollout,从而提高样本效率和策略更新的质量。
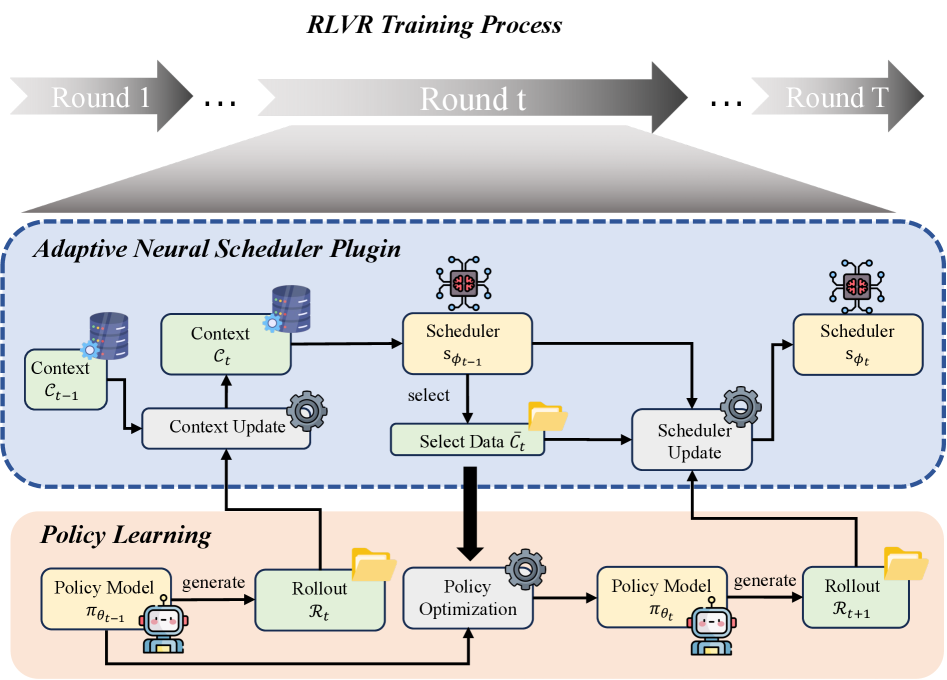
技术框架:整体框架包含以下几个主要模块:1) Rollout生成模块:使用当前策略生成一系列rollout;2) 上下文编码模块:将每个rollout的上下文信息(prompt、response等)编码成向量表示;3) Bandits调度器:根据上下文向量,预测每个rollout的奖励,并选择奖励最高的rollout;4) 策略更新模块:使用选定的rollout更新策略。该框架支持历史rollout的重用,通过维护一个rollout缓冲区,Bandits调度器可以从缓冲区中选择历史rollout。
关键创新:该方法最重要的创新在于将rollout调度问题建模为上下文Bandits问题,并提出一个统一的神经调度框架来解决该问题。与现有方法相比,该方法能够自适应地选择高质量的rollout,并有效地利用历史rollout,从而提高样本效率和策略更新的质量。此外,该方法还提供了理论上的保证,证明了其具有亚线性后悔界,并且扩大rollout缓冲区可以提高可实现的性能上限。
关键设计:Bandits调度器采用神经网络结构,输入是rollout的上下文向量,输出是每个rollout的奖励预测值。损失函数采用标准的Bandits损失函数,例如UCB或Thompson Sampling。Rollout缓冲区的容量是一个重要的超参数,需要根据具体任务进行调整。论文中还提到了一种噪声感知的组内选择策略,用于在同一prompt下的多个rollout中选择最佳的rollout。
🖼️ 关键图片
📊 实验亮点
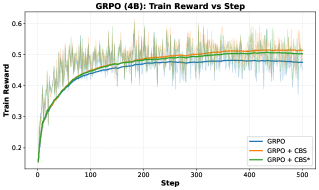
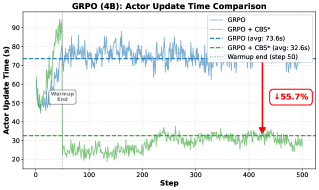
实验结果表明,该方法在六个数学推理基准上均取得了显著的性能提升。例如,在某些基准上,该方法能够将性能提升超过10%。此外,该方法还提高了训练效率,减少了训练所需的样本数量。与现有的RLVR方法相比,该方法具有明显的优势。
🎯 应用场景
该研究成果可应用于各种需要利用大型语言模型进行推理和决策的任务中,例如数学问题求解、代码生成、对话系统等。通过提高样本效率和策略更新质量,可以降低训练成本,并提升模型性能。该方法在教育、金融、医疗等领域具有广泛的应用前景。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) is an effective paradigm for improving the reasoning capabilities of large language models. However, existing RLVR methods utilize rollouts in an indiscriminate and short-horizon manner: responses of heterogeneous quality within each prompt are treated uniformly, and historical rollouts are discarded after a single use. This leads to noisy supervision, poor sample efficiency, and suboptimal policy updates. We address these issues by formulating rollout scheduling in RLVR as a contextual bandit problem and proposing a unified neural scheduling framework that adaptively selects high-value rollouts throughout training. Each rollout is treated as an arm whose reward is defined by the induced performance gain between consecutive optimization steps. The resulting scheduler supports both noise-aware intra-group selection and adaptive global reuse of historical rollouts within a single principled framework. We provide theoretical justification by deriving sublinear regret bounds and showing that enlarging the rollout buffer improves the achievable performance upper bound. Experiments on six mathematical reasoning benchmarks demonstrate consistent gains in performance and training efficiency across multiple RLVR optimization methods.