Near-Oracle KV Selection via Pre-hoc Sparsity for Long-Context Inference
作者: Yifei Gao, Lei Wang, Rong-Cheng Tu, Qixin Zhang, Jun Cheng, Dacheng Tao
分类: cs.LG, cs.AI, cs.IT
发布日期: 2026-02-09
备注: An effective method for accelerating LLM's inference via selective KV processing
💡 一句话要点
提出Pre-hoc Sparsity,解决长文本推理中KV缓存选择的后验偏差问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 KV缓存选择 稀疏注意力 预先稀疏化 后验偏差
📋 核心要点
- 现有长文本推理方法依赖后验启发式选择KV缓存,存在后验偏差,导致token重要性失真和长程推理能力下降。
- 论文提出Pre-hoc Sparsity (PrHS),在注意力评分前进行KV选择,通过控制丢弃质量来保证准确性,避免后验偏差。
- 实验表明,PrHS在降低检索开销、减少FLOPs和提高吞吐量方面优于现有方法,同时保持或提升了模型准确率。
📝 摘要(中文)
大型语言模型(LLM)推理的核心瓶颈在于处理不断增长的键值(KV)缓存的注意力计算成本。尽管近乎最优的top-k KV选择可以在显著降低计算和带宽的同时保持密集注意力的质量,但现有的稀疏方法通常依赖于后验启发式方法,即以观察到的注意力或代理分数作为条件的selector。这种条件引入了后验偏差:它倾向于扭曲真实的token重要性并遗漏显著的token,从而损害长程推理。为了解决这个问题,我们提出了Pre-hoc Sparsity(PrHS),它在注意力评分之前选择KV条目,并提供显式的准确性控制。设丢弃条目的注意力质量为delta(丢弃质量)。通过边际到互信息的分析,我们推导出互信息损失的上界,该上界仅取决于丢弃的质量。这种关系解释了后验启发式的失效模式,并通过预先控制丢弃的质量来实现可验证的保证。在PrHS中,我们沿着时间、深度和层这三个轴实例化了三个正交的预先selector。在LLaMA和Mistral系列上的大量实验验证了PrHS。在GSM8K和CoQA上,PrHS降低了90%以上的检索开销,在匹配或更好的准确率下,实现了比HShare高3倍的检索稀疏性。它在LongBench上的平均降级低于1%,与之前的稀疏基线相比,注意力FLOPs降低了约15%,并且在NVIDIA A100-80GB GPU上,注意力算子延迟提高了9.9倍,吞吐量提高了2.8倍。
🔬 方法详解
问题定义:论文旨在解决长文本推理中,由于KV缓存过大导致的计算和带宽瓶颈问题。现有稀疏方法依赖后验信息(如注意力分数)来选择KV,引入了后验偏差,导致重要token被忽略,影响长程推理能力。这些方法无法提供明确的准确性保证,且容易受到噪声的影响。
核心思路:论文的核心思路是在注意力评分之前进行KV选择,即Pre-hoc Sparsity (PrHS)。通过预先控制丢弃的注意力质量(dropped mass),来限制互信息损失的上界,从而保证选择的KV能够保留足够的信息。这种方法避免了后验偏差,并提供了可验证的准确性保证。
技术框架:PrHS包含三个正交的预先selector,分别沿着时间、深度和层三个轴进行KV选择。时间轴selector关注历史token的重要性,深度轴selector关注不同层级的token表示,层轴selector关注不同层的注意力权重。这三个selector可以独立或组合使用,以实现不同的稀疏化策略。整体流程是:输入文本 -> PrHS (时间/深度/层 selector) -> KV选择 -> 注意力计算 -> 输出。
关键创新:最重要的技术创新点在于提出了预先稀疏化的概念,即在注意力计算之前进行KV选择,避免了后验偏差。通过边际到互信息的分析,推导出了互信息损失的上界,该上界仅取决于丢弃的注意力质量。这使得可以预先控制准确性,并提供可验证的保证。与现有方法的本质区别在于,PrHS不依赖于后验信息,而是基于先验知识进行KV选择。
关键设计:论文的关键设计包括:1) 三个正交的预先selector的设计,允许灵活地控制KV选择的粒度;2) 基于边际到互信息的分析,推导出互信息损失的上界,为准确性控制提供了理论依据;3) 通过控制丢弃的注意力质量(delta)来实现准确性保证,delta可以根据实际需求进行调整。
🖼️ 关键图片
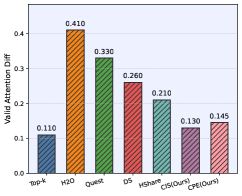
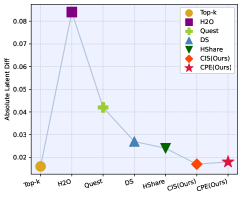
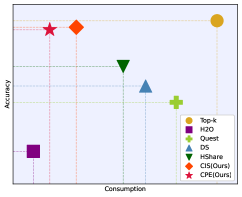
📊 实验亮点
实验结果表明,PrHS在GSM8K和CoQA数据集上降低了90%以上的检索开销,实现了比HShare高3倍的检索稀疏性,同时保持或提高了准确率。在LongBench数据集上,平均降级低于1%,注意力FLOPs降低了约15%。在NVIDIA A100-80GB GPU上,注意力算子延迟提高了9.9倍,吞吐量提高了2.8倍。这些结果表明PrHS在提高推理效率和降低计算成本方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的场景,如长文档摘要、机器翻译、问答系统、代码生成等。通过降低KV缓存的计算和带宽需求,可以显著提高LLM的推理效率,降低部署成本,并使其能够在资源受限的设备上运行。未来,该方法可以进一步扩展到其他类型的注意力机制和模型架构中。
📄 摘要(原文)
A core bottleneck in large language model (LLM) inference is the cost of attending over the ever-growing key-value (KV) cache. Although near-oracle top-k KV selection can preserve the quality of dense attention while sharply reducing computation and bandwidth, existing sparse methods generally rely on posterior heuristics, i.e., selectors conditioned on observed attention or proxy scores. Such conditioning introduces posterior bias: it tends to distort true token importance and miss salient tokens, thereby impairing long-range reasoning. To tackle this problem, we propose Pre-hoc Sparsity (PrHS), which selects KV entries before attention scoring and provides explicit accuracy control. Let the attention mass of discarded entries be delta (the dropped mass). Through a marginal-to-mutual-information analysis, we derive an upper bound on the mutual-information loss that depends only on the dropped mass. This relation explains failure modes of posterior heuristics and enables verifiable guarantees by controlling the dropped mass in advance. Within PrHS, we instantiate three orthogonal pre-hoc selectors along the axes of time, depth, and layer. Extensive experiments on LLaMA and Mistral families validate PrHS. Across GSM8K and CoQA, PrHS reduces retrieval overhead by over 90%, achieving 3x higher retrieval sparsity than HShare at matched or better accuracy. It incurs under 1% average degradation on LongBench, lowers attention FLOPs by about 15% versus prior sparse baselines, and yields a 9.9x speedup in attention-operator latency and 2.8x higher throughput on NVIDIA A100-80GB GPUs than the dense baseline.