Learning in Context, Guided by Choice: A Reward-Free Paradigm for Reinforcement Learning with Transformers
作者: Juncheng Dong, Bowen He, Moyang Guo, Ethan X. Fang, Zhuoran Yang, Vahid Tarokh
分类: cs.LG, cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出基于偏好的强化学习方法以解决奖励信号不足的问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 上下文强化学习 偏好反馈 奖励信号 决策任务 模型泛化
📋 核心要点
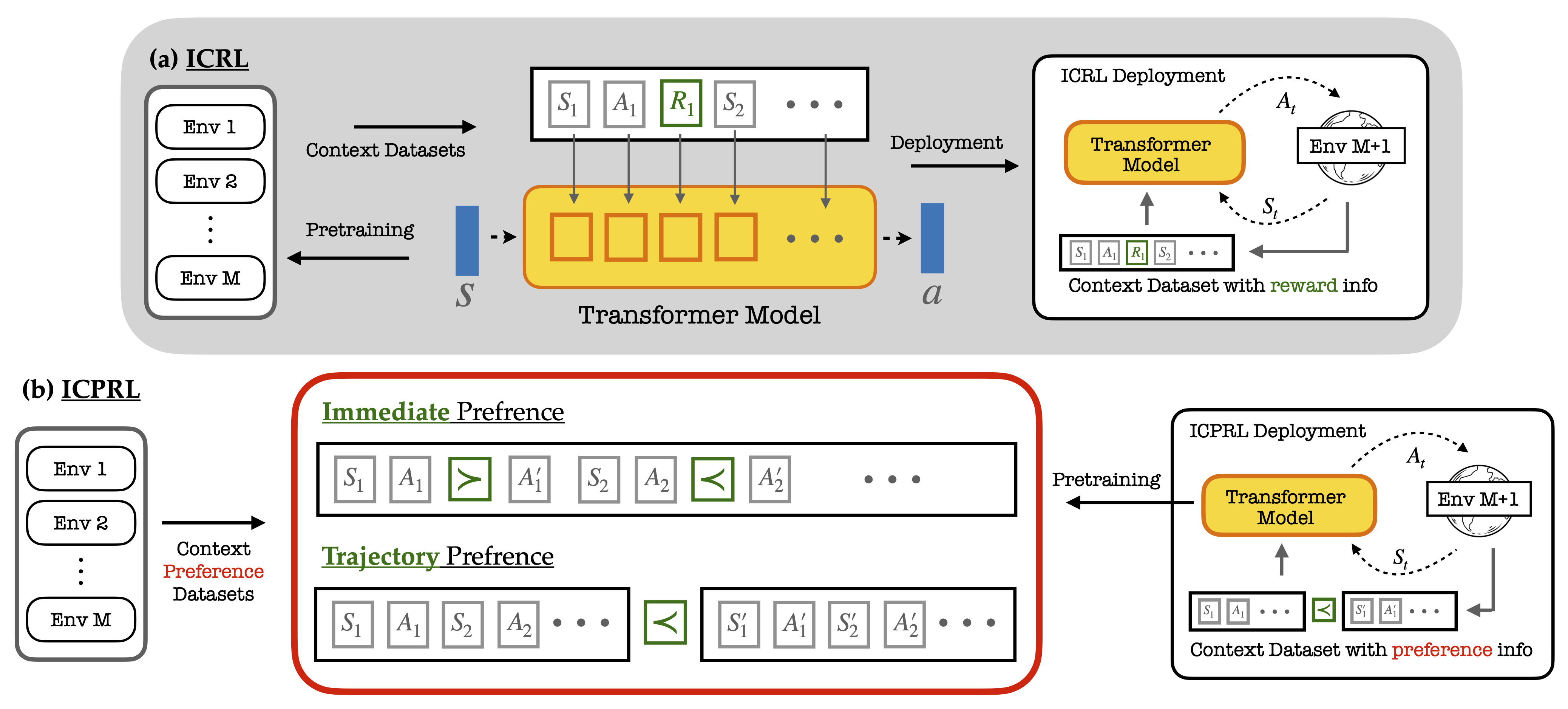
- 现有的上下文强化学习方法依赖明确的奖励信号,限制了在奖励模糊或难以获取的任务中的应用。
- 本文提出的ICPRL方法通过仅依赖偏好反馈来进行预训练和部署,解决了奖励信号不足的问题。
- 实验结果表明,ICPRL在对抗性赌博、导航和连续控制任务上表现出色,性能与传统ICRL方法相当。
📝 摘要(中文)
在上下文强化学习(ICRL)中,现有方法依赖于明确的奖励信号进行预训练,这限制了其在奖励模糊或难以获取的情况下的应用。为此,本文提出了一种新的学习范式——上下文偏好强化学习(ICPRL),该方法在预训练和部署过程中仅依赖偏好反馈,消除了对奖励监督的需求。我们研究了两种变体:即时偏好强化学习(I-PRL)和轨迹偏好强化学习(T-PRL),并展示了在仅使用偏好信号的上下文数据集上,监督预训练仍然有效。实验结果表明,ICPRL在未见任务上的上下文泛化能力强,性能与完全奖励监督训练的ICRL方法相当。
🔬 方法详解
问题定义:现有的上下文强化学习方法依赖于明确的奖励信号进行预训练,这在奖励模糊或难以获取的情况下造成了应用限制。
核心思路:本文提出的ICPRL方法通过仅依赖偏好反馈来进行学习,消除了对奖励信号的需求,从而增强了模型在未见任务上的泛化能力。
技术框架:ICPRL包括两个主要变体:I-PRL(即时偏好强化学习)和T-PRL(轨迹偏好强化学习),前者基于每一步的偏好反馈,后者基于轨迹级别的比较。
关键创新:ICPRL的核心创新在于其完全依赖偏好信号进行学习,而非传统的奖励信号,这使得模型在面对复杂决策任务时更具灵活性和适应性。
关键设计:在I-PRL和T-PRL中,模型直接从偏好数据中优化策略,而无需奖励信号或最优动作标签,提升了数据效率。
🖼️ 关键图片


📊 实验亮点
实验结果显示,ICPRL在对抗性赌博、导航和连续控制任务上表现优异,达到了与传统ICRL方法相当的性能,证明了其在未见任务上的强泛化能力。
🎯 应用场景
该研究的潜在应用领域包括机器人控制、自动驾驶、游戏AI等,尤其是在奖励信号难以定义或获取的复杂环境中。通过使用偏好反馈,ICPRL能够更好地适应多变的决策任务,具有广泛的实际价值和未来影响。
📄 摘要(原文)
In-context reinforcement learning (ICRL) leverages the in-context learning capabilities of transformer models (TMs) to efficiently generalize to unseen sequential decision-making tasks without parameter updates. However, existing ICRL methods rely on explicit reward signals during pretraining, which limits their applicability when rewards are ambiguous, hard to specify, or costly to obtain. To overcome this limitation, we propose a new learning paradigm, In-Context Preference-based Reinforcement Learning (ICPRL), in which both pretraining and deployment rely solely on preference feedback, eliminating the need for reward supervision. We study two variants that differ in the granularity of feedback: Immediate Preference-based RL (I-PRL) with per-step preferences, and Trajectory Preference-based RL (T-PRL) with trajectory-level comparisons. We first show that supervised pretraining, a standard approach in ICRL, remains effective under preference-only context datasets, demonstrating the feasibility of in-context reinforcement learning using only preference signals. To further improve data efficiency, we introduce alternative preference-native frameworks for I-PRL and T-PRL that directly optimize TM policies from preference data without requiring reward signals nor optimal action labels.Experiments on dueling bandits, navigation, and continuous control tasks demonstrate that ICPRL enables strong in-context generalization to unseen tasks, achieving performance comparable to ICRL methods trained with full reward supervision.