Epigraph-Guided Flow Matching for Safe and Performant Offline Reinforcement Learning
作者: Manan Tayal, Mumuksh Tayal
分类: cs.LG, cs.AI
发布日期: 2026-02-08
备注: 23 pages, 8 figures
💡 一句话要点
EpiFlow:基于Epigraph引导的流匹配,实现安全且高效的离线强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 安全强化学习 最优控制 Epigraph 流匹配 价值函数 策略学习
📋 核心要点
- 现有安全离线强化学习方法难以兼顾安全性、性能和数据分布一致性,常常需要折衷或引入保守性。
- EpiFlow将安全离线RL建模为状态约束的最优控制问题,通过学习可行性价值函数来共同优化安全性和性能。
- EpiFlow在Safety-Gymnasium等安全关键任务中表现出色,实现了高回报且安全违规接近于零。
📝 摘要(中文)
离线强化学习为训练自主系统提供了一种引人注目的范例,尤其是在安全关键领域,它避免了在线探索的风险。然而,从固定数据集中同时实现强大的安全性和性能仍然具有挑战性。现有的安全离线强化学习方法通常依赖于允许违规的软约束,引入过度的保守性,或者难以平衡安全性、奖励优化和对数据分布的遵守。为了解决这个问题,我们提出了Epigraph引导的流匹配(EpiFlow),该框架将安全离线强化学习公式化为一个状态约束的最优控制问题,以共同优化安全性和性能。我们学习了一个从最优控制问题的epigraph重构中导出的可行性价值函数,从而避免了先前工作中常见的解耦目标或事后过滤。通过基于此epigraph价值函数重新加权行为分布,并通过流匹配拟合生成策略来合成策略,从而实现高效的、分布一致的采样。在各种安全关键任务中,包括Safety-Gymnasium基准测试,EpiFlow实现了具有竞争力的回报,且经验安全违规接近于零,证明了epigraph引导策略合成的有效性。
🔬 方法详解
问题定义:现有的安全离线强化学习方法在处理安全约束时存在不足。一些方法采用软约束,允许一定程度的安全违规。另一些方法则过于保守,导致性能下降。此外,许多方法难以同时优化安全性和奖励,并且难以保证策略与离线数据集的分布一致性。因此,如何在离线强化学习中实现既安全又高效的策略是一个关键问题。
核心思路:EpiFlow的核心思路是将安全离线强化学习问题转化为一个状态约束的最优控制问题,并利用epigraph重构来学习一个可行性价值函数。这个价值函数能够指导策略的生成,使其既能最大化奖励,又能满足安全约束。通过这种方式,EpiFlow避免了传统方法中常见的解耦目标或事后过滤,从而能够更有效地平衡安全性和性能。
技术框架:EpiFlow的整体框架包括以下几个主要步骤:1) 将安全离线RL问题形式化为状态约束的最优控制问题。2) 利用epigraph重构,将约束问题转化为无约束问题,并学习一个可行性价值函数。3) 基于该价值函数,对离线数据集中的行为分布进行重加权,从而得到一个更安全的策略分布。4) 使用流匹配技术,从重加权的策略分布中学习一个生成策略。这个生成策略能够高效地采样,并保证与重加权的策略分布一致。
关键创新:EpiFlow的关键创新在于使用epigraph重构来学习可行性价值函数,并将其用于指导策略的生成。与现有方法相比,EpiFlow能够更有效地平衡安全性和性能,并且能够保证策略与离线数据集的分布一致性。此外,EpiFlow使用流匹配技术来学习生成策略,从而实现高效的采样。
关键设计:EpiFlow的关键设计包括:1) 使用神经网络来近似可行性价值函数。2) 使用合适的损失函数来训练价值函数,例如,可以使用贝尔曼误差或时间差分误差。3) 使用流匹配技术来学习生成策略,例如,可以使用连续归一化流或神经常微分方程。4) 对离线数据集中的行为分布进行重加权时,可以使用指数加权或重要性采样。
🖼️ 关键图片


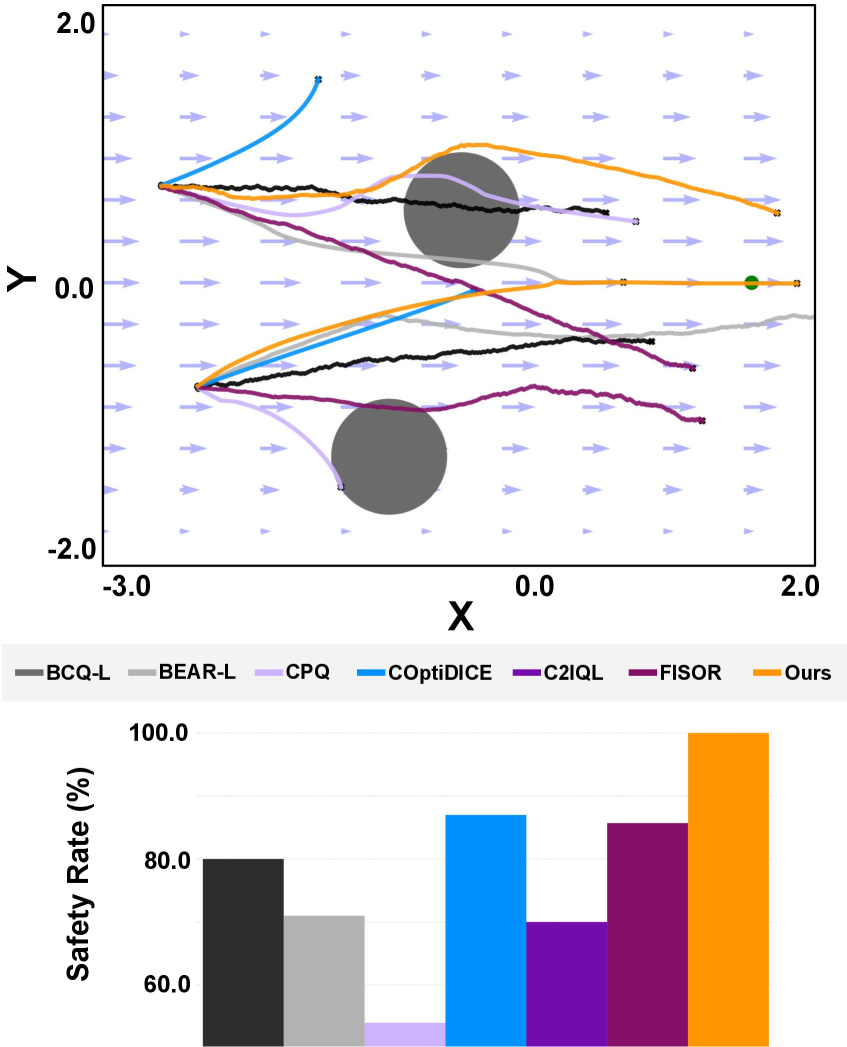
📊 实验亮点
EpiFlow在Safety-Gymnasium基准测试中取得了显著成果,在保证安全违规接近于零的情况下,实现了与现有最佳离线强化学习方法相当甚至更高的回报。实验结果表明,EpiFlow能够有效地平衡安全性和性能,并且能够保证策略与离线数据集的分布一致性。
🎯 应用场景
EpiFlow在安全关键领域具有广泛的应用前景,例如自动驾驶、机器人控制和医疗决策。它可以用于训练在复杂环境中安全可靠运行的自主系统,从而降低事故风险并提高效率。此外,EpiFlow还可以应用于其他需要平衡安全性和性能的场景,例如金融交易和能源管理。
📄 摘要(原文)
Offline reinforcement learning (RL) provides a compelling paradigm for training autonomous systems without the risks of online exploration, particularly in safety-critical domains. However, jointly achieving strong safety and performance from fixed datasets remains challenging. Existing safe offline RL methods often rely on soft constraints that allow violations, introduce excessive conservatism, or struggle to balance safety, reward optimization, and adherence to the data distribution. To address this, we propose Epigraph-Guided Flow Matching (EpiFlow), a framework that formulates safe offline RL as a state-constrained optimal control problem to co-optimize safety and performance. We learn a feasibility value function derived from an epigraph reformulation of the optimal control problem, thereby avoiding the decoupled objectives or post-hoc filtering common in prior work. Policies are synthesized by reweighting the behavior distribution based on this epigraph value function and fitting a generative policy via flow matching, enabling efficient, distribution-consistent sampling. Across various safety-critical tasks, including Safety-Gymnasium benchmarks, EpiFlow achieves competitive returns with near-zero empirical safety violations, demonstrating the effectiveness of epigraph-guided policy synthesis.