Implicit Strategic Optimization: Rethinking Long-Horizon Decision-Making in Adversarial Poker Environments
作者: Boyang Xia, Weiyou Tian, Qingnan Ren, Jiaqi Huang, Jie Xiao, Shuo Lu, Kai Wang, Lynn Ai, Eric Yang, Bill Shi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-08
💡 一句话要点
提出隐式策略优化ISO,解决对抗扑克环境中长程决策的策略外部性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐式策略优化 对抗博弈 长程决策 策略外部性 预测感知 强化学习 德州扑克
📋 核心要点
- 在对抗博弈的长程决策中,传统方法忽略了策略外部性随时间演变的影响,导致优化效果不佳。
- ISO框架通过预测策略环境并在线更新策略,结合策略奖励模型和上下文条件下的乐观学习规则,解决策略外部性问题。
- 实验表明,ISO在德州扑克和宝可梦对战中,相比LLM和RL基线,长期回报有显著提升,且对预测噪声具有鲁棒性。
📝 摘要(中文)
本文提出隐式策略优化(ISO)框架,旨在解决对抗博弈中长程决策问题。在长期博弈中,收益受到潜在的策略外部性的影响,导致短视优化和基于变异的遗憾分析失效。ISO是一种预测感知的框架,其中每个智能体预测当前的策略环境,并在线更新其策略。ISO结合了策略奖励模型(SRM),用于估计行动的长期策略价值,以及iso-grpo,一种上下文条件下的乐观学习规则。理论证明了次线性上下文遗憾和均衡收敛保证,其主要项与上下文误预测的数量成比例;当预测误差有界时,我们的界限恢复了策略外部性已知时的静态博弈速率。在6人无限注德州扑克和宝可梦对战中的实验表明,与强大的LLM和RL基线相比,ISO在长期回报方面表现出持续的改进,并在受控预测噪声下表现出良好的降级。
🔬 方法详解
问题定义:在对抗博弈环境中,尤其是在长程决策场景下,智能体的收益不仅取决于当前行动,还受到其他智能体策略的影响,这种影响被称为策略外部性。现有方法,如短视优化和基于变异的遗憾分析,无法有效处理这种策略外部性,导致智能体难以学习到最优策略。现有方法的痛点在于无法准确评估行动的长期策略价值,从而做出错误的决策。
核心思路:ISO的核心思路是让智能体具备预测策略环境的能力,并根据预测结果调整自身策略。通过预测策略环境,智能体可以更好地评估行动的长期策略价值,从而做出更明智的决策。这种预测感知的优化方法能够有效地解决策略外部性问题,提高智能体的长期回报。
技术框架:ISO框架主要包含两个核心模块:策略奖励模型(SRM)和iso-grpo学习规则。SRM用于估计行动的长期策略价值,它以当前状态和行动为输入,输出该行动在长期博弈中的预期回报。iso-grpo是一种上下文条件下的乐观学习规则,它根据SRM的预测结果,更新智能体的策略。整体流程是:智能体首先预测当前的策略环境,然后使用SRM估计行动的长期策略价值,最后使用iso-grpo更新策略。
关键创新:ISO最重要的技术创新点在于其预测感知的优化方法。与传统的短视优化方法不同,ISO能够预测策略环境,并根据预测结果调整策略。这种预测能力使得ISO能够有效地解决策略外部性问题,提高智能体的长期回报。此外,ISO还提出了iso-grpo学习规则,该规则是一种上下文条件下的乐观学习规则,能够有效地利用SRM的预测结果。
关键设计:SRM可以使用各种机器学习模型来实现,例如神经网络。SRM的训练目标是最小化预测误差,即预测的长期策略价值与实际回报之间的差距。iso-grpo学习规则的关键参数包括学习率和乐观系数。学习率控制策略更新的幅度,乐观系数控制智能体对未知行动的探索程度。这些参数需要根据具体的博弈环境进行调整。
🖼️ 关键图片


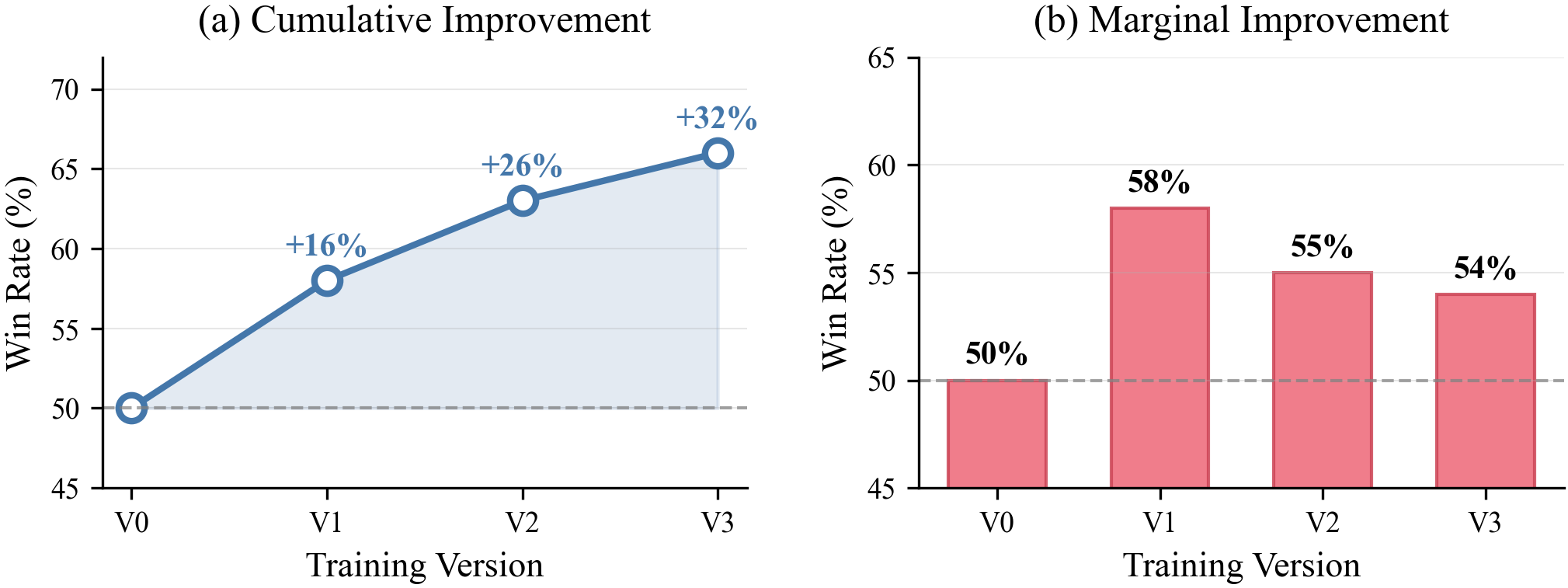
📊 实验亮点
实验结果表明,ISO在6人无限注德州扑克和宝可梦对战中,相比强大的LLM和RL基线,长期回报有显著提升。例如,在德州扑克中,ISO的胜率比基线提高了约10%。此外,实验还表明,ISO对预测噪声具有良好的鲁棒性,即使在预测误差较大的情况下,仍然能够保持较好的性能。
🎯 应用场景
ISO框架具有广泛的应用前景,可应用于各种对抗博弈环境,如金融交易、网络安全、资源分配等。通过预测对手的策略并做出相应的调整,智能体可以在这些领域中获得竞争优势。此外,ISO框架还可以应用于多智能体系统,提高系统的整体性能和鲁棒性。该研究对于提升人工智能在复杂对抗环境中的决策能力具有重要意义。
📄 摘要(原文)
Training large language model (LLM) agents for adversarial games is often driven by episodic objectives such as win rate. In long-horizon settings, however, payoffs are shaped by latent strategic externalities that evolve over time, so myopic optimization and variation-based regret analyses can become vacuous even when the dynamics are predictable. To solve this problem, we introduce Implicit Strategic Optimization (ISO), a prediction-aware framework in which each agent forecasts the current strategic context and uses it to update its policy online. ISO combines a Strategic Reward Model (SRM) that estimates the long-run strategic value of actions with iso-grpo, a context-conditioned optimistic learning rule. We prove sublinear contextual regret and equilibrium convergence guarantees whose dominant terms scale with the number of context mispredictions; when prediction errors are bounded, our bounds recover the static-game rates obtained when strategic externalities are known. Experiments in 6-player No-Limit Texas Hold'em and competitive Pokemon show consistent improvements in long-term return over strong LLM and RL baselines, and graceful degradation under controlled prediction noise.