TAAM:Inductive Graph-Class Incremental Learning with Task-Aware Adaptive Modulation
作者: Jingtao Liu, Xinming Zhang
分类: cs.LG
发布日期: 2026-02-08
🔗 代码/项目: GITHUB
💡 一句话要点
提出TAAM,通过任务感知自适应调制解决图分类增量学习中的灾难性遗忘问题。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 图持续学习 增量学习 灾难性遗忘 图神经网络 自适应调制
📋 核心要点
- 现有图持续学习方法依赖回放策略,存在内存限制、隐私泄露和灾难性遗忘等问题。
- TAAM通过为每个任务训练并冻结轻量级神经突触调制器(NSM),实现任务特定知识的存储和利用。
- 实验表明,TAAM在多个数据集上显著优于现有方法,并在更严格的归纳学习场景下验证了有效性。
📝 摘要(中文)
图持续学习(GCL)旨在解决流式图数据带来的挑战。然而,当前方法通常依赖于基于回放的策略,这引发了诸如内存限制和隐私问题等担忧,同时也难以解决稳定性-可塑性困境。本文提出轻量级的、特定于任务的模块可以有效地指导固定GNN骨干网络的推理过程。基于此,我们提出了任务感知自适应调制(TAAM)。TAAM的关键组件是其轻量级的神经突触调制器(NSM)。对于每个新任务,训练一个专用的NSM并将其冻结,作为“专家模块”。这些模块对共享GNN骨干网络的计算流执行细粒度的、节点关注的自适应调制。这种设置确保了新知识保留在紧凑的、特定于任务的模块中,自然地防止了灾难性遗忘,而无需任何数据回放。此外,为了解决实际场景中未知任务ID的重要挑战,我们提出了一种名为锚定多跳传播(AMP)的新方法,并进行了理论证明。值得注意的是,我们发现现有的GCL基准测试存在可能导致数据泄露和有偏评估的缺陷。因此,我们在更严格的归纳学习场景中进行了所有实验。大量实验表明,TAAM在八个数据集上全面优于最先进的方法。
🔬 方法详解
问题定义:论文旨在解决图分类增量学习(Graph-Class Incremental Learning)中的灾难性遗忘问题。现有方法,特别是基于回放的策略,在处理连续的图数据流时,面临着内存限制、隐私泄露以及稳定性-可塑性之间的权衡难题。此外,现有GCL基准测试存在数据泄露和有偏评估的风险。
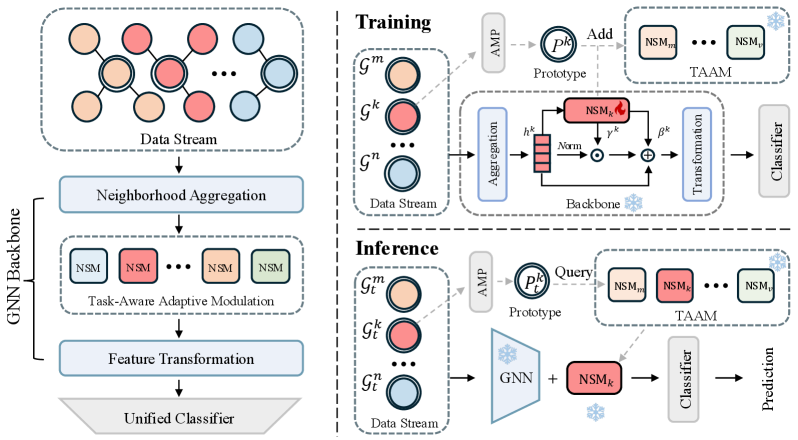
核心思路:论文的核心思路是利用轻量级的、任务特定的模块来引导一个固定的GNN骨干网络的推理过程。通过为每个新任务训练一个独立的“专家模块”(即神经突触调制器NSM),并将新知识存储在这些紧凑的模块中,从而避免对先前任务的知识造成干扰,实现知识的增量积累。
技术框架:TAAM的整体框架包含一个共享的GNN骨干网络和多个神经突触调制器(NSM)。对于每个新任务,训练一个NSM,该NSM对GNN骨干网络的计算流进行节点级别的自适应调制。训练完成后,NSM被冻结,作为该任务的“专家模块”。在推理阶段,根据任务ID选择对应的NSM,与GNN骨干网络协同工作,完成图分类任务。对于未知任务ID的情况,论文提出了锚定多跳传播(AMP)方法来推断任务ID。
关键创新:TAAM的关键创新在于神经突触调制器(NSM)的设计和使用方式。NSM是一种轻量级的模块,能够对GNN骨干网络的计算流进行细粒度的、节点关注的自适应调制。通过为每个任务训练一个独立的NSM,并将新知识存储在这些模块中,TAAM有效地防止了灾难性遗忘,而无需使用任何数据回放。此外,AMP方法解决了未知任务ID的挑战。
关键设计:NSM的具体结构未知,但其核心功能是对GNN骨干网络的计算流进行调制。调制的方式是节点级别的,并且是自适应的,这意味着NSM可以根据节点的特征和任务的需求,动态地调整调制参数。损失函数的设计可能包含分类损失和正则化项,以保证模型的性能和泛化能力。AMP方法的具体实现细节未知,但其核心思想是通过多跳传播来推断任务ID。
🖼️ 关键图片

📊 实验亮点
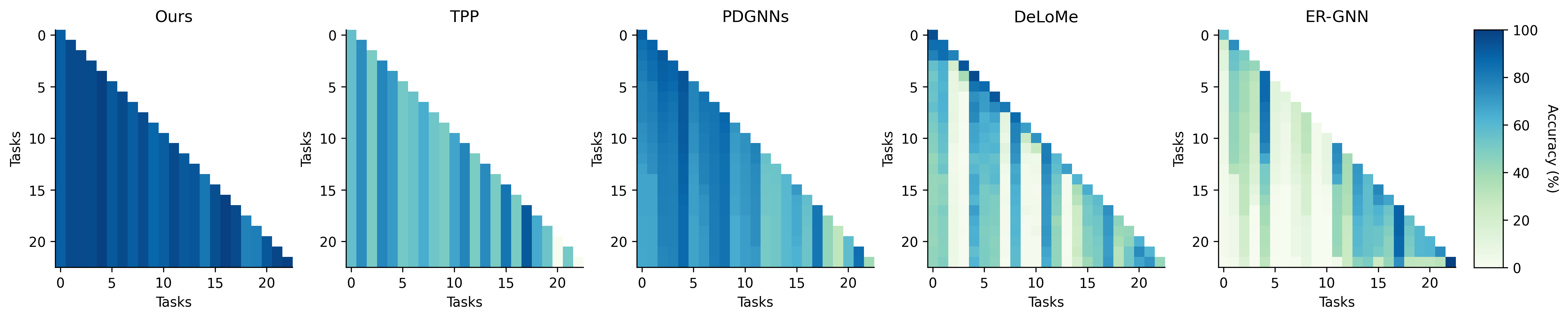
TAAM在八个数据集上进行了广泛的实验,结果表明其性能全面优于最先进的方法。具体的性能提升数据未知,但摘要强调了TAAM在多个数据集上的一致性和显著优势。此外,该论文强调了在更严格的归纳学习场景下进行实验的重要性,并验证了TAAM的有效性。
🎯 应用场景
TAAM可应用于需要持续学习新图结构的场景,例如社交网络演化分析、生物分子结构预测、金融欺诈检测等。该方法无需存储历史数据,保护了用户隐私,并能适应不断变化的数据分布,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Graph Continual Learning (GCL) aims to solve the challenges of streaming graph data. However, current methods often depend on replay-based strategies, which raise concerns like memory limits and privacy issues, while also struggling to resolve the stability-plasticity dilemma. In this paper, we suggest that lightweight, task-specific modules can effectively guide the reasoning process of a fixed GNN backbone. Based on this idea, we propose Task-Aware Adaptive Modulation (TAAM). The key component of TAAM is its lightweight Neural Synapse Modulators (NSMs). For each new task, a dedicated NSM is trained and then frozen, acting as an "expert module." These modules perform detailed, node-attentive adaptive modulation on the computational flow of a shared GNN backbone. This setup ensures that new knowledge is kept within compact, task-specific modules, naturally preventing catastrophic forgetting without using any data replay. Additionally, to address the important challenge of unknown task IDs in real-world scenarios, we propose and theoretically prove a novel method named Anchored Multi-hop Propagation (AMP). Notably, we find that existing GCL benchmarks have flaws that can cause data leakage and biased evaluations. Therefore, we conduct all experiments in a more rigorous inductive learning scenario. Extensive experiments show that TAAM comprehensively outperforms state-of-the-art methods across eight datasets. Code and Datasets are available at: https://github.com/1iuJT/TAAM_AAMAS2026.