Horizon Imagination: Efficient On-Policy Rollout in Diffusion World Models
作者: Lior Cohen, Ofir Nabati, Kaixin Wang, Navdeep Kumar, Shie Mannor
分类: cs.LG
发布日期: 2026-02-08 (更新: 2026-02-17)
备注: This paper will be published in the ICLR 2026 proceedings
🔗 代码/项目: GITHUB
💡 一句话要点
提出Horizon Imagination,加速扩散世界模型在强化学习中的在线Rollout。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 世界模型 强化学习 在线Rollout 并行计算 Atari 100K Craftium
📋 核心要点
- 扩散世界模型在强化学习中面临效率瓶颈,现有方法计算成本高昂,限制了其应用。
- Horizon Imagination (HI) 通过并行去噪未来观测,并引入稳定机制和解耦采样计划来提高效率。
- 实验表明,HI 在降低计算预算的同时,保持了控制性能,并提升了生成质量。
📝 摘要(中文)
本文研究了基于扩散的世界模型在强化学习中的应用。扩散模型虽然具有很高的生成保真度,但在控制方面面临着效率挑战。现有方法要么需要在推理时使用重量级模型,要么依赖于高度串行的想象,这两种方法都会带来过高的计算成本。我们提出了Horizon Imagination (HI),这是一种用于离散随机策略的在线想象过程,可以并行地对多个未来观测进行去噪。HI 包含一个稳定机制和一个新颖的采样计划,该计划将去噪预算与应用去噪的有效范围解耦,同时支持子帧预算。在 Atari 100K 和 Craftium 上的实验表明,我们的方法在去噪步数一半的子帧预算下保持了控制性能,并在不同的时间表下实现了卓越的生成质量。
🔬 方法详解
问题定义:基于扩散的世界模型在强化学习中展现出强大的生成能力,但其计算复杂度限制了在线控制的应用。现有方法,如依赖重型模型或串行想象,导致计算成本过高,难以满足实时性要求。因此,需要一种更高效的在线 rollout 方法,以降低计算负担,同时保持控制性能。
核心思路:Horizon Imagination (HI) 的核心思路是通过并行处理多个未来观测的去噪过程,从而显著减少 rollout 所需的时间。此外,HI 引入了稳定机制,以确保在长时间 rollout 中的稳定性。通过解耦去噪预算和有效 horizon,HI 允许在更短的时间内模拟更长的未来轨迹。
技术框架:HI 的整体框架包含以下几个主要步骤:1) 从当前状态开始,根据策略采样一系列动作。2) 并行地对多个未来观测进行去噪,利用扩散模型预测下一状态。3) 使用稳定机制来防止 rollout 过程中的崩溃。4) 根据采样计划调整去噪过程,以平衡计算成本和生成质量。5) 基于想象的未来轨迹,优化策略。
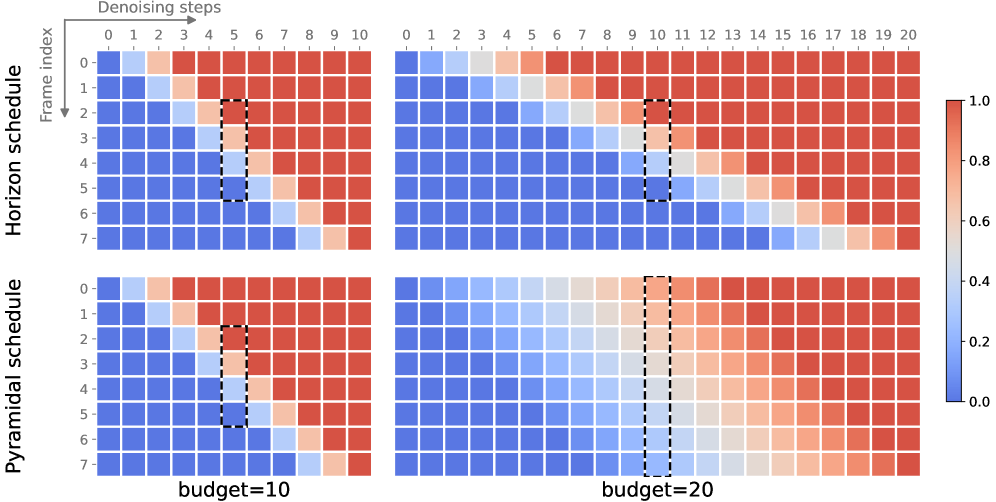
关键创新:HI 的关键创新在于其并行去噪过程和解耦采样计划。传统的扩散模型通常需要串行地进行去噪,而 HI 允许同时处理多个未来观测,从而显著提高了效率。解耦采样计划允许在有限的计算预算下,模拟更长的未来轨迹,从而提高了控制性能。
关键设计:HI 的关键设计包括:1) 稳定机制,例如梯度裁剪或正则化,以防止 rollout 过程中的崩溃。2) 解耦采样计划,允许独立控制去噪步数和有效 horizon。3) 子帧预算,允许在更短的时间内完成去噪过程。4) 损失函数,用于训练扩散模型,例如均方误差或交叉熵。
🖼️ 关键图片

📊 实验亮点
在 Atari 100K 和 Craftium 上的实验表明,Horizon Imagination 在去噪步数减半的情况下,仍然保持了与现有方法相当的控制性能。此外,HI 在不同的采样计划下,实现了更高的生成质量,证明了其在效率和性能之间的良好平衡。
🎯 应用场景
Horizon Imagination 有潜力应用于各种需要高效在线控制的强化学习任务,例如机器人导航、游戏 AI 和自动驾驶。该方法可以降低计算成本,提高控制性能,并支持更长的规划 horizon,从而实现更智能、更自主的智能体。
📄 摘要(原文)
We study diffusion-based world models for reinforcement learning, which offer high generative fidelity but face critical efficiency challenges in control. Current methods either require heavyweight models at inference or rely on highly sequential imagination, both of which impose prohibitive computational costs. We propose Horizon Imagination (HI), an on-policy imagination process for discrete stochastic policies that denoises multiple future observations in parallel. HI incorporates a stabilization mechanism and a novel sampling schedule that decouples the denoising budget from the effective horizon over which denoising is applied while also supporting sub-frame budgets. Experiments on Atari 100K and Craftium show that our approach maintains control performance with a sub-frame budget of half the denoising steps and achieves superior generation quality under varied schedules. Code is available at https://github.com/leor-c/horizon-imagination.