The Rise of Sparse Mixture-of-Experts: A Survey from Algorithmic Foundations to Decentralized Architectures and Vertical Domain Applications
作者: Dong Pan, Bingtao Li, Yongsheng Zheng, Jiren Ma, Victor Fei
分类: cs.LG, cs.AI
发布日期: 2026-02-08
期刊: Journal of Computer Science and Artificial Intelligence 5 (2025) 25-41
💡 一句话要点
稀疏混合专家模型综述:从算法基础到去中心化架构与垂直领域应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 稀疏计算 去中心化架构 大型语言模型 深度学习 模型扩展 垂直领域应用 路由网络
📋 核心要点
- 现有MoE综述缺乏对关键领域的深入探索,限制了研究人员对该领域最新进展的全面理解。
- 本文深入探讨MoE的核心组件(路由网络和专家网络),并扩展到去中心化架构,以提升可扩展性和成本效益。
- 综述涵盖MoE在垂直领域的应用,并识别了关键挑战和未来研究方向,为研究人员和从业者提供参考。
📝 摘要(中文)
稀疏混合专家(MoE)架构已经发展成为一种强大的方法,可以用相当的计算成本将深度学习模型扩展到更多的参数。作为大型语言模型(LLM)的一个重要分支,MoE模型仅基于路由网络激活一部分专家。这种稀疏条件计算机制显著提高了计算效率,为更大的可扩展性和成本效率铺平了一条有希望的道路。它不仅增强了自然语言处理、计算机视觉和多模态等水平领域的下游应用,而且在垂直领域也表现出广泛的适用性。尽管MoE模型在各个领域的普及和应用日益增长,但对MoE在许多重要领域的最新进展缺乏系统的探索。现有的MoE综述存在覆盖面不足或对关键领域没有进行广泛探索等局限性。本文旨在填补这些空白。首先,我们研究了MoE的基本原理,深入探讨了其核心组件——路由网络和专家网络。随后,我们超越了集中式范式,扩展到去中心化范式,这释放了去中心化基础设施的巨大潜力,使更广泛的社区能够实现MoE开发的民主化,并提供更大的可扩展性和成本效率。此外,我们专注于探索其垂直领域的应用。最后,我们还确定了关键挑战和有希望的未来研究方向。据我们所知,本综述是目前MoE领域最全面的综述。我们希望本文能够成为研究人员和从业人员的宝贵资源,使他们能够了解并及时掌握最新的进展。
🔬 方法详解
问题定义:现有MoE综述存在覆盖面不足,对关键领域(如去中心化架构、垂直领域应用)的探索不够深入,导致研究人员难以全面了解MoE的最新进展和潜在应用。此外,如何利用去中心化基础设施进一步提升MoE的可扩展性和成本效益也是一个重要问题。
核心思路:本文旨在通过系统性地回顾MoE的算法基础、去中心化架构以及在垂直领域的应用,填补现有综述的空白。核心思路是全面梳理MoE的发展脉络,深入分析其核心组件和关键技术,并展望未来的研究方向,为研究人员和从业者提供一个全面的参考框架。
技术框架:本文的整体框架包括以下几个主要部分:1) MoE的基础原理,包括路由网络和专家网络;2) 从集中式到去中心化的MoE架构演进;3) MoE在垂直领域的应用,如自然语言处理、计算机视觉等;4) MoE面临的挑战和未来的研究方向。每个部分都包含了对相关文献的详细回顾和分析。
关键创新:本文的关键创新在于对MoE的去中心化架构和垂直领域应用进行了更全面的探索。现有综述通常侧重于MoE的算法基础和在通用领域的应用,而本文则更加关注如何利用去中心化基础设施提升MoE的可扩展性和成本效益,以及MoE在特定垂直领域的应用潜力。
关键设计:本文的关键设计在于其系统性的综述结构,从MoE的基础原理到去中心化架构,再到垂直领域应用,最后展望未来研究方向。这种结构化的方式使得读者能够更容易地理解MoE的发展脉络和关键技术。此外,本文还对每个部分的关键文献进行了详细的分析和总结,为读者提供了深入了解MoE的入口。
🖼️ 关键图片
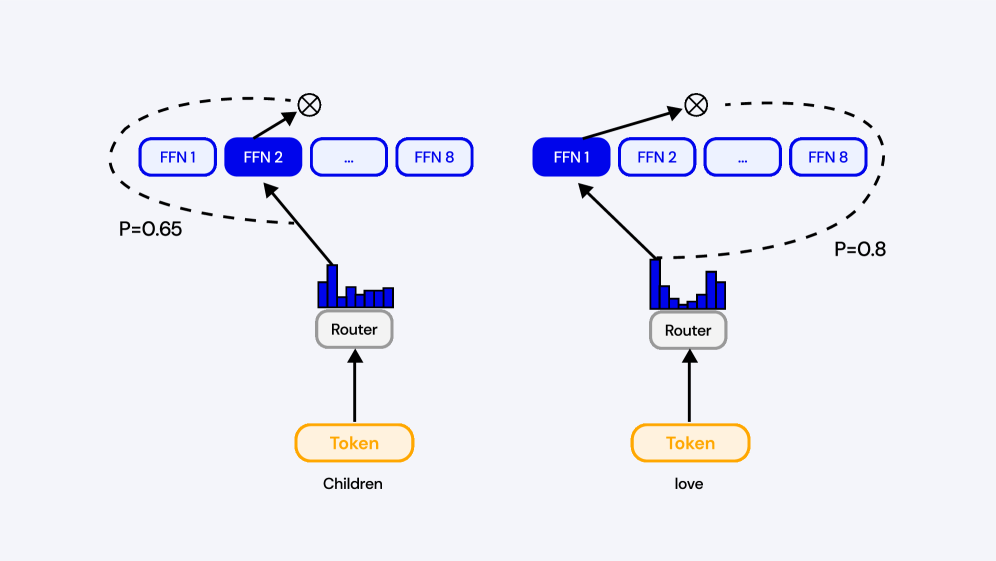


📊 实验亮点
本文是目前最全面的MoE综述,涵盖了从算法基础到去中心化架构和垂直领域应用的各个方面。它不仅回顾了MoE的核心组件和关键技术,还对MoE的未来发展方向进行了展望,为研究人员和从业者提供了宝贵的参考。
🎯 应用场景
该研究成果可应用于各种需要大规模模型和高效计算的场景,例如自然语言处理中的大型语言模型训练、计算机视觉中的图像识别和生成、以及多模态学习等。通过利用稀疏混合专家模型,可以在保证模型性能的同时,显著降低计算成本,从而加速相关领域的发展。
📄 摘要(原文)
The sparse Mixture of Experts(MoE) architecture has evolved as a powerful approach for scaling deep learning models to more parameters with comparable computation cost. As an important branch of large language model(LLM), MoE model only activate a subset of experts based on a routing network. This sparse conditional computation mechanism significantly improves computational efficiency, paving a promising path for greater scalability and cost-efficiency. It not only enhance downstream applications such as natural language processing, computer vision, and multimodal in various horizontal domains, but also exhibit broad applicability across vertical domains. Despite the growing popularity and application of MoE models across various domains, there lacks a systematic exploration of recent advancements of MoE in many important fields. Existing surveys on MoE suffer from limitations such as lack coverage or none extensively exploration of key areas. This survey seeks to fill these gaps. In this paper, Firstly, we examine the foundational principles of MoE, with an in-depth exploration of its core components-the routing network and expert network. Subsequently, we extend beyond the centralized paradigm to the decentralized paradigm, which unlocks the immense untapped potential of decentralized infrastructure, enables democratization of MoE development for broader communities, and delivers greater scalability and cost-efficiency. Furthermore we focus on exploring its vertical domain applications. Finally, we also identify key challenges and promising future research directions. To the best of our knowledge, this survey is currently the most comprehensive review in the field of MoE. We aim for this article to serve as a valuable resource for both researchers and practitioners, enabling them to navigate and stay up-to-date with the latest advancements.