From $O(mn)$ to $O(r^2)$: Two-Sided Low-Rank Communication for Adam in Distributed Training with Memory Efficiency
作者: Sizhe Dang, Jiaqi Shao, Xiaodong Zheng, Guang Dai, Yan Song, Haishan Ye
分类: cs.LG, cs.AI
发布日期: 2026-02-08
🔗 代码/项目: GITHUB
💡 一句话要点
提出TSR-Adam,通过双边低秩通信显著降低分布式训练中的通信开销。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式训练 低秩优化 通信优化 Adam优化器 随机SVD 双边低秩通信 梯度压缩 深度学习
📋 核心要点
- 数据并行分布式训练中,梯度同步受限于带宽,成为预训练瓶颈。
- 提出TSR-Adam,通过双边低秩通信同步梯度核心,降低通信量。
- 实验表明,TSR-Adam在预训练和微调中显著减少通信量,性能相当。
📝 摘要(中文)
随着基础模型规模的持续扩大,预训练越来越依赖于数据并行分布式优化,这使得受带宽限制的梯度同步成为关键瓶颈。正交地,基于投影的低秩优化器主要为内存效率而设计,但在通信受限的训练中仍然不是最优的:单边同步仍然需要传输一个O(rn)的对象,对于一个m×n的矩阵梯度,刷新步骤可能会占据峰值通信字节的大部分。我们提出了TSR,它通过同步一个紧凑的核心U⊤GV∈ℝ^{r×r},将双边低秩通信引入到Adam系列更新(TSR-Adam)中,从而将主要的每步有效载荷从O(mn)降低到O(r^2),同时将动量状态保持在低维核心中。为了进一步减少子空间刷新带来的峰值通信,TSR-Adam采用了一种基于随机SVD的刷新方法,避免了全梯度同步。我们还扩展了低秩通信到具有特定于嵌入的秩和刷新计划的嵌入梯度,从而在保持嵌入密集的情况下,实现了额外的通信和内存节省。在从60M到1B模型规模的预训练中,TSR-Adam将每步平均通信字节数减少了13倍,在GLUE微调中,它将通信减少了25倍,同时实现了相当的性能;我们进一步为所提出的更新提供了理论平稳性分析。代码可在https://github.com/DKmiyan/TSR-Adam获得。
🔬 方法详解
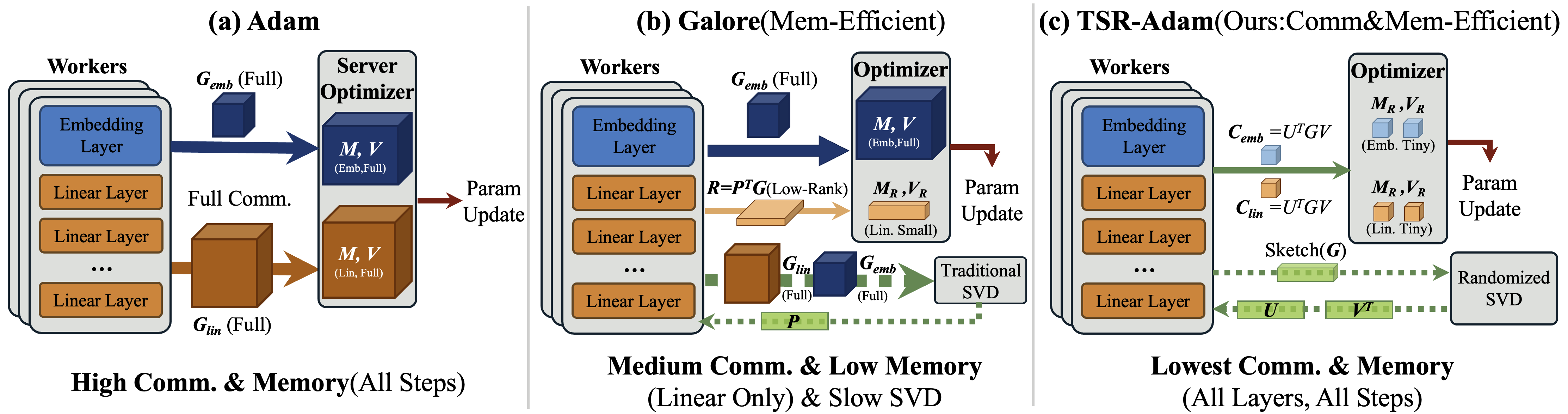
问题定义:在大规模分布式训练中,梯度同步是主要的通信瓶颈。传统的Adam优化器需要同步整个梯度矩阵,这在带宽受限的环境下效率低下。现有的低秩优化器虽然降低了内存占用,但在通信方面仍然需要传输较大的梯度投影,尤其是在子空间刷新时,通信开销巨大。
核心思路:TSR-Adam的核心思想是利用双边低秩分解,只同步梯度矩阵的一个低秩核心。通过将梯度矩阵分解为三个矩阵的乘积,并只同步中间的低秩矩阵,可以显著减少通信量。此外,采用随机SVD进行子空间刷新,避免了全梯度同步,进一步降低了峰值通信量。
技术框架:TSR-Adam的整体框架包括以下几个主要步骤:1) 在每个worker上计算局部梯度;2) 对局部梯度进行低秩分解,得到三个矩阵;3) 同步中间的低秩核心矩阵;4) 在每个worker上使用同步后的低秩核心矩阵更新模型参数;5) 定期使用随机SVD刷新低秩子空间。
关键创新:TSR-Adam的关键创新在于双边低秩通信。与传统的单边低秩通信相比,双边低秩通信只需要同步一个更小的低秩核心矩阵,从而显著降低了通信量。此外,随机SVD刷新方法避免了全梯度同步,进一步降低了峰值通信量。针对embedding梯度,采用embedding-specific的秩和刷新策略,进一步优化了通信和内存。
关键设计:TSR-Adam的关键设计包括:1) 低秩分解的秩r的选择,需要根据具体问题进行调整,以平衡通信量和模型性能;2) 随机SVD刷新的频率,需要根据梯度变化情况进行调整,以保证子空间的有效性;3) embedding-specific的秩和刷新策略,需要根据embedding的重要性进行调整。
🖼️ 关键图片

📊 实验亮点
TSR-Adam在60M到1B模型规模的预训练中,将每步平均通信字节数减少了13倍。在GLUE微调任务中,TSR-Adam将通信量减少了25倍,同时保持了与传统Adam优化器相当的性能。这些实验结果表明,TSR-Adam能够显著降低分布式训练中的通信开销,提高训练效率。
🎯 应用场景
TSR-Adam适用于大规模分布式训练,尤其是在带宽受限的环境下。它可以应用于各种深度学习模型,包括自然语言处理、计算机视觉和推荐系统等。通过降低通信开销,TSR-Adam可以加速模型训练,并降低训练成本,使得更大规模的模型训练成为可能。该方法对于资源受限的场景,例如边缘计算和移动设备上的模型训练,也具有重要意义。
📄 摘要(原文)
As foundation models continue to scale, pretraining increasingly relies on data-parallel distributed optimization, making bandwidth-limited gradient synchronization a key bottleneck. Orthogonally, projection-based low-rank optimizers were mainly designed for memory efficiency, but remain suboptimal for communication-limited training: one-sided synchronization still transmits an $O(rn)$ object for an $m\times n$ matrix gradient and refresh steps can dominate peak communicated bytes. We propose TSR, which brings two-sided low-rank communication to Adam-family updates (TSR-Adam) by synchronizing a compact core $U^\top G V\in\mathbb{R}^{r\times r}$, reducing the dominant per-step payload from $O(mn)$ to $O(r^2)$ while keeping moment states in low-dimensional cores. To further reduce the peak communication from subspace refresh, TSR-Adam adopts a randomized SVD-based refresh that avoids full-gradient synchronization. We additionally extend low-rank communication to embedding gradients with embedding-specific ranks and refresh schedules, yielding additional communication and memory savings over keeping embeddings dense. Across pretraining from 60M to 1B model scales, TSR-Adam reduces average communicated bytes per step by $13\times$, and on GLUE fine-tuning it reduces communication by $25\times$, while achieving comparable performance; we further provide a theoretical stationarity analysis for the proposed update. Code is available at https://github.com/DKmiyan/TSR-Adam.