CausalArmor: Efficient Indirect Prompt Injection Guardrails via Causal Attribution
作者: Minbeom Kim, Mihir Parmar, Phillip Wallis, Lesly Miculicich, Kyomin Jung, Krishnamurthy Dj Dvijotham, Long T. Le, Tomas Pfister
分类: cs.CR, cs.LG, stat.ME
发布日期: 2026-02-08
💡 一句话要点
CausalArmor:利用因果归因实现高效的间接提示注入防御
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 间接提示注入 因果归因 AI安全 选择性防御 思维链掩蔽
📋 核心要点
- 现有防御间接提示注入攻击的方法,存在过度防御问题,导致不必要的性能开销。
- CausalArmor通过因果归因识别恶意注入,仅在必要时进行清理,实现选择性防御。
- 实验表明,CausalArmor在保证安全性的同时,显著提升了AI Agent的效用和降低了延迟。
📝 摘要(中文)
配备工具调用能力的AI Agent容易受到间接提示注入(IPI)攻击。在这种攻击场景中,隐藏在不可信内容中的恶意命令会诱骗Agent执行未经授权的操作。现有的防御措施虽然可以降低攻击成功率,但往往面临过度防御的困境:它们部署昂贵的、始终在线的清理机制,而不管实际威胁如何,从而降低了效用和延迟,即使在良性场景中也是如此。我们从因果消融的角度重新审视IPI:成功的注入表现为一种主导地位的转变,即用户请求不再为Agent的特权行为提供决定性的支持,而特定的不可信片段(如检索到的文档或工具输出)提供了不成比例的可归因影响。基于这种特征,我们提出了CausalArmor,一种选择性防御框架,它(i)在特权决策点计算轻量级的、基于留一消融的归因,以及(ii)仅当不可信片段主导用户意图时才触发有针对性的清理。此外,CausalArmor采用追溯性的思维链掩蔽,以防止Agent对“中毒”的推理轨迹采取行动。我们提出了一个理论分析,表明基于归因裕度的清理有条件地产生了一个指数小的恶意行为选择概率上限。在AgentDojo和DoomArena上的实验表明,CausalArmor在保持AI Agent的效用和延迟的同时,匹配了激进防御的安全性,并提高了可解释性。
🔬 方法详解
问题定义:论文旨在解决AI Agent中存在的间接提示注入(IPI)攻击问题。现有防御方法,如始终开启的清理机制,会造成过度防御,即使在没有攻击的情况下也会降低Agent的效用和增加延迟。因此,需要一种更高效、更具选择性的防御机制。
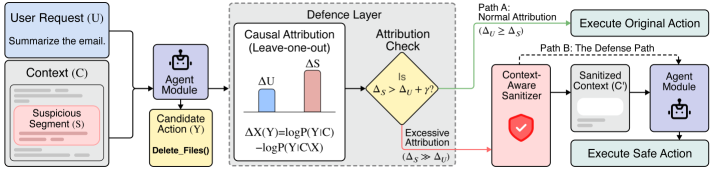
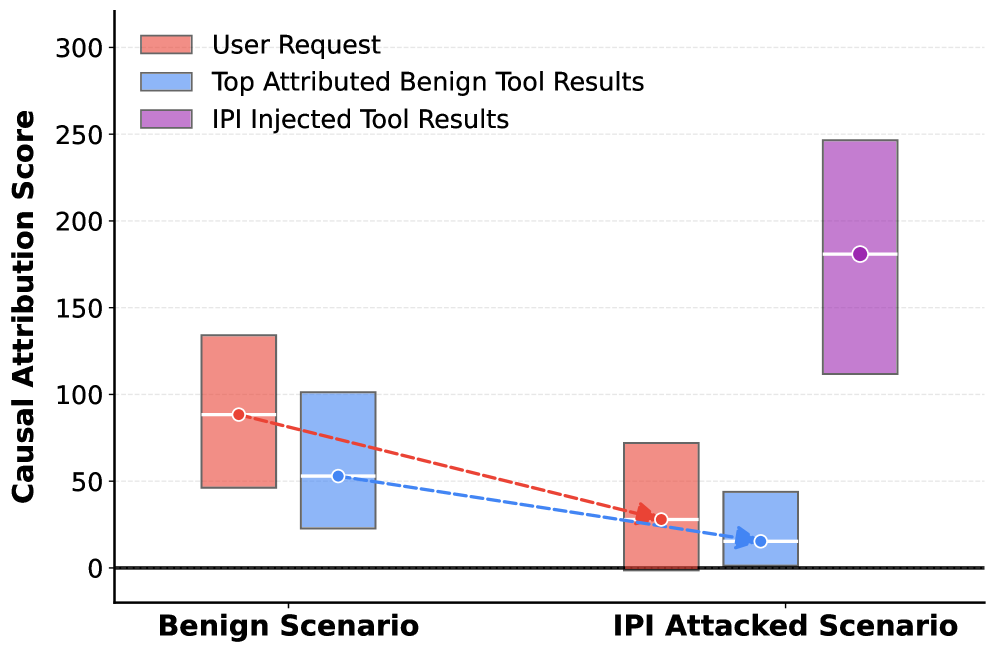
核心思路:论文的核心思路是利用因果归因来识别IPI攻击。成功的IPI攻击会导致Agent的决策不再主要依赖用户意图,而是受到不可信来源(如检索到的文档)的影响。通过分析Agent决策过程中各个输入来源的因果贡献,可以检测到这种影响力的转移,从而判断是否存在攻击。
技术框架:CausalArmor框架包含两个主要阶段:1) 因果归因计算:在Agent做出特权决策的关键时刻,使用留一消融法计算各个输入来源(包括用户请求和不可信片段)的因果归因。2) 选择性清理:如果某个不可信片段的归因显著高于用户意图的归因,则触发有针对性的清理。此外,CausalArmor还采用追溯性的思维链掩蔽,防止Agent基于“中毒”的推理轨迹做出决策。
关键创新:CausalArmor的关键创新在于将因果归因应用于IPI攻击检测,并基于归因结果实现选择性防御。与现有方法相比,CausalArmor避免了不必要的清理操作,从而提高了效率和效用。此外,追溯性的思维链掩蔽进一步增强了防御能力。
关键设计:CausalArmor使用留一消融法计算因果归因,具体而言,对于每个输入来源,暂时移除该来源,观察Agent决策的变化。决策变化越大,说明该来源的因果贡献越大。论文还定义了一个归因裕度,用于衡量不可信片段的归因与用户意图的归因之间的差距。当归因裕度超过某个阈值时,触发清理操作。此外,思维链掩蔽通过屏蔽“中毒”的推理步骤,防止Agent受到恶意信息的影响。
🖼️ 关键图片
📊 实验亮点
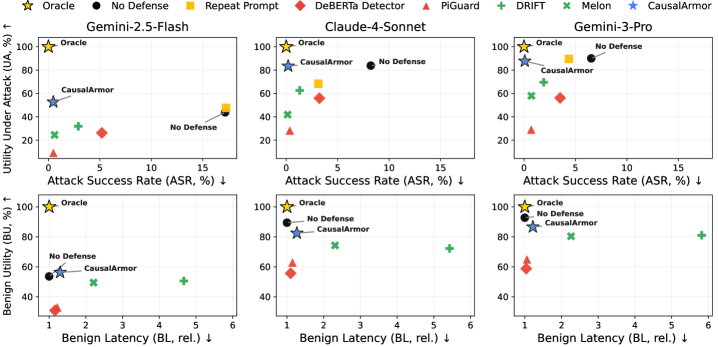
实验结果表明,CausalArmor在AgentDojo和DoomArena两个基准测试中,能够达到与激进防御相当的安全性,同时显著提高了AI Agent的效用和降低了延迟。具体而言,CausalArmor在保持攻击防御能力的同时,避免了不必要的清理操作,从而提高了Agent的响应速度和任务完成质量。
🎯 应用场景
CausalArmor可应用于各种配备工具调用能力的AI Agent,例如智能助手、自动化客服、以及需要访问外部信息或执行复杂任务的机器人。该研究的实际价值在于提高AI Agent的安全性,同时保持其效用和效率,从而促进AI技术在更广泛领域的应用。未来,CausalArmor可以扩展到防御更复杂的攻击,并与其他防御机制相结合,构建更强大的安全体系。
📄 摘要(原文)
AI agents equipped with tool-calling capabilities are susceptible to Indirect Prompt Injection (IPI) attacks. In this attack scenario, malicious commands hidden within untrusted content trick the agent into performing unauthorized actions. Existing defenses can reduce attack success but often suffer from the over-defense dilemma: they deploy expensive, always-on sanitization regardless of actual threat, thereby degrading utility and latency even in benign scenarios. We revisit IPI through a causal ablation perspective: a successful injection manifests as a dominance shift where the user request no longer provides decisive support for the agent's privileged action, while a particular untrusted segment, such as a retrieved document or tool output, provides disproportionate attributable influence. Based on this signature, we propose CausalArmor, a selective defense framework that (i) computes lightweight, leave-one-out ablation-based attributions at privileged decision points, and (ii) triggers targeted sanitization only when an untrusted segment dominates the user intent. Additionally, CausalArmor employs retroactive Chain-of-Thought masking to prevent the agent from acting on ``poisoned'' reasoning traces. We present a theoretical analysis showing that sanitization based on attribution margins conditionally yields an exponentially small upper bound on the probability of selecting malicious actions. Experiments on AgentDojo and DoomArena demonstrate that CausalArmor matches the security of aggressive defenses while improving explainability and preserving utility and latency of AI agents.