Adaptive Acquisition Selection for Bayesian Optimization with Large Language Models
作者: Giang Ngo, Dat Phan Trong, Dang Nguyen, Sunil Gupta, Svetha Venkatesh
分类: cs.LG, cs.AI
发布日期: 2026-02-08
💡 一句话要点
提出LMABO,利用大语言模型自适应选择贝叶斯优化中的采集函数
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯优化 大语言模型 自适应学习 采集函数选择 零样本学习
📋 核心要点
- 现有贝叶斯优化方法在选择采集函数时缺乏自适应性,忽略了剩余预算和代理模型等关键信息。
- LMABO框架利用预训练大语言模型,根据优化过程的实时状态,动态选择最佳采集函数。
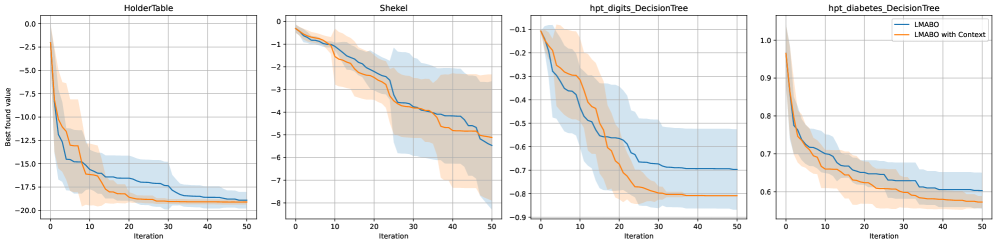
- 实验结果表明,LMABO在多个基准测试中显著优于静态、自适应组合以及其他基于LLM的基线方法。
📝 摘要(中文)
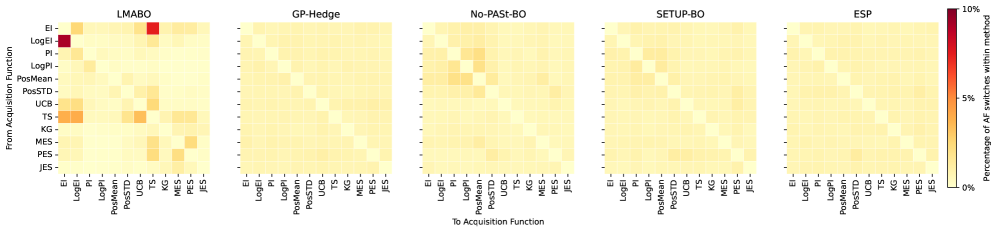
贝叶斯优化(BO)的关键在于采集函数的选择,但没有一种策略是普遍最优的;最佳选择具有非平稳性和问题依赖性。现有的自适应组合方法通常基于过去的函数值进行决策,而忽略了更丰富的信息,如剩余预算或代理模型特征。为了解决这个问题,我们引入了LMABO,这是一个新颖的框架,它将预训练的大语言模型(LLM)作为BO过程的零样本、在线策略器。在每次迭代中,LMABO使用结构化的状态表示来提示LLM从不同的组合中选择最合适的采集函数。在对50个基准问题的评估中,LMABO展示了相对于强大的静态、自适应组合和其他基于LLM的基线的显著性能提升。我们表明,LLM的行为是一种综合策略,可以适应实时进展,证明了其优势源于其能够处理和综合完整的优化状态,从而形成有效的自适应策略。
🔬 方法详解
问题定义:贝叶斯优化中采集函数的选择至关重要,但现有方法难以根据优化过程的动态变化自适应地选择最佳采集函数。现有自适应方法主要依赖于历史函数值,忽略了剩余预算、代理模型特征等重要信息,导致优化效率受限。
核心思路:LMABO的核心思路是将预训练的大语言模型(LLM)作为一个在线策略器,利用其强大的上下文理解和推理能力,根据贝叶斯优化过程的实时状态,动态选择最合适的采集函数。通过将优化状态编码为LLM可理解的提示,使LLM能够像专家一样进行决策。
技术框架:LMABO的整体框架包括以下几个主要模块:1) 状态表示模块:将贝叶斯优化过程的当前状态(包括已评估的点、函数值、剩余预算、代理模型信息等)编码为结构化的提示。2) LLM策略器:使用预训练的LLM,接收状态表示模块的输出作为输入,预测最佳采集函数。3) 采集函数组合:维护一个包含多种采集函数的组合,LLM策略器从中选择。4) 贝叶斯优化循环:根据LLM选择的采集函数,进行下一轮的采样和评估。
关键创新:LMABO的关键创新在于将大语言模型引入贝叶斯优化,并将其作为一个自适应的采集函数选择器。与传统的基于规则或历史信息的选择方法不同,LMABO能够利用LLM的推理能力,综合考虑各种因素,做出更明智的决策。此外,LMABO采用零样本学习的方式,无需针对特定问题进行训练。
关键设计:状态表示模块的设计至关重要,需要将贝叶斯优化的状态信息有效地编码为LLM可以理解的文本。提示工程是关键,需要设计合适的提示模板,引导LLM做出正确的决策。此外,采集函数组合的多样性也很重要,需要包含各种类型的采集函数,以适应不同的优化场景。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
LMABO在50个基准问题上进行了评估,实验结果表明,LMABO显著优于静态采集函数选择策略、自适应组合方法以及其他基于LLM的基线方法。具体性能数据和提升幅度在论文中进行了详细展示,证明了LMABO的有效性和优越性。
🎯 应用场景
LMABO可应用于各种需要贝叶斯优化的场景,例如超参数优化、材料设计、药物发现等。该方法能够显著提升优化效率,降低实验成本,加速科学研究和工程开发的进程。未来,LMABO有望与其他AI技术结合,实现更智能、更高效的自动化优化。
📄 摘要(原文)
Bayesian Optimization critically depends on the choice of acquisition function, but no single strategy is universally optimal; the best choice is non-stationary and problem-dependent. Existing adaptive portfolio methods often base their decisions on past function values while ignoring richer information like remaining budget or surrogate model characteristics. To address this, we introduce LMABO, a novel framework that casts a pre-trained Large Language Model (LLM) as a zero-shot, online strategist for the BO process. At each iteration, LMABO uses a structured state representation to prompt the LLM to select the most suitable acquisition function from a diverse portfolio. In an evaluation across 50 benchmark problems, LMABO demonstrates a significant performance improvement over strong static, adaptive portfolio, and other LLM-based baselines. We show that the LLM's behavior is a comprehensive strategy that adapts to real-time progress, proving its advantage stems from its ability to process and synthesize the complete optimization state into an effective, adaptive policy.