Safety Alignment as Continual Learning: Mitigating the Alignment Tax via Orthogonal Gradient Projection
作者: Guanglong Sun, Siyuan Zhang, Liyuan Wang, Jun Zhu, Hang Su, Yi Zhong
分类: cs.LG, cs.CL
发布日期: 2026-02-08
🔗 代码/项目: GITHUB
💡 一句话要点
提出OGPSA,通过正交梯度投影缓解安全对齐中的能力遗忘问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 持续学习 正交梯度投影 能力保留 对齐税 监督微调 直接偏好优化
📋 核心要点
- 现有安全对齐方法在提升模型安全性的同时,往往会损害模型的通用能力,即产生“对齐税”。
- 论文提出OGPSA方法,通过正交梯度投影,在安全对齐过程中尽量避免覆盖模型已有的通用能力。
- 实验结果表明,OGPSA在SFT、DPO和SFT->DPO等多种设置下,均能有效提升安全性和通用能力的帕累托前沿。
📝 摘要(中文)
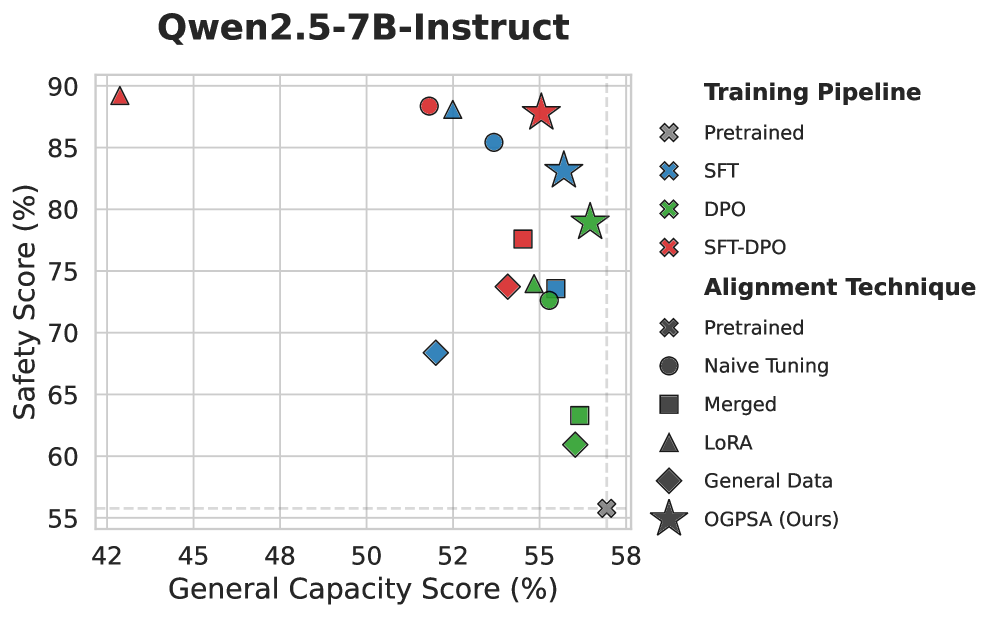
大型语言模型(LLMs)常常面临对齐税:安全后训练会降低通用能力(例如,推理和编码)。我们认为这种税收主要源于顺序对齐中的持续学习式遗忘,其中分布偏移和冲突目标导致安全更新覆盖了预训练的能力。因此,我们将安全对齐视为一个持续学习(CL)问题,必须平衡可塑性(获取安全约束)和稳定性(保持通用能力)。我们提出用于安全对齐的正交梯度投影(OGPSA),这是一种轻量级方法,通过将每个安全更新约束为与捕获通用能力的学习子空间正交(在一阶意义上)来减轻干扰。具体来说,OGPSA从一个小参考集上的梯度估计一个低秩能力子空间,并将安全梯度投影到其正交补空间上,然后再进行更新。这产生了安全导向的更新,在保留对齐能力的同时,最大限度地减少了对先前知识的扰动。OGPSA是即插即用的,并集成到标准后训练流程中,无需大规模重放、辅助目标或重新训练。在监督微调(SFT)、直接偏好优化(DPO)和顺序SFT$ ightarrow$DPO设置中,OGPSA始终优于标准基线,从而改善了安全-效用帕累托前沿。例如,在SFT$ ightarrow$DPO下的Qwen2.5-7B-Instruct上,OGPSA在保持强大安全性的同时恢复了通用能力,将SimpleQA从0.53%提高到3.03%,将IFEval从51.94%提高到63.96%。
🔬 方法详解
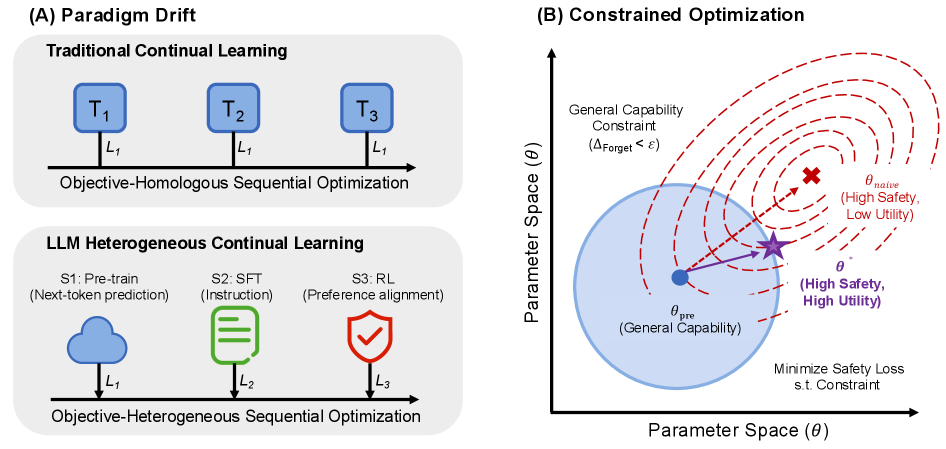
问题定义:现有的大型语言模型安全对齐方法,例如监督微调(SFT)和直接偏好优化(DPO),在提升模型安全性的同时,往往会降低模型在通用任务上的性能,即产生所谓的“对齐税”。这种现象的根本原因是,安全对齐过程类似于持续学习,新的安全知识会覆盖或干扰模型已有的通用能力。
核心思路:论文的核心思路是将安全对齐视为一个持续学习问题,并借鉴持续学习中的方法来解决“对齐税”问题。具体来说,论文提出正交梯度投影(OGPSA)方法,其核心思想是在更新模型参数时,将安全相关的梯度投影到与通用能力相关的子空间的正交补空间上。这样可以确保安全更新主要影响与安全相关的参数,而尽量不干扰模型已有的通用能力。
技术框架:OGPSA方法可以集成到标准的后训练流程中,无需大规模重放、辅助目标或重新训练。其主要步骤包括:1)使用少量参考数据计算通用能力子空间;2)计算安全相关的梯度;3)将安全梯度投影到通用能力子空间的正交补空间上;4)使用投影后的梯度更新模型参数。
关键创新:OGPSA的关键创新在于利用正交梯度投影来解耦安全更新和通用能力。与传统的安全对齐方法相比,OGPSA能够更有效地平衡安全性和通用能力,从而缓解“对齐税”问题。OGPSA无需大规模重放或额外的训练目标,易于集成到现有的安全对齐流程中。
关键设计:OGPSA的关键设计包括:1)使用低秩近似来估计通用能力子空间,以降低计算复杂度;2)使用一阶梯度信息来近似参数空间的正交性;3)使用少量参考数据来计算通用能力子空间,以避免引入额外的训练成本。具体而言,作者使用SVD分解来估计低秩能力子空间,并使用投影矩阵将安全梯度投影到其正交补空间。损失函数与标准SFT或DPO相同,但梯度更新时会进行正交投影。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OGPSA在Qwen2.5-7B-Instruct模型上,使用SFT->DPO流程进行安全对齐时,能够在保持强大安全性的同时,显著提升通用能力。例如,在SimpleQA任务上,OGPSA将性能从0.53%提升到3.03%,在IFEval任务上,将性能从51.94%提升到63.96%。这些结果表明,OGPSA能够有效缓解“对齐税”问题,提升安全对齐的效率。
🎯 应用场景
OGPSA方法可以广泛应用于大型语言模型的安全对齐,尤其是在需要平衡安全性和通用能力的场景下。例如,可以用于提升聊天机器人的安全性,同时保持其在知识问答、文本生成等方面的能力。该方法还可以应用于其他机器学习模型的安全对齐,例如图像分类器和目标检测器。
📄 摘要(原文)
Large Language Models (LLMs) often incur an alignment tax: safety post-training can reduce general utility (e.g., reasoning and coding). We argue that this tax primarily arises from continual-learning-style forgetting in sequential alignment, where distribution shift and conflicting objectives cause safety updates to overwrite pre-trained competencies. Accordingly, we cast safety alignment as a continual learning (CL) problem that must balance plasticity (acquiring safety constraints) and stability (preserving general abilities). We propose Orthogonal Gradient Projection for Safety Alignment (OGPSA), a lightweight method that mitigates interference by constraining each safety update to be orthogonal (in a first-order sense) to a learned subspace capturing general capabilities. Specifically, OGPSA estimates a low-rank capability subspace from gradients on a small reference set and projects the safety gradient onto its orthogonal complement before updating. This produces safety-directed updates that minimally perturb prior knowledge while retaining capacity for alignment. OGPSA is plug-and-play and integrates into standard post-training pipelines without large-scale replay, auxiliary objectives, or retraining. Across Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and sequential SFT$\rightarrow$DPO settings, OGPSA consistently improves the safety--utility Pareto frontier over standard baselines. For instance, on Qwen2.5-7B-Instruct under SFT$\rightarrow$DPO, OGPSA preserves strong safety while recovering general capability, improving SimpleQA from 0.53\% to 3.03\% and IFEval from 51.94\% to 63.96\%. Our source code is available at \href{https://github.com/SunGL001/OGPSA}{OGPSA}