MARTI-MARS$^2$: Scaling Multi-Agent Self-Search via Reinforcement Learning for Code Generation
作者: Shijie Wang, Pengfei Li, Yikun Fu, Kaifeng Liu, Fangyuan Li, Yang Liu, Xiaowei Sun, Zonglin Li, Siyao Zhao, Jian Zhao, Kai Tian, Dong Li, Junqi Gao, Yutong Zhang, Yiqun Chen, Yuqiang Li, Zoe Li, Weinan Zhang, Peng Ye, Shuyue Hu, Lei Bai, Bowen Zhou, Kaiyan Zhang, Biqing Qi
分类: cs.LG
发布日期: 2026-02-08
💡 一句话要点
提出MARTI-MARS$^2$,通过强化学习扩展多智能体自搜索,提升代码生成能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 强化学习 代码生成 大型语言模型 自搜索 策略多样性 异构智能体 智能体协作
📋 核心要点
- 现有代码生成任务中,单智能体系统面临性能瓶颈,多智能体协作虽有潜力,但现有方法纠错能力和策略多样性受限。
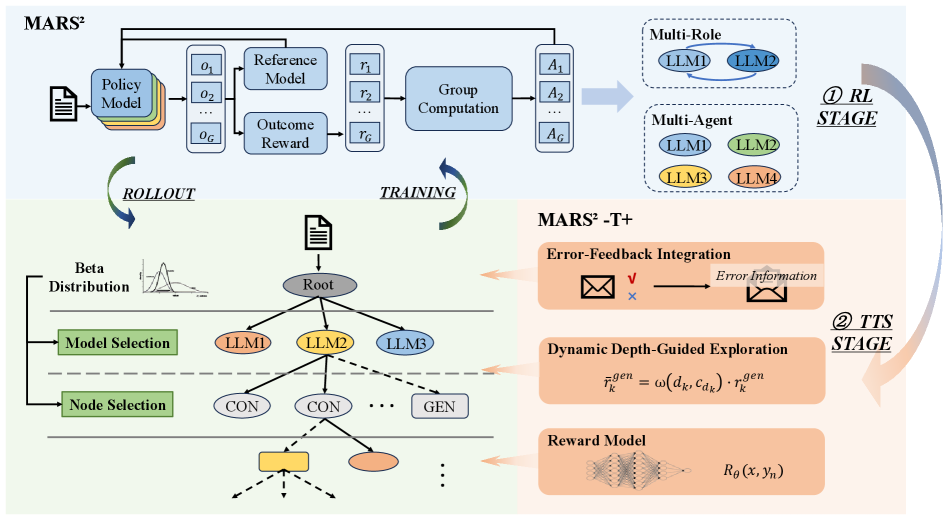
- MARTI-MARS$^2$框架将多智能体协作探索构建为动态可学习环境,通过强化学习和树搜索,实现从同构到异构智能体的演变。
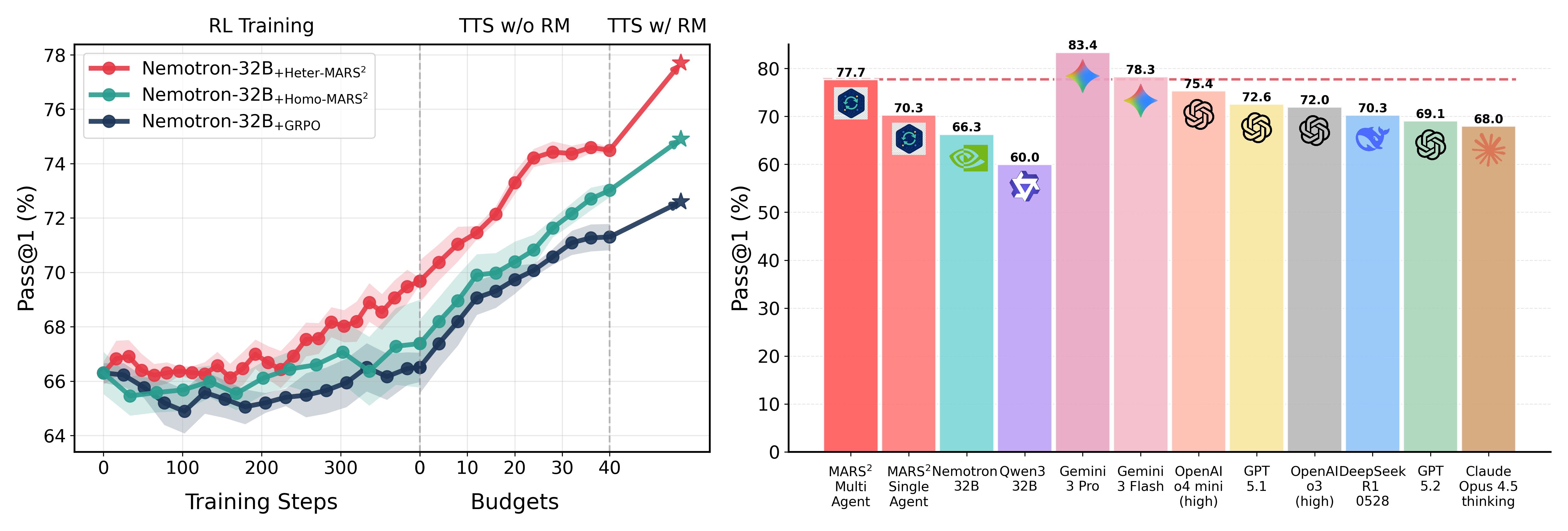
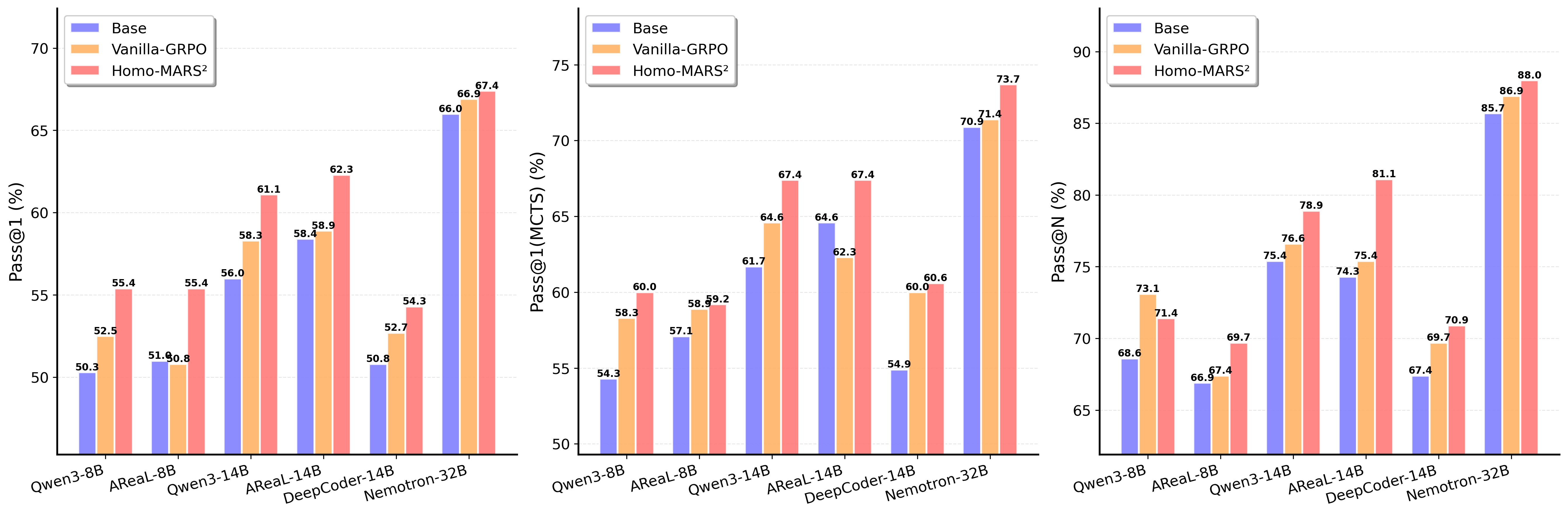
- 实验表明,MARTI-MARS$^2$在代码生成任务上超越了现有基线,并揭示了策略多样性对多智能体强化学习扩展智能的重要性。
📝 摘要(中文)
大型语言模型(LLMs)的复杂推理能力备受关注,但单智能体系统在代码生成等复杂任务中常遇到性能瓶颈。多智能体协作提供了一个超越这些限制的有希望的途径。然而,现有的框架通常依赖于基于提示的测试时交互或使用同构参数训练的多角色配置,限制了纠错能力和策略多样性。本文提出了一个多智能体强化训练和推理框架,通过自搜索扩展(MARTI-MARS$^2$),将多智能体协作探索过程构建为一个动态且可学习的环境,集成了策略学习与多智能体树搜索。通过允许智能体在环境中迭代探索和改进,该框架促进了从参数共享的同构多角色训练到异构多智能体训练的演变,突破了单智能体的能力限制。我们还引入了一种高效的推理策略MARTI-MARS$^2$-T+,以充分利用测试时多智能体协作的扩展潜力。我们在具有挑战性的代码生成基准上,针对不同的模型规模(8B、14B和32B)进行了广泛的实验。使用两个协作的32B模型,MARTI-MARS$^2$实现了77.7%的性能,优于GPT-5.1等强大的基线。此外,MARTI-MARS$^2$揭示了一种新的扩展规律:从单智能体到同构多角色,最终到异构多智能体范式的转变,逐步产生更高的RL性能上限、强大的TTS能力和更大的策略多样性,表明策略多样性对于通过多智能体强化学习扩展智能至关重要。
🔬 方法详解
问题定义:论文旨在解决复杂代码生成任务中,单智能体大型语言模型(LLM)的性能瓶颈问题。现有方法如prompt工程或同构多智能体系统,难以充分利用多智能体协作的优势,在纠错和策略探索方面存在局限性。
核心思路:论文的核心思路是将多智能体协作过程建模为一个动态可学习的环境,并利用强化学习(RL)训练智能体在该环境中进行迭代探索和改进。通过这种方式,可以实现从参数共享的同构多角色训练到异构多智能体训练的转变,从而突破单智能体的能力限制。
技术框架:MARTI-MARS$^2$框架包含以下主要模块:1) 多智能体环境建模:将代码生成任务建模为一个动态环境,智能体可以在其中执行动作(例如生成代码片段、评估代码质量等),并获得奖励。2) 强化学习训练:使用RL算法训练智能体,使其能够学习到最优的协作策略。3) 自搜索扩展:通过树搜索算法,智能体可以在环境中进行更深入的探索,从而找到更好的解决方案。4) 推理策略MARTI-MARS$^2$-T+:一种高效的推理策略,充分利用测试时多智能体协作的扩展潜力。
关键创新:最重要的技术创新点在于将多智能体协作过程建模为一个动态可学习的环境,并利用强化学习进行训练。这种方法允许智能体在环境中进行迭代探索和改进,从而突破了单智能体的能力限制。此外,论文还揭示了一种新的扩展规律,即从单智能体到同构多角色,最终到异构多智能体范式的转变,逐步产生更高的RL性能上限。
关键设计:论文的关键设计包括:1) 奖励函数的设计:奖励函数需要能够准确地评估代码的质量,并引导智能体朝着正确的方向进行探索。2) 智能体之间的通信机制:智能体需要能够有效地进行通信,以便共享信息和协调行动。3) 树搜索算法的选择:树搜索算法需要能够在合理的时间内找到较好的解决方案。4) 异构智能体的设计:不同智能体可以具有不同的角色和能力,以便更好地完成代码生成任务。
🖼️ 关键图片
📊 实验亮点
MARTI-MARS$^2$在代码生成基准测试中取得了显著成果。使用两个协作的32B模型,MARTI-MARS$^2$实现了77.7%的性能,超越了GPT-5.1等强大的基线模型。实验还揭示了从单智能体到异构多智能体范式的转变能够逐步提升RL性能上限,并带来更强的泛化能力和策略多样性。
🎯 应用场景
该研究成果可应用于各种需要复杂代码生成的场景,例如软件开发、自动化测试、AI编程助手等。通过多智能体协作,可以显著提高代码生成的效率和质量,降低开发成本,并加速软件创新。未来,该技术有望进一步扩展到其他复杂任务,例如机器人控制、自然语言处理等。
📄 摘要(原文)
While the complex reasoning capability of Large Language Models (LLMs) has attracted significant attention, single-agent systems often encounter inherent performance ceilings in complex tasks such as code generation. Multi-agent collaboration offers a promising avenue to transcend these boundaries. However, existing frameworks typically rely on prompt-based test-time interactions or multi-role configurations trained with homogeneous parameters, limiting error correction capabilities and strategic diversity. In this paper, we propose a Multi-Agent Reinforced Training and Inference Framework with Self-Search Scaling (MARTI-MARS2), which integrates policy learning with multi-agent tree search by formulating the multi-agent collaborative exploration process as a dynamic and learnable environment. By allowing agents to iteratively explore and refine within the environment, the framework facilitates evolution from parameter-sharing homogeneous multi-role training to heterogeneous multi-agent training, breaking through single-agent capability limits. We also introduce an efficient inference strategy MARTI-MARS2-T+ to fully exploit the scaling potential of multi-agent collaboration at test time. We conduct extensive experiments across varied model scales (8B, 14B, and 32B) on challenging code generation benchmarks. Utilizing two collaborating 32B models, MARTI-MARS2 achieves 77.7%, outperforming strong baselines like GPT-5.1. Furthermore, MARTI-MARS2 reveals a novel scaling law: shifting from single-agent to homogeneous multi-role and ultimately to heterogeneous multi-agent paradigms progressively yields higher RL performance ceilings, robust TTS capabilities, and greater policy diversity, suggesting that policy diversity is critical for scaling intelligence via multi-agent reinforcement learning.