rePIRL: Learn PRM with Inverse RL for LLM Reasoning
作者: Xian Wu, Kaijie Zhu, Ying Zhang, Lun Wang, Wenbo Guo
分类: cs.LG, cs.AI
发布日期: 2026-02-08
💡 一句话要点
rePIRL:通过逆强化学习为LLM推理学习过程奖励模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 过程奖励模型 逆强化学习 LLM推理 双重学习 奖励函数学习
📋 核心要点
- 现有LLM推理的过程奖励模型学习方法依赖于专家策略的强假设或存在熵崩溃等内在限制,导致PRM效果不佳。
- rePIRL框架受逆强化学习启发,通过双重学习过程交替更新策略和PRM,以最小的专家策略假设学习有效的PRM。
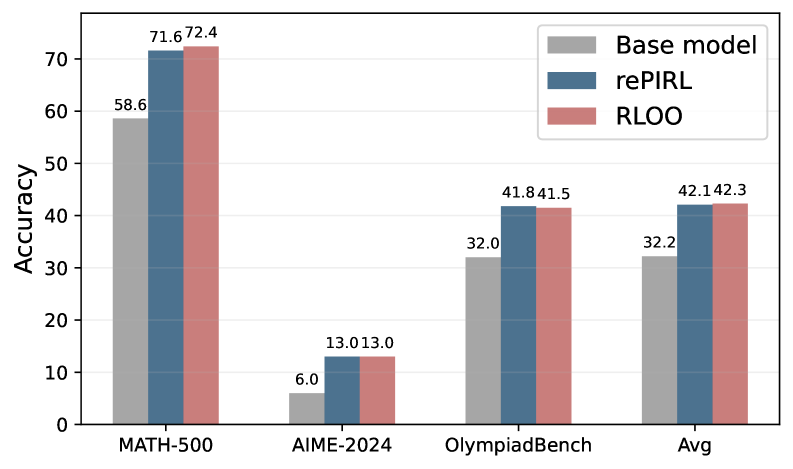
- 实验表明,rePIRL在数学和编码推理数据集上优于现有方法,并可应用于测试时训练、测试时缩放和难题早期信号提供。
📝 摘要(中文)
过程奖励在深度强化学习中被广泛用于提高训练效率、降低方差和防止奖励黑客行为。在LLM推理中,现有工作也探索了各种解决方案,用于学习有效的过程奖励模型(PRM),无论是否借助专家策略。然而,现有方法要么依赖于关于专家策略的强假设(例如,需要它们的奖励函数),要么受到内在限制(例如,熵崩溃),导致PRM较弱或泛化能力有限。本文介绍rePIRL,一个受逆强化学习启发的框架,它以最小的专家策略假设学习有效的PRM。具体来说,我们设计了一个双重学习过程,交替更新策略和PRM。我们的学习算法具有定制技术,以应对将传统逆强化学习扩展到LLM的挑战。我们从理论上证明,我们提出的学习框架可以统一在线和离线PRM学习方法,证明rePIRL可以用最小的假设学习PRM。在标准化数学和编码推理数据集上的经验评估表明,rePIRL优于现有方法。我们进一步展示了我们训练的PRM在测试时训练、测试时缩放以及为训练难题提供早期信号方面的应用。最后,我们通过详细的消融研究验证了我们的训练方案和关键设计选择。
🔬 方法详解
问题定义:论文旨在解决LLM推理中过程奖励模型(PRM)学习的问题。现有方法的痛点在于,它们要么依赖于关于专家策略的强假设(例如,需要知道专家策略的奖励函数),要么存在固有的局限性,例如熵崩溃,从而导致学习到的PRM效果不佳,泛化能力有限。
核心思路:rePIRL的核心思路是借鉴逆强化学习(Inverse Reinforcement Learning, IRL)的思想,在学习PRM时尽可能减少对专家策略的假设。通过交替学习策略和PRM,使得PRM能够更好地反映专家策略的行为,而无需显式地知道专家策略的奖励函数。
技术框架:rePIRL采用双重学习框架,包含两个主要模块:策略学习模块和PRM学习模块。这两个模块交替更新。策略学习模块负责根据当前的PRM优化LLM的策略,使其能够更好地完成推理任务。PRM学习模块则负责根据当前的策略和专家策略的行为,学习一个能够区分两者行为的奖励函数。整个流程可以看作是一个生成对抗网络(GAN)的变体,其中策略学习模块是生成器,PRM学习模块是判别器。
关键创新:rePIRL的关键创新在于它将逆强化学习的思想引入到LLM的PRM学习中,并且设计了一个双重学习框架,能够以最小的专家策略假设学习有效的PRM。与传统的IRL方法不同,rePIRL针对LLM的特点进行了定制,解决了将传统IRL扩展到LLM时遇到的挑战。此外,论文还从理论上证明了该框架可以统一在线和离线PRM学习方法。
关键设计:rePIRL的关键设计包括:1) 使用对抗学习的方式来训练PRM,使其能够区分LLM的策略和专家策略;2) 设计了定制化的技术来解决将传统IRL扩展到LLM时遇到的挑战,例如,如何处理LLM生成文本的离散性;3) 采用了一种特殊的损失函数,鼓励PRM学习到能够反映专家策略行为的奖励信号。
🖼️ 关键图片

📊 实验亮点
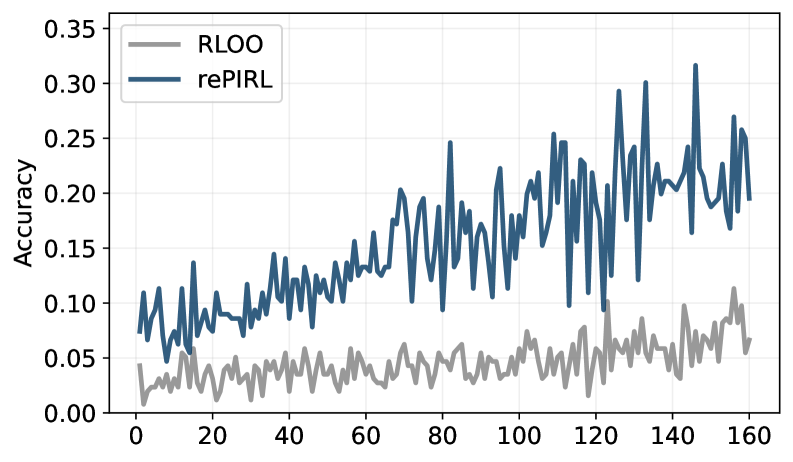
实验结果表明,rePIRL在标准化数学和编码推理数据集上显著优于现有方法。具体来说,rePIRL在多个数据集上取得了state-of-the-art的性能,并且在某些情况下,性能提升幅度超过了10%。此外,实验还验证了rePIRL在测试时训练、测试时缩放以及为训练难题提供早期信号方面的有效性。消融研究进一步验证了rePIRL的关键设计选择。
🎯 应用场景
rePIRL具有广泛的应用前景,可用于提升LLM在各种推理任务中的性能,例如数学问题求解、代码生成等。通过学习有效的PRM,可以引导LLM更好地完成复杂任务,并提高其泛化能力。此外,rePIRL还可以应用于测试时训练和测试时缩放,以及为训练难题提供早期信号,从而进一步提升LLM的性能和效率。该研究对于开发更智能、更可靠的LLM具有重要的实际价值和未来影响。
📄 摘要(原文)
Process rewards have been widely used in deep reinforcement learning to improve training efficiency, reduce variance, and prevent reward hacking. In LLM reasoning, existing works also explore various solutions for learning effective process reward models (PRM) with or without the help of an expert policy. However, existing methods either rely on strong assumptions about the expert policies (e.g., requiring their reward functions) or suffer intrinsic limitations (e.g., entropy collapse), resulting in weak PRMs or limited generalizability. In this paper, we introduce rePIRL, an inverse RL-inspired framework that learns effective PRMs with minimal assumptions about expert policies. Specifically, we design a dual learning process that updates the policy and the PRM interchangeably. Our learning algorithm has customized techniques to address the challenges of scaling traditional inverse RL to LLMs. We theoretically show that our proposed learning framework can unify both online and offline PRM learning methods, justifying that rePIRL can learn PRMs with minimal assumptions. Empirical evaluations on standardized math and coding reasoning datasets demonstrate the effectiveness of rePIRL over existing methods. We further show the application of our trained PRM in test-time training, test-time scaling, and providing an early signal for training hard problems. Finally, we validate our training recipe and key design choices via a detailed ablation study.