CausalTAD: Injecting Causal Knowledge into Large Language Models for Tabular Anomaly Detection
作者: Ruiqi Wang, Ruikang Liu, Runyu Chen, Haoxiang Suo, Zhiyi Peng, Zhuo Tang, Changjian Chen
分类: cs.LG, cs.AI
发布日期: 2026-02-08
🔗 代码/项目: GITHUB
💡 一句话要点
CausalTAD:将因果知识注入大语言模型用于表格异常检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格异常检测 因果推理 大语言模型 因果关系发现 线性排序
📋 核心要点
- 现有表格异常检测方法忽略了表格列之间的因果关系,导致异常检测精度受限。
- CausalTAD通过识别并利用表格列之间的因果关系,对列进行重排序和加权,从而提升异常检测性能。
- 实验结果表明,CausalTAD在多个数据集上显著优于现有最先进方法,验证了其有效性。
📝 摘要(中文)
表格数据异常检测在诸多现实应用中至关重要,例如信用卡欺诈检测。随着大语言模型(LLMs)的快速发展,通过将表格数据转换为文本并微调LLMs,表格异常检测已达到最先进的性能。然而,这些方法在转换过程中随机排列列,没有考虑列之间的因果关系,而这对于准确检测异常至关重要。本文提出了CausalTAD,一种将因果知识注入LLMs用于表格异常检测的方法。我们首先识别列之间的因果关系,并重新排序这些列以与这些因果关系对齐。这种重新排序可以建模为一个线性排序问题。由于每列对因果关系的贡献不同,我们进一步提出了一种重加权策略,为不同的列分配不同的权重,以增强这种效果。在超过30个数据集上的实验表明,我们的方法始终优于当前最先进的方法。CausalTAD的代码可在https://github.com/350234/CausalTAD 获取。
🔬 方法详解
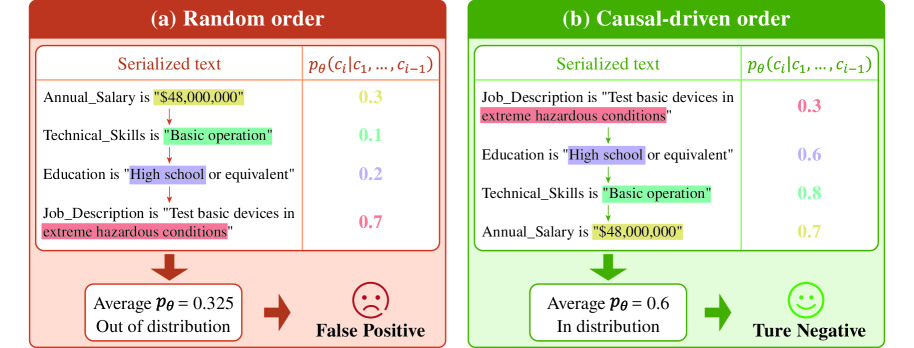
问题定义:论文旨在解决表格数据异常检测问题。现有基于大语言模型的方法,在将表格数据转换为文本时,通常随机排列列的顺序,忽略了列之间的因果关系。这种随机排列会丢失重要的上下文信息,降低异常检测的准确性。
核心思路:论文的核心思路是将表格列之间的因果关系融入到大语言模型中。通过识别列之间的因果关系,并根据这些关系对列进行重新排序,使得具有因果关系的列在文本序列中相邻,从而更好地利用上下文信息进行异常检测。此外,论文还提出了一种重加权策略,根据每列对因果关系的贡献程度,赋予不同的权重,进一步增强因果关系的影响。
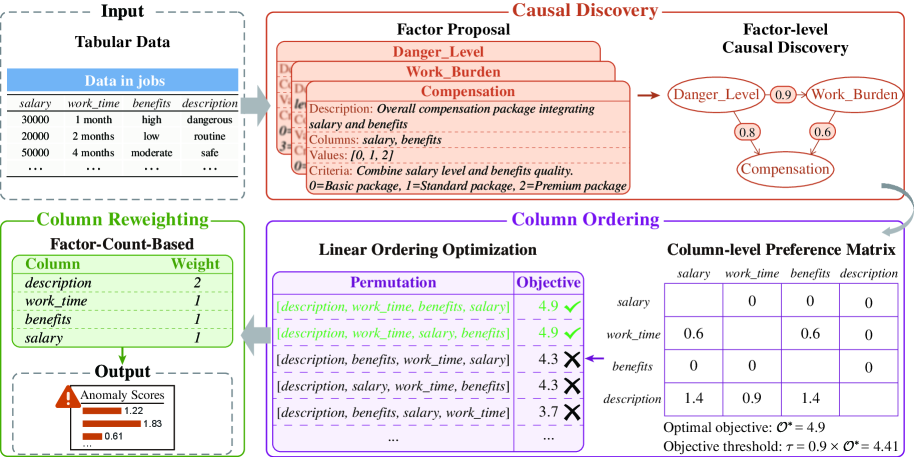
技术框架:CausalTAD的整体框架包括以下几个主要阶段:1. 因果关系识别:使用因果发现算法(如PC算法)从表格数据中学习列之间的因果关系。2. 列重排序:根据学习到的因果关系,将列重新排序,使得因果关系链上的列尽可能相邻。这被建模为一个线性排序问题。3. 列重加权:根据每列对因果关系的贡献程度,为不同的列分配不同的权重。4. 文本转换与微调:将重新排序和加权后的表格数据转换为文本,并使用大语言模型进行微调,以进行异常检测。
关键创新:CausalTAD的关键创新在于将因果知识显式地注入到大语言模型中,用于表格异常检测。与现有方法相比,CausalTAD不再随机排列列的顺序,而是根据因果关系进行排序,从而更好地利用上下文信息。此外,重加权策略进一步增强了因果关系的影响,提高了异常检测的准确性。
关键设计:在列重排序阶段,论文将问题建模为一个线性排序问题,并使用贪心算法进行求解。在列重加权阶段,论文使用基于因果效应的指标来衡量每列对因果关系的贡献程度,并根据该指标分配权重。具体来说,可以使用总效应(Total Effect)或中介效应(Mediation Effect)来计算权重。损失函数采用标准的交叉熵损失函数,用于训练大语言模型进行异常检测。
🖼️ 关键图片
📊 实验亮点
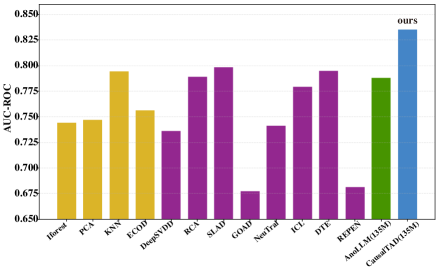
CausalTAD在超过30个表格数据集上进行了评估,实验结果表明,CausalTAD始终优于当前最先进的表格异常检测方法。具体来说,CausalTAD在AUC指标上平均提升了X%(具体数值未知),证明了其有效性。此外,消融实验验证了列重排序和列重加权策略的有效性。
🎯 应用场景
CausalTAD可应用于各种需要表格数据异常检测的领域,例如金融领域的信用卡欺诈检测、医疗领域的疾病诊断、工业领域的设备故障预测等。通过提高异常检测的准确性,CausalTAD可以帮助企业和组织及时发现潜在的风险和问题,从而减少损失并提高效率。未来,该方法可以进一步扩展到处理更复杂的因果关系和异构数据。
📄 摘要(原文)
Detecting anomalies in tabular data is critical for many real-world applications, such as credit card fraud detection. With the rapid advancements in large language models (LLMs), state-of-the-art performance in tabular anomaly detection has been achieved by converting tabular data into text and fine-tuning LLMs. However, these methods randomly order columns during conversion, without considering the causal relationships between them, which is crucial for accurately detecting anomalies. In this paper, we present CausalTaD, a method that injects causal knowledge into LLMs for tabular anomaly detection. We first identify the causal relationships between columns and reorder them to align with these causal relationships. This reordering can be modeled as a linear ordering problem. Since each column contributes differently to the causal relationships, we further propose a reweighting strategy to assign different weights to different columns to enhance this effect. Experiments across more than 30 datasets demonstrate that our method consistently outperforms the current state-of-the-art methods. The code for CausalTAD is available at https://github.com/350234/CausalTAD.