Preference Conditioned Multi-Objective Reinforcement Learning: Decomposed, Diversity-Driven Policy Optimization
作者: Tanmay Ambadkar, Sourav Panda, Shreyash Kale, Jonathan Dodge, Abhinav Verma
分类: cs.LG, cs.AI
发布日期: 2026-02-08
💡 一句话要点
D³PO:一种分解式、多样性驱动的偏好条件多目标强化学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标强化学习 偏好条件学习 帕累托前沿 策略优化 多样性正则化
📋 核心要点
- 现有偏好条件多目标强化学习方法难以恢复完整的帕累托前沿,存在梯度干扰和表征崩溃问题。
- D³PO通过分解优化管道和多样性正则化器,解决梯度干扰和表征崩溃问题,提升策略对偏好的敏感性。
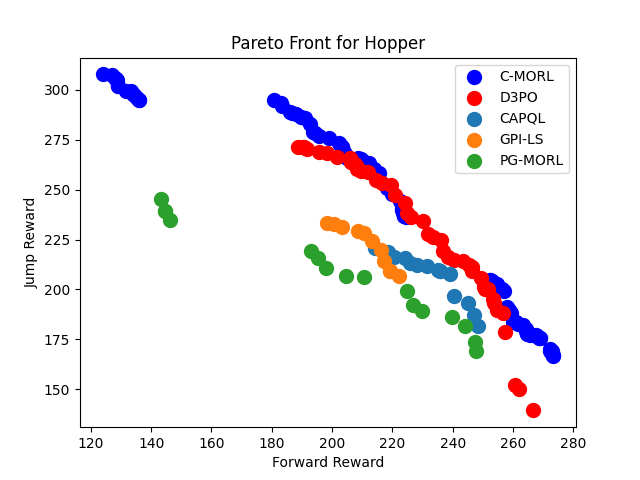
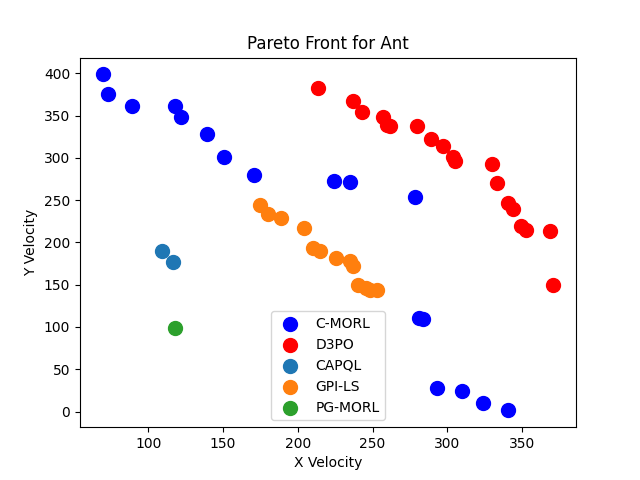
- 实验表明,D³PO在标准MORL基准测试中,能够发现更广泛和更高质量的帕累托前沿,性能优于现有方法。
📝 摘要(中文)
多目标强化学习(MORL)旨在学习平衡多个通常相互冲突的目标的策略。虽然单一的偏好条件策略是最灵活和可扩展的解决方案,但现有的方法在实践中仍然很脆弱,经常无法恢复完整的帕累托前沿。我们发现这种失败源于当前方法中的两个结构性问题:由过早标量化引起的破坏性梯度干扰和偏好空间中的表征崩溃。我们引入了D³PO,这是一个基于PPO的框架,它重新组织了多目标策略优化,以直接解决这些问题。D³PO通过分解的优化管道保留了每个目标的学习信号,并在稳定后整合偏好,从而实现可靠的信用分配。此外,缩放的多样性正则化器强制策略行为对偏好变化的敏感性,防止崩溃。在包括高维和多目标控制任务在内的标准MORL基准测试中,D³PO始终比以前的单策略和多策略方法发现更广泛和更高质量的帕累托前沿,在使用单一可部署策略的同时,匹配或超过了最先进的超体积和预期效用。
🔬 方法详解
问题定义:多目标强化学习旨在寻找一组策略,每个策略在多个目标之间取得不同的平衡。现有的偏好条件方法,即学习一个策略根据偏好调整行为,存在两个主要问题:一是过早的标量化导致梯度干扰,使得不同目标之间的学习信号相互抵消;二是偏好空间中的表征崩溃,导致策略对不同的偏好输入产生相似的行为。
核心思路:D³PO的核心思路是将多目标优化过程分解为两个阶段:首先,独立地学习每个目标的策略,避免梯度干扰;然后,通过多样性正则化器,鼓励策略对不同的偏好输入产生不同的行为,防止表征崩溃。通过这种分解和正则化,D³PO能够更有效地探索帕累托前沿。
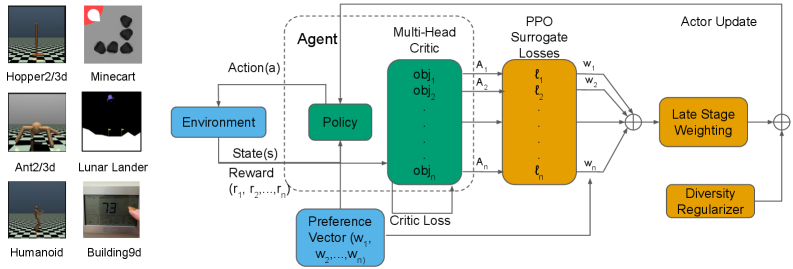
技术框架:D³PO基于PPO算法,其整体框架包含以下几个主要模块:1) 多个独立的PPO Actor-Critic网络,每个网络负责优化一个目标;2) 一个偏好编码器,将偏好向量映射到策略网络的输入;3) 一个多样性正则化器,用于鼓励策略对不同的偏好输入产生不同的行为。在训练过程中,首先独立地训练每个目标的Actor-Critic网络,然后使用偏好编码器和多样性正则化器对策略进行微调。
关键创新:D³PO的关键创新在于两个方面:一是分解的优化管道,通过独立地学习每个目标的策略,避免了梯度干扰;二是多样性正则化器,通过鼓励策略对不同的偏好输入产生不同的行为,防止了表征崩溃。这两个创新使得D³PO能够更有效地探索帕累托前沿,并学习到更高质量的偏好条件策略。
关键设计:D³PO的关键设计包括:1) 使用独立的PPO Actor-Critic网络来优化每个目标;2) 使用一个多层感知机作为偏好编码器,将偏好向量映射到策略网络的输入;3) 使用缩放的KL散度作为多样性正则化器,鼓励策略对不同的偏好输入产生不同的行为。正则化系数的选择对性能有重要影响,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
D³PO在多个标准MORL基准测试中取得了显著的性能提升。例如,在High-Dimensional Control Tasks和Many-Objective Control Tasks中,D³PO始终比以前的单策略和多策略方法发现更广泛和更高质量的帕累托前沿,匹配或超过了最先进的超体积和预期效用,同时仅使用单一可部署策略。
🎯 应用场景
D³PO可应用于各种需要权衡多个目标的决策问题,例如机器人控制、资源分配、推荐系统等。在机器人控制中,可以同时优化机器人的速度、能耗和稳定性。在资源分配中,可以同时优化公平性、效率和利用率。在推荐系统中,可以同时优化用户的满意度、平台的收入和内容的 diversity。该研究有助于开发更智能、更灵活的决策系统,更好地满足用户的需求。
📄 摘要(原文)
Multi-objective reinforcement learning (MORL) seeks to learn policies that balance multiple, often conflicting objectives. Although a single preference-conditioned policy is the most flexible and scalable solution, existing approaches remain brittle in practice, frequently failing to recover complete Pareto fronts. We show that this failure stems from two structural issues in current methods: destructive gradient interference caused by premature scalarization and representational collapse across the preference space. We introduce $D^3PO$, a PPO-based framework that reorganizes multi-objective policy optimization to address these issues directly. $D^3PO$ preserves per-objective learning signals through a decomposed optimization pipeline and integrates preferences only after stabilization, enabling reliable credit assignment. In addition, a scaled diversity regularizer enforces sensitivity of policy behavior to preference changes, preventing collapse. Across standard MORL benchmarks, including high-dimensional and many-objective control tasks, $D^3PO$ consistently discovers broader and higher-quality Pareto fronts than prior single- and multi-policy methods, matching or exceeding state-of-the-art hypervolume and expected utility while using a single deployable policy.