Do We Need Adam? Surprisingly Strong and Sparse Reinforcement Learning with SGD in LLMs
作者: Sagnik Mukherjee, Lifan Yuan, Pavan Jayasinha, Dilek Hakkani-Tür, Hao Peng
分类: cs.LG, cs.AI
发布日期: 2026-02-07
💡 一句话要点
在LLM的RL训练中,SGD表现优于AdamW,并实现极高的参数稀疏性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 SGD优化器 参数稀疏性 内存效率 RLVR AdamW优化器 模型微调
📋 核心要点
- 现有RL训练LLM的方法通常沿用预训练和SFT阶段的AdamW优化器,但忽略了RL与这些阶段的本质区别。
- 该论文提出在LLM的RL训练中使用SGD优化器,并发现其性能与AdamW相当甚至更好,且内存效率更高。
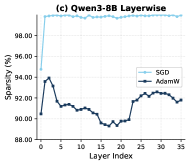
- 实验表明,使用SGD进行全量微调时,仅更新极少比例的模型参数,实现了显著的参数稀疏性。
📝 摘要(中文)
强化学习(RL),特别是基于可验证奖励的强化学习(RLVR),已成为训练大型语言模型(LLMs)的关键阶段,也是当前扩展工作的重点。然而,RL中的优化实践在很大程度上遵循了next-token预测阶段(例如,预训练和监督微调)的优化方法,尽管最近的研究强调了RL与这些阶段之间的根本差异。其中一种实践是使用AdamW优化器,尽管它具有很高的内存开销,但已被广泛用于训练大规模Transformer模型。我们的分析表明,AdamW中的动量和自适应学习率在RL中的影响不如在SFT中那么大,这使我们假设RL从Adam风格的逐参数自适应学习率和动量中获益较少。实验证实了这一假设,表明内存效率更高的SGD在LLM的RL中与AdamW相匹配甚至优于AdamW,而SGD在大型Transformer的监督学习中表现不佳。值得注意的是,使用SGD进行全量微调仅更新不到0.02%的模型参数,而无需任何促进稀疏性的正则化,比AdamW少1000多倍。我们的分析为这种更新稀疏性提供了潜在的原因。这些发现为LLM中RL的优化动态提供了新的见解,并表明RL可能比以前认为的更具有参数效率。
🔬 方法详解
问题定义:现有方法在对LLM进行RL训练时,通常直接采用在预训练和监督微调阶段表现良好的AdamW优化器。然而,RL阶段的目标函数和数据分布与预训练和监督微调阶段存在显著差异,直接套用AdamW可能并非最优,且AdamW具有较高的内存开销。
核心思路:论文的核心思路是重新审视在LLM的RL训练中使用AdamW的必要性,并探索更简单、内存效率更高的SGD优化器是否能够取得更好的效果。作者认为,AdamW中的动量和自适应学习率在RL中的作用可能不如在监督学习中那么重要,因此SGD可能更适合RL任务。
技术框架:论文主要通过实验对比AdamW和SGD在LLM的RL训练中的性能。具体来说,作者在RLVR框架下,使用不同的LLM模型和数据集,分别使用AdamW和SGD进行训练,并评估模型的性能指标。同时,作者还分析了两种优化器在训练过程中更新的参数数量,以评估参数稀疏性。
关键创新:该论文最重要的技术创新点在于发现SGD在LLM的RL训练中可以与AdamW相媲美甚至超越AdamW,并且能够实现极高的参数稀疏性。这一发现挑战了长期以来在LLM训练中使用AdamW的传统观念,并为RL训练LLM提供了一种更高效、更节省内存的替代方案。
关键设计:论文的关键设计在于实验设置,作者精心选择了不同的LLM模型和数据集,并对AdamW和SGD的超参数进行了调整,以确保实验结果的可靠性和可比性。此外,作者还设计了一种方法来衡量训练过程中更新的参数数量,从而评估参数稀疏性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在LLM的RL训练中,SGD的性能与AdamW相当甚至更好。更重要的是,使用SGD进行全量微调时,仅更新不到0.02%的模型参数,而无需任何促进稀疏性的正则化,比AdamW少1000多倍。这表明RL训练可以实现极高的参数稀疏性,从而显著降低模型大小和计算成本。
🎯 应用场景
该研究成果可应用于各种需要使用强化学习训练大型语言模型的场景,例如对话系统、文本生成、代码生成等。使用SGD代替AdamW可以显著降低训练过程中的内存消耗,使得在资源受限的设备上训练大型语言模型成为可能。此外,参数稀疏性的提高也有助于模型压缩和推理加速。
📄 摘要(原文)
Reinforcement learning (RL), particularly RL from verifiable reward (RLVR), has become a crucial phase of training large language models (LLMs) and a key focus of current scaling efforts. However, optimization practices in RL largely follow those of next-token prediction stages (e.g., pretraining and supervised fine-tuning), despite fundamental differences between RL and these stages highlighted by recent work. One such practice is the use of the AdamW optimizer, which is widely adopted for training large-scale transformers despite its high memory overhead. Our analysis shows that both momentum and adaptive learning rates in AdamW are less influential in RL than in SFT, leading us to hypothesize that RL benefits less from Adam-style per-parameter adaptive learning rates and momentum. Confirming this hypothesis, our experiments demonstrate that the substantially more memory-efficient SGD, which is known to perform poorly in supervised learning of large-scale transformers, matches or even outperforms AdamW in RL for LLMs. Remarkably, full fine-tuning with SGD updates fewer than 0.02% of model parameters without any sparsity-promoting regularization, more than 1000 times fewer than AdamW. Our analysis offers potential reasons for this update sparsity. These findings provide new insights into the optimization dynamics of RL in LLMs and show that RL can be substantially more parameter-efficient than previously recognized.