Efficient Planning in Reinforcement Learning via Model Introspection
作者: Gabriel Stella
分类: cs.LG
发布日期: 2026-02-07
💡 一句话要点
提出基于模型内省的强化学习高效规划方法,连接RL与经典规划
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模型内省 程序分析 关系强化学习 经典规划
📋 核心要点
- 传统强化学习与经典规划是独立问题,缺乏人类的内省能力,难以有效利用任务信息。
- 该论文提出将内省视为程序分析,通过分析强化学习模型来提取任务相关信息,提升规划效率。
- 论文设计了一种算法,应用于关系强化学习模型,实现了高效的面向目标的规划,连接了强化学习与经典规划。
📝 摘要(中文)
强化学习和经典规划通常被认为是两个不同的问题,它们具有不同的公式,因此需要不同的解决方案。然而,当人类被赋予一项任务时,无论任务是如何指定的,他们通常可以推导出解决问题所需的额外信息。这种能力的关键在于内省:通过推理他们内部的问题模型,人类可以直接合成额外的任务相关信息。本文提出,这种内省可以被认为是程序分析。我们讨论了如何将这种方法应用于强化学习中使用的各种模型。然后,我们描述了一种算法,该算法能够对关系强化学习中使用的一类模型进行高效的面向目标的规划,从而展示了强化学习和经典规划之间的新颖联系。
🔬 方法详解
问题定义:论文旨在解决强化学习中规划效率低下的问题。现有方法通常将强化学习和经典规划视为独立的领域,导致在解决复杂任务时,无法有效利用任务本身的结构化信息。人类在解决问题时,能够通过内省来理解任务,并提取关键信息,从而进行高效的规划。现有强化学习方法缺乏这种内省能力,导致学习和规划效率较低。
核心思路:论文的核心思路是将人类的内省能力引入强化学习,具体而言,将内省过程视为程序分析。通过分析强化学习模型(例如,状态转移函数、奖励函数),可以提取出任务相关的结构化信息,例如状态之间的关系、动作的影响等。这些信息可以用于指导规划过程,从而提高规划效率。
技术框架:该论文提出的方法主要包含以下几个阶段:1. 模型表示:选择合适的模型来表示强化学习环境,例如关系强化学习模型。2. 模型内省:对模型进行程序分析,提取任务相关的结构化信息。这可能涉及到静态分析、动态分析等技术。3. 规划:利用提取的结构化信息,进行高效的规划。这可以采用经典规划算法,例如A*搜索、STRIPS规划等。
关键创新:该论文最重要的技术创新点在于将程序分析的思想引入强化学习,并将其应用于模型内省。通过模型内省,可以提取出任务相关的结构化信息,从而指导规划过程。这种方法能够有效地连接强化学习和经典规划,并提高规划效率。与现有方法的本质区别在于,现有方法通常将强化学习和经典规划视为独立的领域,而该论文则试图将两者结合起来。
关键设计:论文针对关系强化学习模型,设计了一种具体的模型内省算法。该算法利用关系模型的结构化特性,提取状态之间的关系、动作的影响等信息。具体的参数设置、损失函数、网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

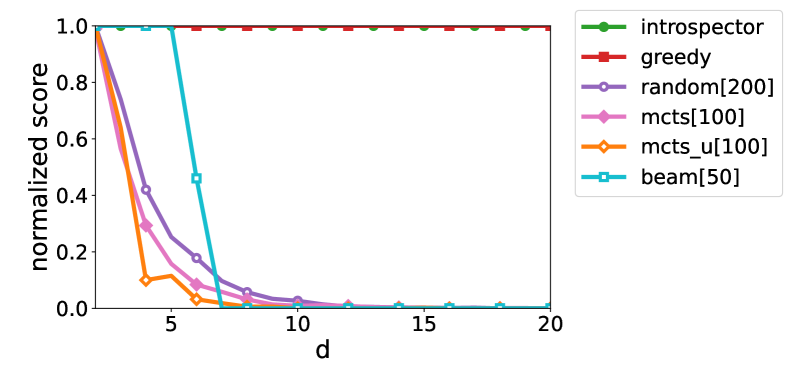
📊 实验亮点
论文提出了一种基于模型内省的强化学习规划方法,并在关系强化学习模型上进行了验证。具体的性能数据、对比基线、提升幅度等实验结果在摘要中未提及,属于未知信息。但该方法为强化学习和经典规划的结合提供了一种新的思路。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、任务调度等领域。通过模型内省,智能体可以更好地理解环境,从而进行更高效的规划和决策。该方法有望提升复杂任务中强化学习的应用效果,并促进通用人工智能的发展。
📄 摘要(原文)
Reinforcement learning and classical planning are typically seen as two distinct problems, with differing formulations necessitating different solutions. Yet, when humans are given a task, regardless of the way it is specified, they can often derive the additional information needed to solve the problem efficiently. The key to this ability is introspection: by reasoning about their internal models of the problem, humans directly synthesize additional task-relevant information. In this paper, we propose that this introspection can be thought of as program analysis. We discuss examples of how this approach can be applied to various kinds of models used in reinforcement learning. We then describe an algorithm that enables efficient goal-oriented planning over the class of models used in relational reinforcement learning, demonstrating a novel link between reinforcement learning and classical planning.