Towards Robust Scaling Laws for Optimizers
作者: Alexandra Volkova, Mher Safaryan, Christoph H. Lampert, Dan Alistarh
分类: cs.LG
发布日期: 2026-02-07
💡 一句话要点
提出优化器鲁棒缩放律,实现不同优化器在LLM预训练中的公平比较。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 缩放律 优化器 大型语言模型 预训练 泛化误差
📋 核心要点
- 现有研究在LLM预训练缩放律分析中,通常固定使用AdamW等优化器,忽略了优化器选择对模型性能的影响。
- 论文提出一种更鲁棒的缩放律,该缩放律具有共享的幂律指数和特定于优化器的重新缩放因子,从而实现优化器之间的直接比较。
- 通过理论分析和实验验证,表明Chinchilla风格的缩放律是损失分解为不可约误差、近似误差和优化误差的自然结果。
📝 摘要(中文)
大型语言模型(LLM)的预训练质量取决于多个因素,包括计算预算和优化算法的选择。经验缩放律被广泛用于预测模型大小和训练数据增长时的损失,然而,几乎所有现有研究都固定了优化器(通常是AdamW)。同时,新一代优化器(例如,Muon、Shampoo、SOAP)有望实现更快、更稳定的收敛,但它们与模型和数据缩放的关系尚不清楚。在这项工作中,我们研究了不同优化器之间的缩放律。经验表明,1) 每个优化器的单独Chinchilla风格缩放律是病态的,并且具有高度相关的参数。相反,2) 我们提出了一种更鲁棒的定律,具有共享的幂律指数和特定于优化器的重新缩放因子,从而可以直接比较优化器。最后,3) 我们对凸二次目标代理任务的梯度方法进行了理论分析,表明Chinchilla风格的缩放律自然地源于损失分解为不可约误差、近似误差和优化误差。
🔬 方法详解
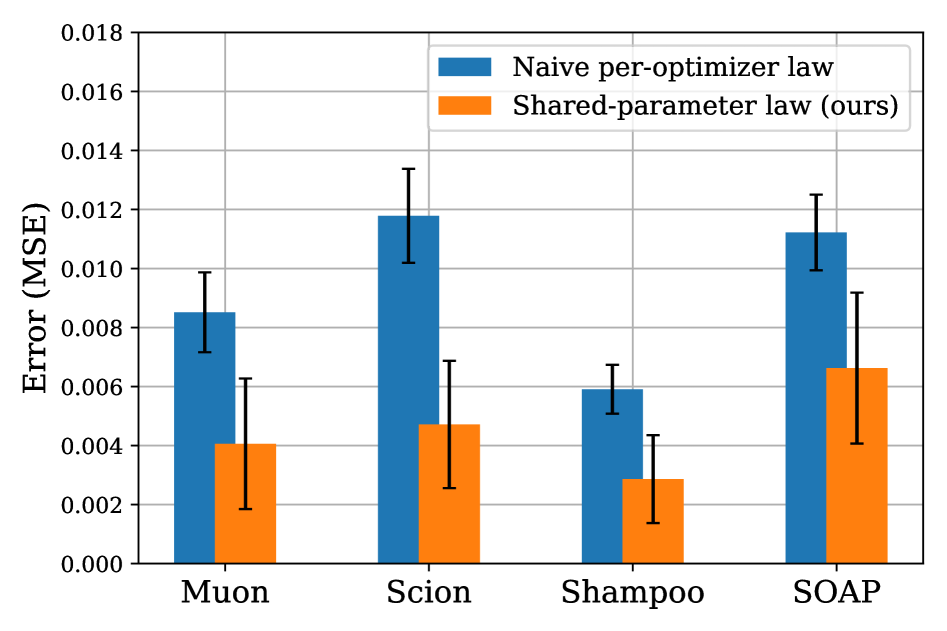
问题定义:现有的大型语言模型(LLM)预训练研究主要集中在使用固定的优化器(如AdamW)的情况下,模型大小和训练数据量对性能的影响,即缩放律。然而,不同的优化器(如Muon、Shampoo、SOAP)具有不同的收敛速度和稳定性,直接影响预训练的效率和最终性能。因此,如何建立一个能够公平比较不同优化器的缩放律是一个关键问题。现有方法为每个优化器单独建立缩放律,导致参数高度相关且不稳定。
核心思路:论文的核心思路是将缩放律中的幂律指数部分进行共享,而只保留特定于优化器的重新缩放因子。这样做的原因是,模型大小和数据量对损失的影响(由幂律指数决定)应该是与优化器无关的,而不同优化器的收敛速度和稳定性则体现在重新缩放因子上。通过这种方式,可以更稳定、更公平地比较不同优化器的性能。
技术框架:该研究的技术框架主要包括以下几个部分:1) 经验性地分析不同优化器在LLM预训练中的性能表现。2) 提出共享幂律指数的缩放律模型。3) 使用实验数据拟合该模型,得到优化器特定的重新缩放因子。4) 对凸二次目标代理任务进行理论分析,验证Chinchilla风格缩放律的合理性。
关键创新:该论文的关键创新在于提出了共享幂律指数的缩放律模型。与为每个优化器单独建立缩放律的方法相比,该方法更加稳定,并且能够直接比较不同优化器的性能。此外,通过理论分析,论文还解释了Chinchilla风格缩放律的内在机理。
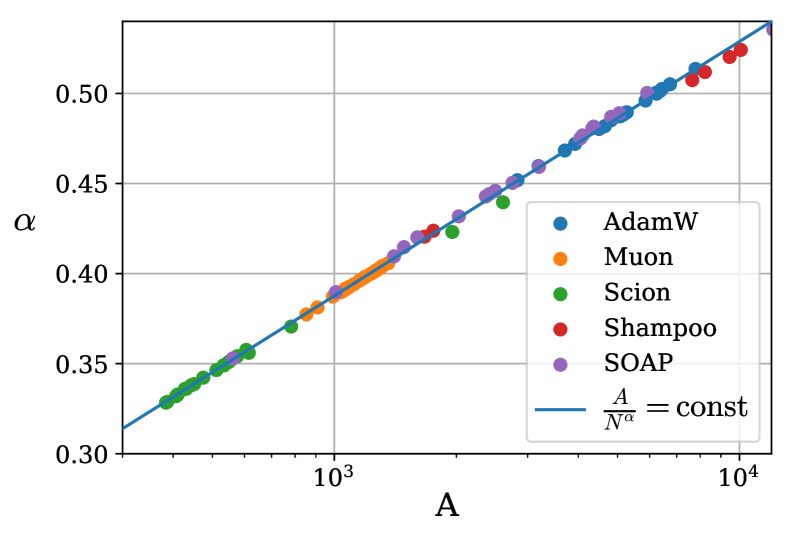
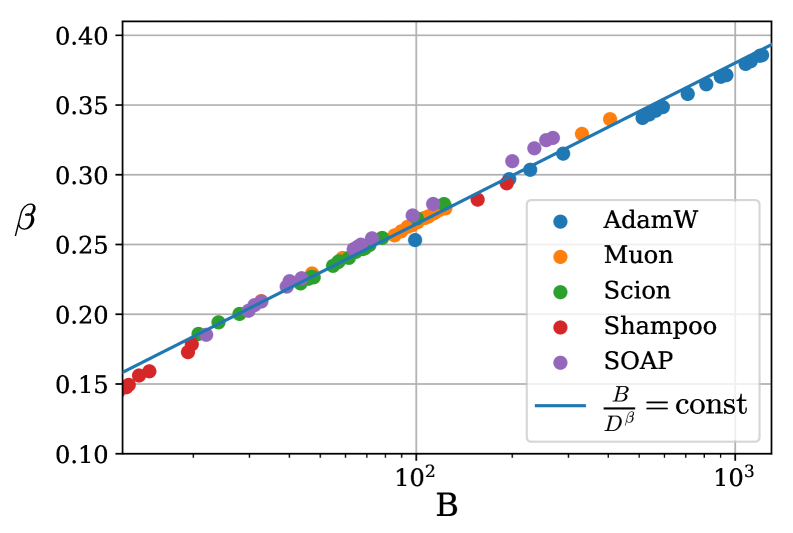
关键设计:论文的关键设计包括:1) 共享幂律指数的缩放律模型,其形式为:Loss = A * N^(-alpha) + B * D^(-beta) + C_optimizer,其中A、B、alpha、beta是所有优化器共享的参数,而C_optimizer是特定于优化器的重新缩放因子。2) 使用凸二次目标代理任务进行理论分析,简化了分析的复杂度,同时保留了梯度下降方法的核心特征。
🖼️ 关键图片
📊 实验亮点
实验结果表明,为每个优化器单独建立Chinchilla风格缩放律是病态的,参数高度相关。而论文提出的共享幂律指数的缩放律模型更加稳定,能够直接比较不同优化器的性能。理论分析也验证了Chinchilla风格缩放律的合理性。
🎯 应用场景
该研究成果可应用于大型语言模型的预训练阶段,帮助研究人员和工程师选择更合适的优化器,提高训练效率,降低计算成本。此外,该研究提出的鲁棒缩放律模型可以推广到其他机器学习任务中,为优化器的选择提供理论指导。
📄 摘要(原文)
The quality of Large Language Model (LLM) pretraining depends on multiple factors, including the compute budget and the choice of optimization algorithm. Empirical scaling laws are widely used to predict loss as model size and training data grow, however, almost all existing studies fix the optimizer (typically AdamW). At the same time, a new generation of optimizers (e.g., Muon, Shampoo, SOAP) promises faster and more stable convergence, but their relationship with model and data scaling is not yet well understood. In this work, we study scaling laws across different optimizers. Empirically, we show that 1) separate Chinchilla-style scaling laws for each optimizer are ill-conditioned and have highly correlated parameters. Instead, 2) we propose a more robust law with shared power-law exponents and optimizer-specific rescaling factors, which enable direct comparison between optimizers. Finally, 3) we provide a theoretical analysis of gradient-based methods for the proxy task of a convex quadratic objective, demonstrating that Chinchilla-style scaling laws emerge naturally as a result of loss decomposition into irreducible, approximation, and optimization errors.