Astro: Activation-guided Structured Regularization for Outlier-Robust LLM Post-Training Quantization
作者: Xi Chen, Ming Li, Junxi Li, Changsheng Li, Peisong Wang, Lizhong Ding, Ye Yuan, Guoren Wang
分类: cs.LG, cs.AI
发布日期: 2026-02-07
💡 一句话要点
提出Astro框架以解决LLM后训练量化中的异常值问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 异常值抑制 激活引导 结构化正则化 大型语言模型 高效部署 模型鲁棒性
📋 核心要点
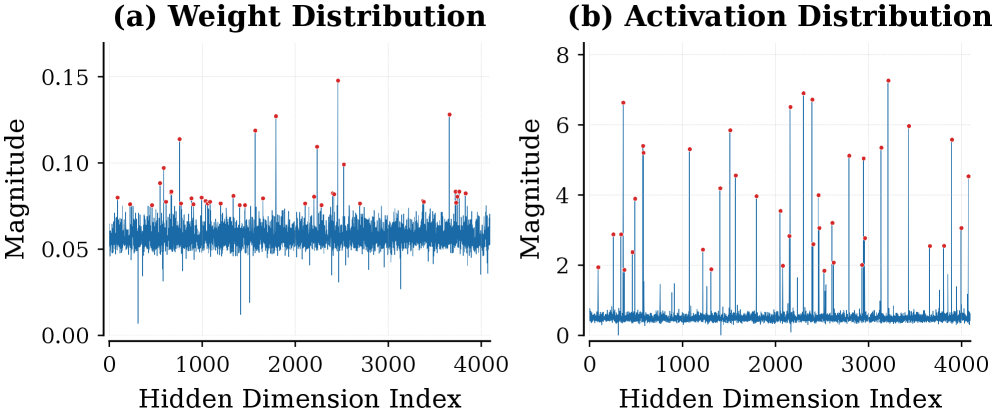
- 现有的后训练量化方法在处理权重和激活异常值时,往往面临准确性下降和部署效率低下的挑战。
- 本文提出的Astro框架通过激活引导的结构化正则化,有效抑制异常值的影响,同时保持模型的准确性。
- 实验结果显示,Astro在LLaMA-2-7B模型上表现优于复杂的学习基于旋转的方法,且量化时间减少近三分之一。
📝 摘要(中文)
权重导向的后训练量化(PTQ)对高效部署大型语言模型(LLM)至关重要,但由于权重和激活异常值,准确性会下降。现有的缓解策略存在不足,通常无法有效抑制异常值,或导致显著的部署效率低下。为了解决这些问题,本文提出了Astro,一个激活引导的结构化正则化框架,旨在以硬件友好和高效的方式抑制异常值的负面影响。Astro通过激活引导的正则化目标,主动重构内在鲁棒的权重,强力抑制与高幅度激活相对应的权重异常值,同时不牺牲模型的准确性。实验表明,Astro在LLaMA-2-7B上表现优异,量化时间几乎只有复杂学习方法的三分之一。
🔬 方法详解
问题定义:本文旨在解决后训练量化中由于权重和激活异常值导致的准确性下降问题。现有方法往往无法有效抑制这些异常值,或导致显著的推理延迟和复杂的预处理。
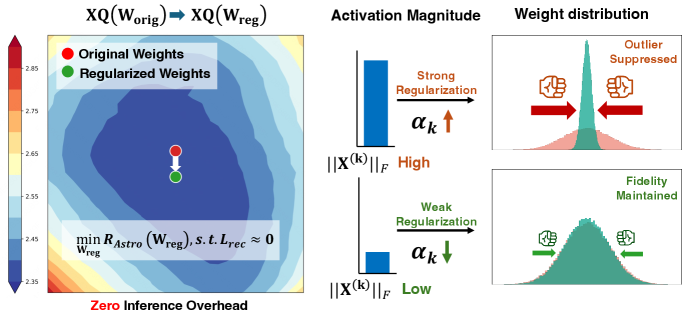
核心思路:Astro框架的核心思路是利用激活引导的结构化正则化,重构内在鲁棒的权重,从而抑制与高幅度激活相关的权重异常值,而不影响模型的整体性能。
技术框架:Astro的整体架构包括激活引导的正则化模块和权重重构模块。激活引导模块负责识别高幅度激活对应的权重异常值,而重构模块则通过优化算法调整权重以提高鲁棒性。
关键创新:Astro的主要创新在于其激活引导的正则化目标,这一设计使得模型能够在不增加推理延迟的情况下,有效抑制异常值的影响,与传统的量化方法相比,具有更高的效率和准确性。
关键设计:在关键设计方面,Astro采用了特定的损失函数来引导权重的重构过程,并通过调节正则化强度来平衡鲁棒性与准确性之间的关系。
🖼️ 关键图片

📊 实验亮点
在实验中,Astro在LLaMA-2-7B模型上表现出色,超越了复杂的学习基于旋转的方法,且量化时间几乎减少到三分之一,显示出其在效率和性能上的显著优势。
🎯 应用场景
Astro框架在大型语言模型的后训练量化中具有广泛的应用潜力,尤其适用于需要高效部署和实时推理的场景,如智能助手、自动翻译和内容生成等。其高效的异常值抑制能力将推动LLM在实际应用中的普及与发展。
📄 摘要(原文)
Weight-only post-training quantization (PTQ) is crucial for efficient Large Language Model (LLM) deployment but suffers from accuracy degradation caused by weight and activation outliers. Existing mitigation strategies often face critical limitations: they either yield insufficient outlier suppression or incur significant deployment inefficiencies, such as inference latency, heavy preprocessing, or reliance on complex operator fusion. To resolve these limitations, we leverage a key insight: over-parameterized LLMs often converge to Flat Minima, implying a vast equivalent solution space where weights can be adjusted without compromising accuracy. Building on this, we propose Astro, an Activation-guided Structured Regularization framework designed to suppress the negative effects of outliers in a hardware-friendly and efficient manner. Leveraging the activation-guided regularization objective, Astro actively reconstructs intrinsically robust weights, aggressively suppressing weight outliers corresponding to high-magnitude activations without sacrificing model accuracy. Crucially, Astro introduces zero inference latency and is orthogonal to mainstream quantization methods like GPTQ. Extensive experiments show that Astro achieves highly competitive performance; notably, on LLaMA-2-7B, it achieves better performance than complex learning-based rotation methods with almost 1/3 of the quantization time.