Gaussian Match-and-Copy: A Minimalist Benchmark for Studying Transformer Induction
作者: Antoine Gonon, Alexandre Cordonnier, Nicolas Boumal
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-02-07
💡 一句话要点
提出高斯匹配复制基准测试,用于研究Transformer的归纳能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 匹配复制 长程检索 基准测试 高斯分布
📋 核心要点
- 大型语言模型中的匹配复制行为难以理解,因为检索和记忆相互纠缠。
- 提出高斯匹配复制(GMC)基准,通过二阶相关信号隔离长程检索,解耦检索和记忆。
- 数值实验表明GMC保留了Transformer匹配复制电路的关键特性,并能区分不同架构的检索能力。
📝 摘要(中文)
匹配复制是大型语言模型在推理时使用的一种核心检索原语,用于从上下文中检索匹配的token,然后复制其后继token。然而,理解这种行为如何在自然数据上出现具有挑战性,因为检索和记忆是纠缠在一起的。为了解开这两者,我们引入了高斯匹配复制(GMC),这是一个极简的基准测试,通过纯粹的二阶相关信号来隔离长程检索。数值研究表明,该任务保留了Transformer在实践中开发匹配复制电路的关键定性方面,并通过其检索能力区分了不同的架构。我们还在简化的注意力设置中分析了优化动态。尽管在回归目标下,先验地存在许多可能的解决方案,包括那些不实现检索的解决方案,但我们识别出一种隐式偏差机制,其中梯度下降驱动参数发散,同时其方向与最大间隔分离器对齐,从而产生硬匹配选择。我们证明了在显式技术条件下,达到消失经验损失的GD轨迹的这种最大间隔对齐。
🔬 方法详解
问题定义:现有大型语言模型在进行匹配复制时,检索和记忆过程相互纠缠,难以单独分析检索机制的原理和优化过程。因此,需要一个更简洁、可控的基准测试来研究Transformer的检索能力,特别是长程检索能力。
核心思路:论文的核心思路是设计一个极简的基准测试,即高斯匹配复制(GMC),该基准通过高斯分布生成的数据,利用二阶相关信号来模拟长程检索过程。通过控制高斯分布的参数,可以精确控制匹配的难度和检索的距离,从而隔离检索过程,避免与记忆过程混淆。
技术框架:GMC基准测试包含以下几个关键部分:1) 数据生成:使用高斯分布生成token序列,其中匹配的token具有特定的相关性。2) 模型训练:使用Transformer模型进行训练,目标是预测匹配token的后继token。3) 性能评估:评估模型在GMC任务上的准确率,并分析模型的注意力机制如何实现匹配和复制。此外,论文还简化了注意力机制,以便更好地分析优化动态。
关键创新:GMC基准测试的关键创新在于其极简性和可控性。通过使用高斯分布和二阶相关信号,GMC能够有效地隔离长程检索过程,避免了与记忆过程的混淆。这使得研究人员可以更清晰地理解Transformer的检索机制,并分析其优化过程。此外,论文还发现了梯度下降的隐式偏差,即参数在训练过程中会趋向于最大间隔分离器。
关键设计:GMC的关键设计包括:1) 高斯分布的参数设置,用于控制匹配的难度和检索的距离。2) 损失函数的设计,通常使用交叉熵损失。3) 注意力机制的简化,以便更好地分析优化动态。4) 实验设置,包括不同的Transformer架构和训练参数。
🖼️ 关键图片
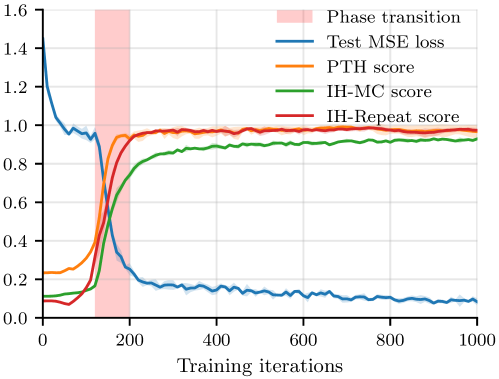

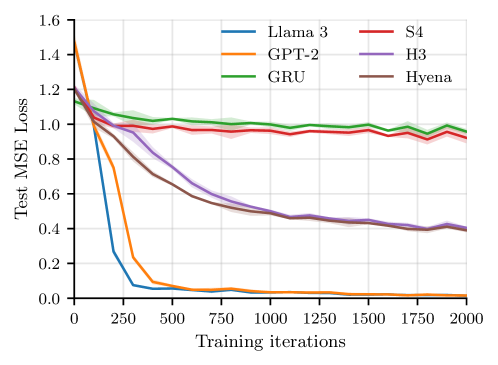
📊 实验亮点
论文通过数值实验验证了GMC基准测试的有效性,表明该任务保留了Transformer匹配复制电路的关键特性,并能区分不同架构的检索能力。此外,论文还发现了梯度下降的隐式偏差,即参数在训练过程中会趋向于最大间隔分离器,这为理解Transformer的优化过程提供了新的视角。
🎯 应用场景
该研究成果可应用于提升大型语言模型的检索能力,例如在问答系统、信息检索等领域。通过理解Transformer的检索机制,可以设计更有效的模型架构和训练方法,从而提高模型的准确性和效率。此外,GMC基准测试可以作为评估不同模型架构检索能力的工具。
📄 摘要(原文)
Match-and-copy is a core retrieval primitive used at inference time by large language models to retrieve a matching token from the context then copy its successor. Yet, understanding how this behavior emerges on natural data is challenging because retrieval and memorization are entangled. To disentangle the two, we introduce Gaussian Match-and-Copy (GMC), a minimalist benchmark that isolates long-range retrieval through pure second-order correlation signals. Numerical investigations show that this task retains key qualitative aspects of how Transformers develop match-and-copy circuits in practice, and separates architectures by their retrieval capabilities. We also analyze the optimization dynamics in a simplified attention setting. Although many solutions are a priori possible under a regression objective, including ones that do not implement retrieval, we identify an implicit-bias regime in which gradient descent drives the parameters to diverge while their direction aligns with the max-margin separator, yielding hard match selection. We prove this max-margin alignment for GD trajectories that reach vanishing empirical loss under explicit technical conditions.